Optimizations Behind the Performance Tests
Overview
Apache Doris has evolved from inverted text retrieval in 2.x, to storage-compute separation in 3.x, and now to vector indexing capabilities in 4.x, formally entering the era of AI data analytics. This article is intended for the following readers:
- Architects and developers who want to understand why Doris 4.x vector indexing reaches an industry-leading level.
- Technical decision-makers evaluating vector databases who need to understand where the performance differences between Doris and dedicated vector databases come from.
- Operations and performance engineers who plan to tune ANN search on Doris.
The article is organized around the two main phases of vector retrieval:
| Phase | Core goal | Main optimizations |
|---|---|---|
| Indexing phase | Speed up index construction without sacrificing quality | Multi-level sharding, two-tier parallelism, SIMD distance computation |
| Query phase | Control P99 latency under high concurrency | Prepare Statement, Index Only Scan, virtual columns, Scan parallelism, global TopN late materialization |
Indexing Phase
The performance of the indexing phase is strongly correlated with the index hyperparameters: the higher the quality, the slower the build. Doris optimizes the data ingestion path to significantly improve ingestion throughput while maintaining high index quality.
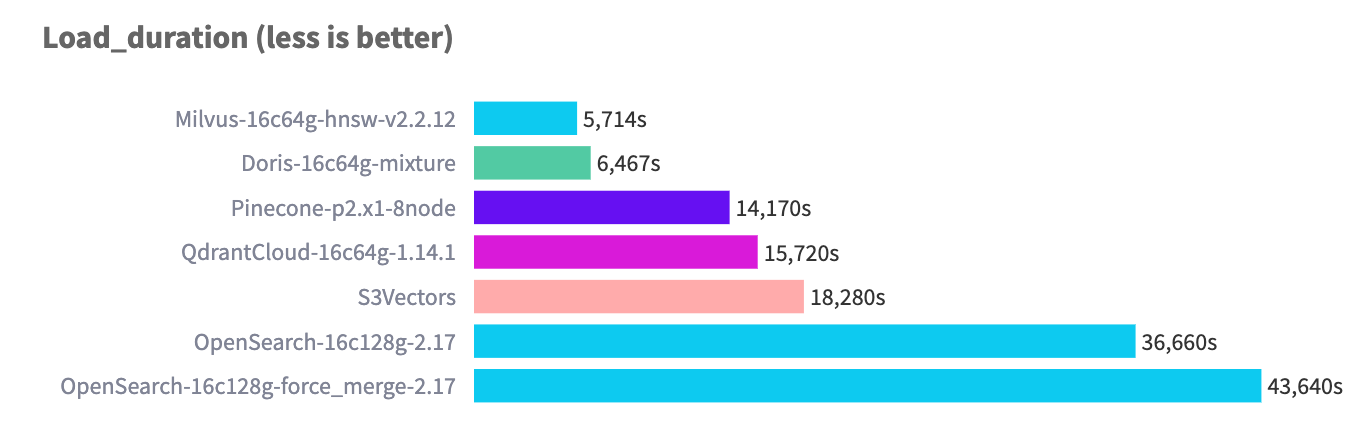
At a scale of 768 dimensions and 10M rows, Doris ingestion performance reaches an industry-leading level:
Multi-level Sharding
Doris internal tables are inherently distributed. Users only perceive a single logical table (Table) when querying or ingesting, while the Doris kernel automatically creates physical shards according to the table definition and routes data to the corresponding tablets on BEs based on the partition key and bucket key.
The relationships between the levels are as follows:
| Level | Role |
|---|---|
| Table | The logical table perceived by the user |
| Tablet | A physical shard that meets the quantity requirement |
| Rowset | The version control unit produced by each ingestion transaction on a tablet |
| Segment | The file under a rowset that actually carries the data. The ANN index operates at segment granularity |
Vector indexes (such as HNSW) depend on several key hyperparameters. These parameters directly determine index quality and query performance, and typically reach ideal results only at a fixed data scale.
