System Architecture
This document describes the system architecture of Apache Doris, including the core components and their interaction logic in two deployment modes:
- Integrated storage-compute architecture: The classic FE + BE architecture, where data storage and computation are integrated.
- Decoupled storage-compute architecture: A three-layer separation of metadata, compute, and storage.
Use cases: Architecture selection, architecture learning, and operational understanding.
Integrated Storage-Compute Architecture
The integrated storage-compute architecture is the classic deployment mode of Apache Doris. It consists of two types of processes: Frontend (FE) and Backend (BE).
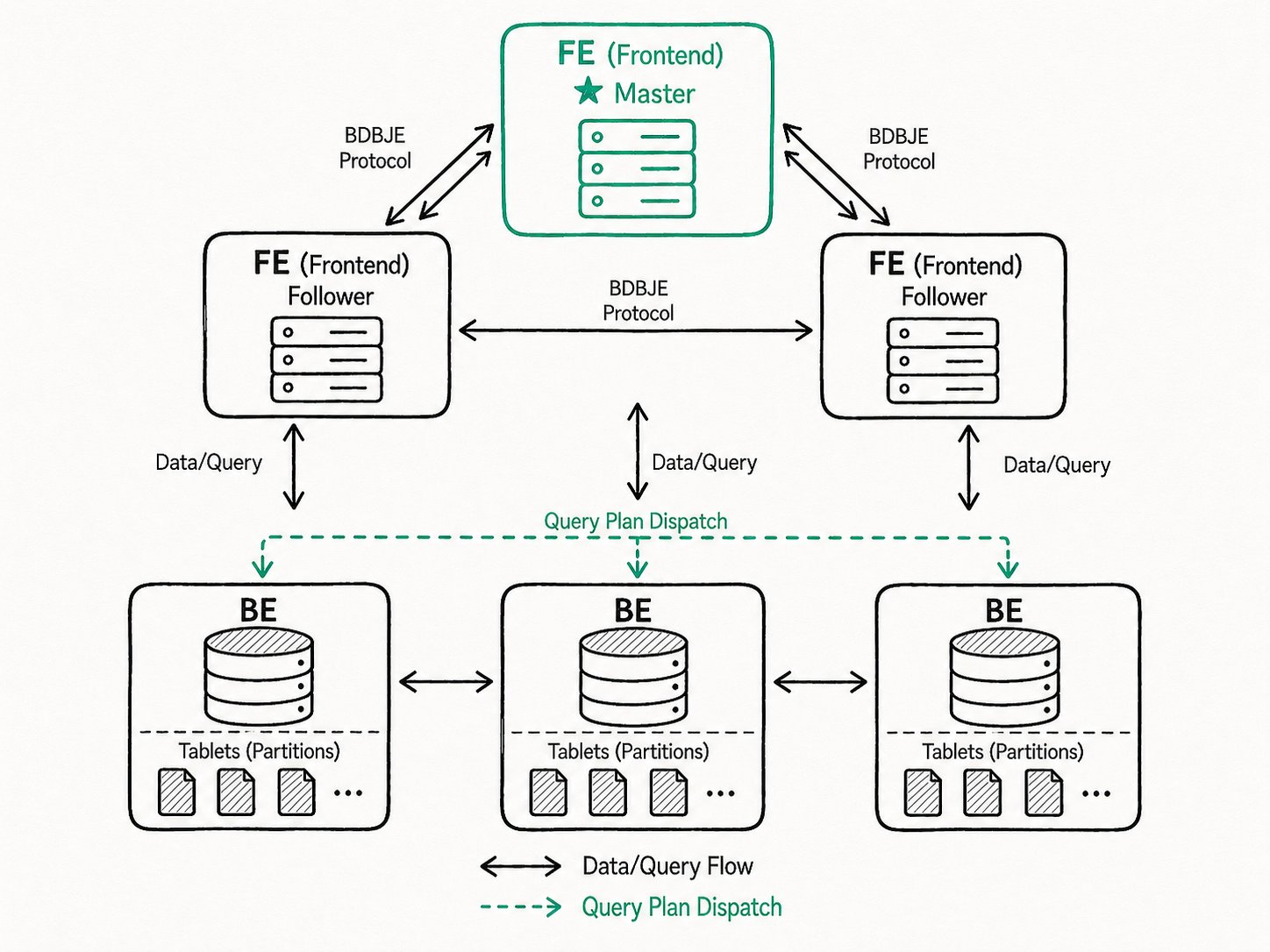
Core Components
Frontend (FE) Node
The FE is the entry node of Apache Doris and handles coordination and control:
| Responsibility | Description |
|---|---|
| User request handling | Compatible with the MySQL protocol and supports standard SQL |
| Query parsing and planning | Lexical analysis -> semantic analysis -> logical plan generation -> CBO optimization -> execution dispatch |
| Metadata management | Database and table schemas, replica distribution, user privileges, cluster topology, and load status |
| Node management | Heartbeat detection, load balancing, replica repair, and scale-out and scale-in management |
The FE uses BDB JE as the metadata storage engine and supports transactional features. It does not depend on external components such as ZooKeeper, which simplifies deployment and maintenance.