Doris's multi-level sharding decouples "index parameters" from "the total data scale of the table": users do not need to rebuild the index because the total data volume grows. They only need to focus on the size of each ingestion batch and the corresponding parameter settings.
Based on measurements, the empirical parameters for the HNSW index at different batch sizes are as follows:
| batch_size | max_degree | ef_construction | ef_search | recall@100 |
|---|---|---|---|---|
| 250000 | 100 | 200 | 50 | 89% |
| 250000 | 100 | 200 | 100 | 93% |
| 250000 | 100 | 200 | 150 | 95% |
| 250000 | 100 | 200 | 200 | 98% |
| 500000 | 120 | 240 | 50 | 91% |
| 500000 | 120 | 240 | 100 | 94% |
| 500000 | 120 | 240 | 150 | 96% |
| 500000 | 120 | 240 | 200 | 99% |
| 1000000 | 150 | 300 | 50 | 90% |
| 1000000 | 150 | 300 | 100 | 93% |
| 1000000 | 150 | 300 | 150 | 96% |
| 1000000 | 150 | 300 | 200 | 98% |
In other words, users only need to focus on "the data volume of each ingestion batch" and choose the appropriate index parameters accordingly to obtain stable query performance while ensuring index quality.
High-performance Index Construction
Parallel High-quality Index Construction
Doris uses "two-tier parallelism" to accelerate index construction:
- Cluster-level parallelism: building in parallel across multiple BE nodes.
- Intra-node parallelism: within each BE, performing multi-threaded distance computation on grouped data from the same batch to speed up the construction of the index data structure.
While being fast, Doris improves index quality through in-memory batching: when the total number of vectors is fixed but batches are too small and the index is appended to too frequently, the graph structure tends to become sparse and recall drops.
For example, for 768D / 10M vector data:
- Building the index in 10 batches yields a recall of about 99%.
- Building the index in 100 batches may drop recall to about 95%.
Through in-memory batching, Doris can better balance memory usage and graph quality under the same hyperparameters, avoiding quality degradation caused by over-batching.
SIMD Distance Computation
The core cost of ANN index construction lies in large-scale distance computation, a typical CPU-intensive task. Doris concentrates this computation on BE nodes. The relevant implementation is written in C++ and makes full use of Faiss's automatic and manual vectorization optimizations.
Take L2 distance as an example. Faiss triggers automatic vectorization through compiler-directive macros:
FAISS_PRAGMA_IMPRECISE_FUNCTION_BEGIN
float fvec_L2sqr(const float* x, const float* y, size_t d) {
size_t i;
float res = 0;
FAISS_PRAGMA_IMPRECISE_LOOP
for (i = 0; i < d; i++) {
const float tmp = x[i] - y[i];
res += tmp * tmp;
}
return res;
}
FAISS_PRAGMA_IMPRECISE_FUNCTION_END
The FAISS_PRAGMA_IMPRECISE_* macros guide the compiler to perform automatic vectorization:
#define FAISS_PRAGMA_IMPRECISE_LOOP \
_Pragma("clang loop vectorize(enable) interleave(enable)")
At the same time, Faiss uses _mm* / _mm256* / _mm512* instructions inside #ifdef SSE3/AVX2/AVX512F conditional blocks to perform explicit vectorization. Combined with the templates ElementOpL2 / ElementOpIP (which implement element-wise operations for L2 and dot product respectively) and the dimension specializations fvec_op_ny_D{1,2,4,8,12}, this achieves:
- Batch processing of multiple samples (such as 8 or 16), with in-register matrix transposes (such as
transpose_8x2/16x4/...) to improve access locality. - FMA instructions (such as
_mm512_fmadd_ps) that fuse multiply-add to reduce the number of instructions. - Horizontal sum to quickly produce a scalar result.
- Masked branches to handle tail elements that are not aligned to 4/8/16.
These optimizations effectively compress the instruction and memory-access overhead of distance computation, significantly improving index construction throughput.
Query Phase
Search scenarios are extremely sensitive to latency. With tens of millions of rows of data and high-concurrency queries, P99 latency typically needs to be kept under 500 ms. This places higher demands on the Doris optimizer, execution engine, and index implementation.
Out-of-the-box tests show that Doris query performance has reached the level of mainstream dedicated vector databases in the industry. The figure below compares Doris with other databases that have vector search capabilities on the Performance768D10M dataset. The data for the other databases comes from Zilliz's open-source VectorDBBench framework:
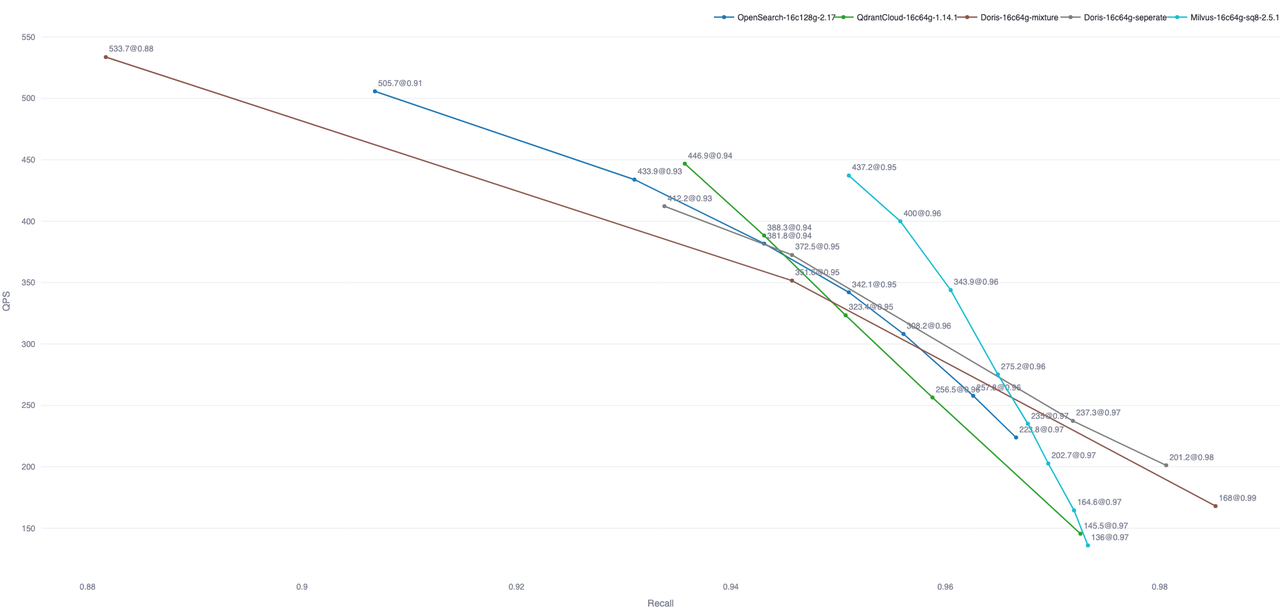
Note: The figure includes only the out-of-the-box test results for some databases. OpenSearch and Elastic Cloud can further improve query performance by optimizing the number of index files.
The optimizations in the query phase revolve around one core goal: eliminate redundant computation and unnecessary disk IO, and maximize concurrent performance. The specific techniques are as follows:
Prepare Statement
In the traditional execution path, Doris runs the full optimization flow (syntax parsing, semantic analysis, RBO, CBO) for every SQL statement. This is essential in general OLAP scenarios, but in simple and highly repetitive query patterns such as search, it produces noticeable extra overhead.
Doris 4.0 extends Prepare Statement so that it supports not only point queries but also all SQL types, including those involving vector search. The core ideas are:
- Separate compilation and execution
- The Prepare phase performs parsing, semantic analysis, and optimization once and produces a reusable Logical Plan.
- The Execute phase only binds actual parameters and directly executes the generated plan, completely skipping the optimizer.
- Plan Cache
- Whether a plan can be reused is decided by SQL fingerprint (normalized SQL + schema version).
- When the parameter values differ but the structure is the same, the plan can still be reused directly, avoiding repeated optimization.