Backend (BE) Node
The BE is the compute and storage node:
| Feature | Description |
|---|---|
| Columnar storage | Data is organized by column, combined with encoding and compression to improve I/O efficiency |
| Data sharding (Tablet) | Data is sharded horizontally; the tablet is the smallest unit of replica scheduling |
| Multiple replicas | Each tablet has 3 replicas by default, distributed across different BE nodes |
| Vectorized execution | Columnar memory layout combined with SIMD acceleration delivers 5 to 10x performance on wide-table aggregations |
| Pipeline engine | Multi-core parallelism with thread count limits to prevent thread explosion |
FE High Availability
In production environments, multiple FE nodes are deployed. The role types are as follows:
| Role | Responsibility | Participates in election |
|---|---|---|
| Master | Reads and writes metadata, and synchronizes to Followers and Observers | Yes |
| Follower | Reads metadata and participates in election when the Master fails | Yes |
| Observer | Reads metadata, only extending query concurrency capability | No |
Metadata changes require confirmation from a majority of nodes to ensure consistency.
Architectural Characteristics
- Simple and easy to maintain: Only two types of processes, FE and BE.
- High performance: Compute nodes access local storage directly, with low network overhead.
- High availability: Multiple replicas combined with automatic fault isolation.
- Horizontal scaling: Both FE and BE support online scale-out.
Decoupled Storage-Compute Architecture
Introduced in version 3.0, this architecture fully separates the compute layer from the storage layer, supporting independent elastic scaling.
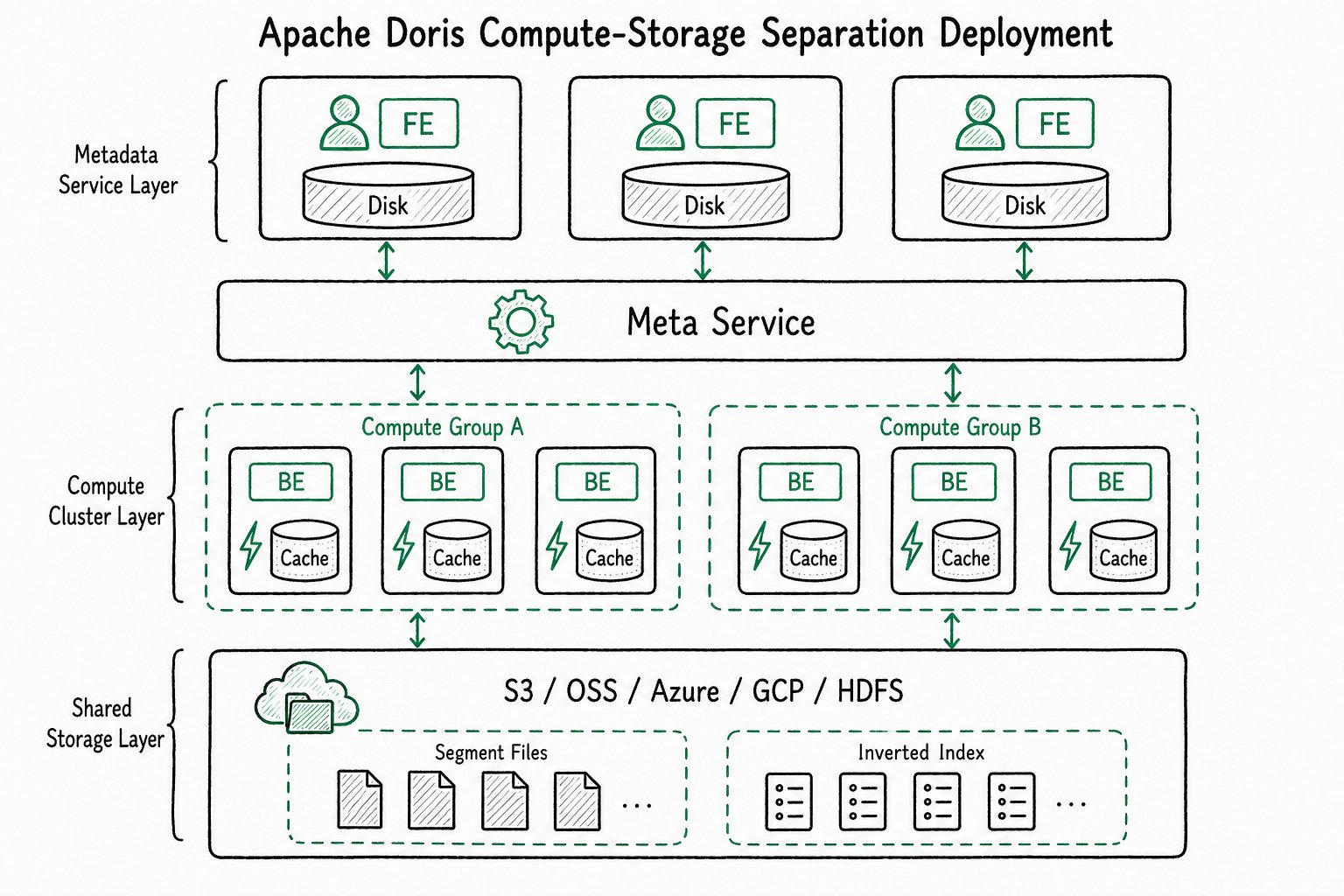
Core Components
In the decoupled storage-compute architecture, the FE node is retained and continues to handle user request entry and query parsing. A new Meta Service is added to manage metadata at the data layer.