- Schema Version Validation
- The table schema version is checked at execution time to ensure plan correctness.
- When the schema has not changed, the plan is reused directly. When it has changed, the plan is automatically invalidated and re-prepared.
- Skipping the optimizer brings significant speedup
- Execute no longer runs RBO/CBO, and the optimizer's time cost is almost entirely eliminated.
- For templated queries such as vector search, Prepare can significantly reduce end-to-end latency.
Index Only Scan
Doris's vector index is implemented as an attached index. Attached indexes are easy to manage and to build asynchronously, but they also bring performance challenges: how to avoid redundant computation and unnecessary IO.
In addition to returning matching row IDs, the ANN index can also return inter-vector distances. To efficiently use this extra information, the execution engine performs an "early short-circuit" on distance-related expressions in the Scan operator. Doris automatically performs this short-circuit through the "virtual column" mechanism and uses Ann Index Only Scan to completely eliminate the read IO related to distance computation.
Naive flow: Scan pushes the predicate down to the index, the index returns row IDs, Scan reads the data pages by row ID, then computes the expression and returns N rows of results upward.
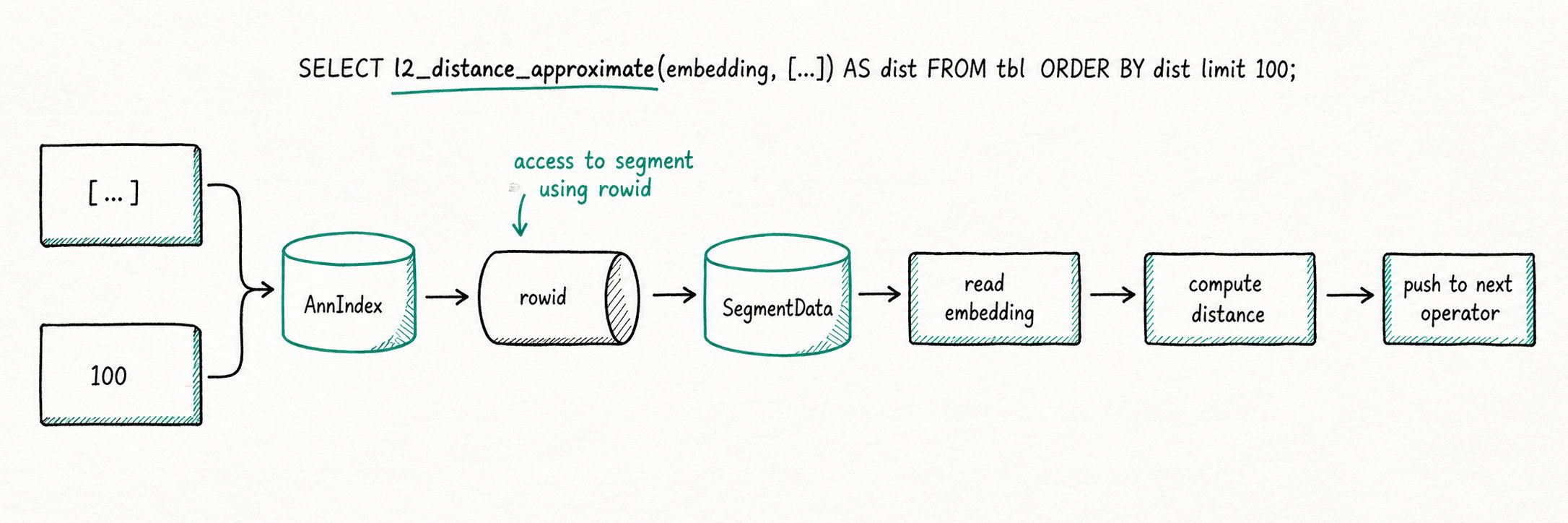
With Index Only Scan applied:
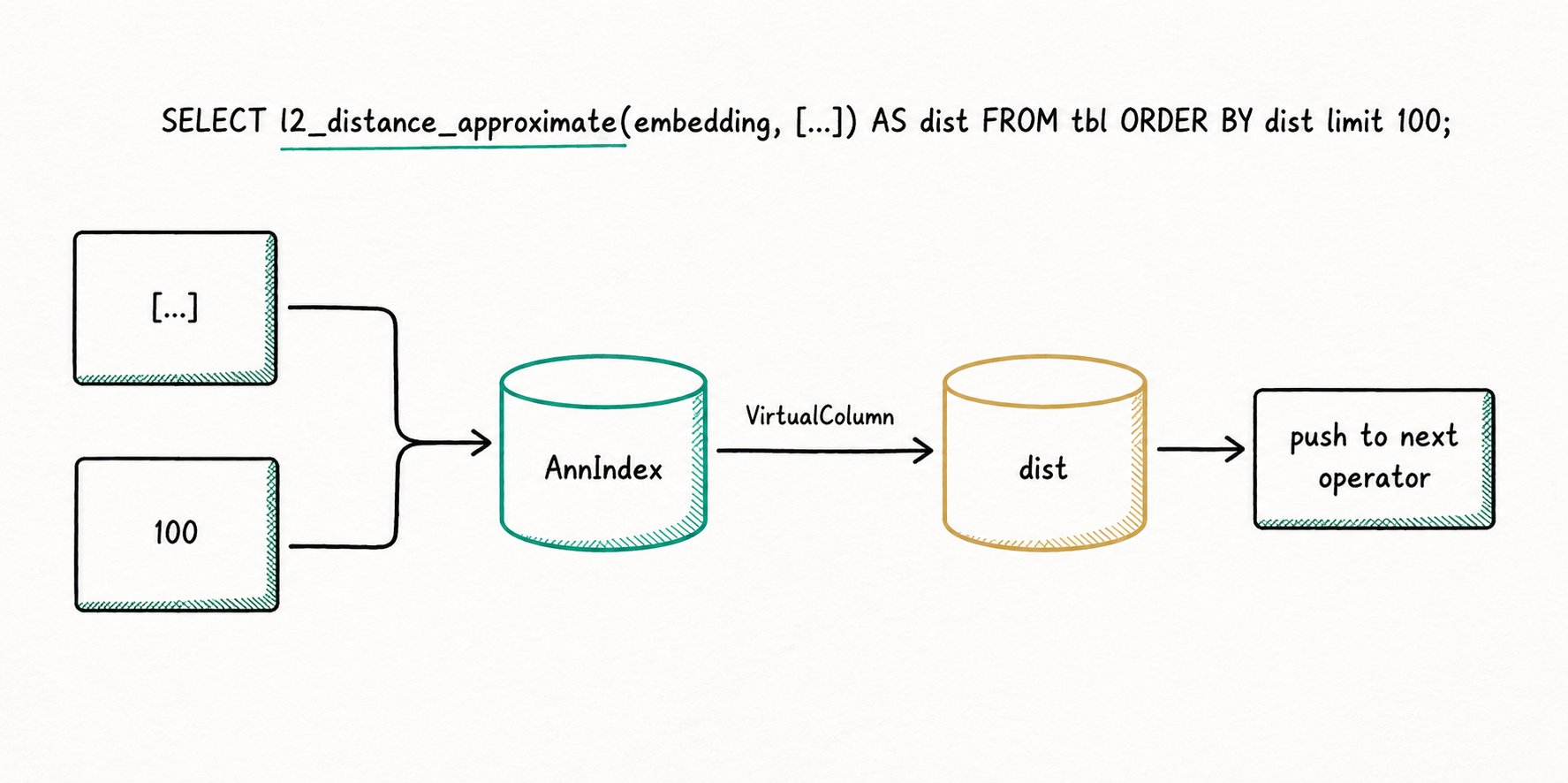
For example:
SELECT l2_distance_approximate(embedding, [...]) AS dist
FROM tbl
ORDER BY dist
LIMIT 100;
The execution process no longer triggers data file IO.
Query Types Supported by Index Only Scan
In addition to Ann TopN Search, Range Search and Compound Search that support index acceleration also use similar optimizations. Range Search is more complex than TopN: different comparison methods determine whether the index can return dist. The table below summarizes the query types related to Ann Index Only Scan:
| No. | Pattern | Uses IndexScan | Key reason |
|---|---|---|---|
| Sql1 | Range + proj, dist <= 10 | True | The index can return dist, and virtual column for cse avoids recomputing dist in proj |
| Sql2 | Range + no-proj, dist <= 10 | True | The index can return dist |
| Sql3 | Range + proj, dist > 10 | False | The index cannot return dist, and proj requires dist, so embedding must be re-read |
| Sql4 | Range + proj, dist > 10, proj does not need dist | True | proj does not need dist, so embedding does not need to be re-read |
| Sql5 | TopN | True | The index returns dist, and the virtual slot is passed up to proj |
| Sql6 | TopN + IndexFilter | True | The comment column is already optimized by the inverted index scan, and embedding is not read |
| Sql7 | TopN + Range | True | A combination of Sql1 and Sql5 |
| Sql8 | TopN + Range + IndexFilter | True | A combination of Sql6 and Sql7 |
| Sql9 | TopN + Range + CommonFilter (dist < 10) | False | The residual common filter causes embedding to still be materialized (low ROI, not optimized for now) |
| Sql10 | A variant of Sql9 (dist > 10) | False | The index cannot return embedding, so it must be materialized to compute abs |
| Sql11 | A variant of Sql9 (array_size(embedding) > 10) | False | array_size forces embedding to be materialized |
The complete SQL with detailed comments is as follows:
-- Sql1
-- Range + proj
-- The Ann index can return dist, so dist does not need to be computed again.
-- At the same time, virtual column for cse avoids the dist computation in proj.
-- IndexScan: True
select id, dist(embedding, [...]) from tbl where dist <= 10;
-- Sql2
-- Range + no-proj
-- The Ann index can return dist, so dist does not need to be computed again.
-- IndexScan: True
select id from tbl where dist <= 10 order by id limit N;
-- Sql3
-- Range + proj + no-dist-from index
-- The Ann index cannot return dist (the index can only update the rowid map).
-- Since proj requires dist to be returned, embedding must be re-read.
-- IndexScan: False
select id, dist(embedding, [...]) from tbl where dist > 10;
-- Sql4
-- Range + proj + no-dist-from index
-- The Ann index cannot return dist (the index can only update the rowid map).
-- However, proj does not need dist, so embedding does not need to be re-read.
-- IndexScan: True
select id from tbl where dist > 10;
-- Sql5
-- TopN
-- AnnIndex returns dist, and virtual slot for cse ensures that the dist from the index is passed up to proj,
-- so the embedding column does not need to be read.
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl order by dist(embedding, [...]) asc limit N;
-- Sql6
-- TopN + IndexFilter
-- 1. The comment column does not need to be read; the inverted index scan has already done this optimization.
-- 2. The embedding column does not need to be read, for the same reason as Sql5.
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql7
-- TopN + Range
-- IndexScan: True, because this is a combination of Sql1 and Sql5.
select id[, dist(embedding, [...])] from tbl where dist(embedding, [...]) > 10 order by dist(embedding, [...]) limit N;
-- Sql8
-- TopN + Range + IndexFilter
-- IndexScan: True, because this is a combination of Sql7 and Sql6.
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql9
-- TopN + Range + CommonFilter
-- The key points here: 1. dist < 10, not dist > 10; 2. the common filter does not read embedding directly, but reads dist.
-- The Ann index can return dist, and virtual slot ref for cse ensures that all reads of dist refer to the same column.
-- In this case, although Ann TopN cannot be applied, in theory the embedding column does not need to be materialized at any point.
-- However, in practice, embedding is still materialized, because whether a column can skip reading is currently judged by whether predicates on this column still have residuals;
-- the common filter itself cannot be eliminated, so the current code still considers it necessary to materialize the column.
-- The ROI of this optimization is low, so it is not done.
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) < 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql10
-- A variant of Sql9: dist < 10 becomes dist > 10. In this case the index cannot return embedding,
-- so embedding must be materialized in order to compute abs(dist(embedding, [...])).