FE Frontend Node
The responsibilities of the FE remain unchanged in the decoupled storage-compute architecture:
| Responsibility | Description |
|---|---|
| User request handling | Compatible with the MySQL protocol, supports standard SQL, and handles authentication and privilege validation |
| Query parsing and planning | Lexical analysis -> semantic analysis -> logical plan -> CBO optimization -> execution dispatch |
| SQL-layer metadata | Database and table schemas, user privileges, and cluster topology |
Metadata Layer (Meta Service)
A stateless service that scales horizontally.
| Responsibility | Description |
|---|---|
| Data ingestion transactions | Version management and conflict detection |
| Tablet metadata | Data versions and file lists |
| Rowset metadata | Incremental data information used for recovery and garbage collection |
| Cluster resources | Resource allocation and scheduling for compute groups |
Compute Layer
The compute layer consists of multiple compute clusters, each containing several stateless BE nodes. Compute clusters share the same data but have independent compute resources.
| Feature | Description |
|---|---|
| Independent resources | Each compute cluster serves a different business workload independently |
| Stateless BE | Does not store data persistently; only caches hot data |
| Elastic scaling | Adding or removing nodes does not affect other compute clusters |
| Local cache | Hot data is cached using an LRU policy to reduce access latency |
Shared Storage Layer
The storage layer persists all data files, including segment files and inverted index files.
| Supported type | Examples |
|---|---|
| Object storage | S3, OSS, COS, OBS, MinIO |
| Distributed file system | HDFS |
| Ceph | RGW, CephFS |
Architectural Characteristics
- Elastic compute: Resources scale on demand, suitable for workloads with peaks and troughs.
- Workload isolation: Different business teams share data while keeping compute resources independent.
- Low storage cost: Low-cost options such as object storage are available.
- Minute-level scaling: Compute resources can be adjusted quickly.
Comparison and Selection
Component Function Comparison
The two architectures differ in component responsibilities as follows:
| Comparison item | Integrated storage-compute | Decoupled storage-compute |
|---|---|---|
| FE node | Retained, stores all metadata | Retained, stores only SQL-layer metadata |
| BE node | Stateful (stores data) | Stateless (only caches hot data) |
| Data storage location | BE local disk | Shared storage layer, with BE local disk used as cache |
| Scaling focus | Storage and compute scale together | Compute and storage can scale independently |
| Storage cost | Higher (SSD) | Lower (object storage) |
| Operational complexity | Lower | Higher (depends on external storage) |
| Query latency | Lower (local I/O) | Slightly higher (on cache miss). On cache hit, latency is the same as the integrated storage-compute architecture. |
Selection Guidance
Choose the appropriate architecture based on your scenario:
| Scenario | Integrated storage-compute | Decoupled storage-compute |
|---|---|---|
| Development and test environments, quick experimentation | ✓ | |
| No shared storage available (HDFS / Ceph / object storage) | ✓ | |
| No dedicated DBA, with multiple teams maintaining independently | ✓ | |
| No need for elastic scaling or Kubernetes containerization | ✓ | |
| Already deployed on a public cloud | ✓ | |
| Reliable shared storage system available | ✓ | |
| Kubernetes containerization or private cloud elasticity required | ✓ | |
| Multi-compute-cluster shared data scenarios | ✓ | |
| Dedicated platform team for maintenance | ✓ |
Core Technical Modules
Storage Engine
Columnar storage and compression
Data is organized by column, so only the columns involved in a query are read, reducing I/O. Combined with algorithms such as dictionary encoding, bitmap compression, and RLE, this achieves a high compression ratio.
Index structures
| Index type | Use case |
|---|---|
| Sorted composite key (up to 3 columns) | Pruning for high-concurrency reports |
| Min/Max | Equality and range filtering on numeric types |
| BloomFilter | Equality filtering on high-cardinality columns |
| Inverted index | Fast search and full-text search on arbitrary fields |
Data models
| Model | Characteristics | Use case |
|---|---|---|
| Duplicate model | Retains detailed data | Detail storage for fact tables |
| Primary Key model | Unique primary key; rows with the same primary key are overwritten | Row-level updates |
| Aggregate model | Rows with the same primary key are aggregated automatically | Pre-aggregation acceleration |
Query Engine
MPP distributed queries
Complex queries are decomposed into multiple stages and processed in parallel across multiple BE nodes. Distributed shuffle joins are supported to handle joins on large tables efficiently.
Vectorized execution
A columnar memory layout combined with SIMD instructions delivers 5 to 10x performance on wide-table aggregations.
Pipeline execution engine
Multi-core parallelism with thread count limits prevents thread explosion. Data copies and memory allocation overhead between operators are reduced.
Query optimizer
| Optimizer | Strategy |
|---|---|
| RBO | Constant folding, subquery rewriting, and predicate pushdown |
| CBO | Cost estimation and join reordering |
| HBO | Uses historical queries to accelerate repeated queries |
Runtime Filter
Filters are generated dynamically at runtime and pushed down to scan nodes to reduce the amount of data processed. Supported types include In, Min/Max, and BloomFilter.
High Availability Mechanism
Multiple replicas and the quorum protocol
- 3 replicas are stored by default.
- A write must be confirmed by a majority (such as 2 replicas) to succeed.
- Partial node failures do not lead to data loss, and the cluster remains available.
Automatic fault isolation
- Detect node heartbeat timeouts or replica corruption.
- Mark the node as unavailable and stop dispatching tasks to it.
- Automatically rebuild missing replicas from healthy replicas.
- After recovery, automatically synchronize incremental data.
FE high availability
A Paxos-like consensus protocol ensures metadata consistency. When the Master fails, Followers automatically elect a new Master, transparent to the user.
FAQ
Q: What is the core difference between the integrated and decoupled storage-compute architectures?
In the integrated storage-compute architecture, BE nodes handle both data storage and computation, and data is stored on local disks. In the decoupled storage-compute architecture, data is stored in a shared storage layer (such as S3 or HDFS), and BE nodes act as stateless compute nodes that accelerate queries through a local cache. The decoupled architecture supports independent elastic scaling of compute and storage resources.
Q: When should you choose the decoupled storage-compute architecture?
The decoupled storage-compute architecture is suitable for the following scenarios: existing public cloud deployments, Kubernetes containerization requirements, the availability of a reliable shared storage system (HDFS, Ceph, or object storage), the need for multiple compute clusters to share data, and a dedicated platform team for maintenance. For simple use cases or development and test environments, the integrated storage-compute architecture is more suitable.
Q: Do BE nodes store data in the decoupled storage-compute architecture?
In the decoupled storage-compute architecture, BE nodes are stateless and do not persist data themselves. However, BE nodes use a local SSD to cache hot data (with an LRU eviction policy) to overcome the latency caused by the relatively poor random read performance of object storage and the network transfer overhead.
Q: What is the role of the FE in the decoupled storage-compute architecture?
The FE is retained in the decoupled storage-compute architecture and is mainly responsible for user request entry, SQL parsing and planning, and SQL-layer metadata management (database and table schemas, user privileges, and cluster topology). Metadata management at the data layer (such as tablet metadata and rowset metadata) is handled by the newly added Meta Service.
Q: How is high availability implemented in Doris?
Doris implements high availability through multiple replicas and a quorum protocol: each tablet has 3 replicas by default, and a write must be confirmed by a majority. When some nodes fail, they are automatically isolated and replicas are rebuilt from healthy replicas. The FE uses a Paxos-like consensus protocol to ensure metadata consistency, and a new Master is automatically elected when the current Master fails.
Q: What is the role of Meta Service in the decoupled storage-compute architecture?
Meta Service is a stateless service in the decoupled storage-compute architecture that is dedicated to managing metadata at the data layer. Its responsibilities include data ingestion transaction processing (version management and conflict detection), tablet and rowset metadata management, and resource allocation and scheduling for compute clusters. Because it is stateless, it scales horizontally to improve metadata processing capacity.
Summary
Apache Doris provides two architectures to fit different needs:
| Architecture | Use case |
|---|---|
| Integrated storage-compute | Performance-first, limited operational resources, and manageable scale |
| Decoupled storage-compute | Cloud-native, elastic scaling, and shared data across multiple teams |
Both architectures provide a complete high availability mechanism to ensure data reliability and service stability.