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql11
-- A variant of Sql9: abs(dist(embedding) + 10) > 10 becomes array_size(embedding) > 10. The difference is that array_size forces embedding to be materialized.
-- To compute array_size(embedding, [...]), embedding must be materialized.
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) < 10 AND array_size(embedding) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
Virtual Columns for Common Subexpression Optimization
Index Only Scan mainly addresses the IO problem and avoids large amounts of random reads on embedding. To further eliminate redundant computation, Doris introduces a "virtual column" mechanism at the compute layer, which passes the dist returned by the index as a column to the expression executor.
Key design points of virtual columns:
- The expression node
VirtualSlotRefis introduced to represent a special "computed at runtime" column that is materialized by some expression and can be shared by multiple expressions. It is computed only once on first use, eliminating common subexpression (CSE) duplication between Projection and predicates. - The column iterator
VirtualColumnIteratoris introduced to materialize the distances returned by the index into expressions, avoiding redundant distance function computations.
This mechanism was originally used for CSE elimination in ANN-related queries and was later extended to general Projection + Scan + Filter combinations.
Measured Results
Based on the ClickBench dataset, count the top 20 websites with the most clicks coming from Google:
set experimental_enable_virtual_slot_for_cse=true;
SELECT counterid,
COUNT(*) AS hit_count,
COUNT(DISTINCT userid) AS unique_users
FROM hits
WHERE ( UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.COM'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.RU'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) LIKE '%GOOGLE%' )
AND ( LENGTH(regexp_extract(referer, '^https?://([^/]+)', 1)) > 3
OR regexp_extract(referer, '^https?://([^/]+)', 1) != ''
OR regexp_extract(referer, '^https?://([^/]+)', 1) IS NOT NULL )
AND eventdate = '2013-07-15'
GROUP BY counterid
HAVING hit_count > 100
ORDER BY hit_count DESC
LIMIT 20;
The core expression regexp_extract(referer, '^https?://([^/]+)', 1) is CPU-intensive and is reused in multiple places. The comparison with the virtual column optimization on and off:
| State | Time |
|---|---|
| Optimization off | 1.50 s |
Optimization on (set experimental_enable_virtual_slot_for_cse=true) | 0.57 s |
End-to-end performance improves by about 3x.
Scan Parallelism Optimization
Doris has redesigned the Scan parallelism strategy specifically for Ann TopN Search.
| Dimension | Old strategy | New strategy |
|---|---|---|
| Basis for parallelism | Number of rows (default 2,097,152 rows / Scan Task) | Strictly create one Scan Task per segment |
| Behavior in high-dimensional vector scenarios | The number of rows in a single segment is far below the threshold, and multiple segments are scanned serially | Parallelism is increased during the index analysis phase |
| Impact of looking up the table | - | Ann TopN has a high filter rate, so serial table lookup does not affect overall performance |
Take SIFT 1M as an example: after enabling set optimize_index_scan_parallelism=true;, the time of a serial TopN query drops from 230 ms to 50 ms.
In addition, 4.0 introduces "dynamic parallelism adjustment": before each scheduling round, the number of tasks that can be submitted is dynamically determined based on the pressure on the Scan thread pool. When the pressure is high, parallelism is reduced; when resources are idle, parallelism is increased, balancing resource utilization and scheduling overhead between serial and high-concurrency scenarios.
Global TopN Late Materialization
A typical Ann TopN query consists of two phases:
- Phase one: the Scan operator obtains the TopN distances of each segment through the index.
- Phase two: the global sort node merges and sorts the per-segment TopN to obtain the final TopN.
If the projection returns multiple columns or contains large columns (such as String), the N rows read from each segment in phase one may cause a large amount of disk IO and may be discarded during the global sort in phase two (because they are not in the final TopN). Doris uses "global TopN late materialization" to minimize the read volume in phase one.
Take the following example:
SELECT id, l2_distance_approximate(embedding, [...]) AS dist
FROM tbl
ORDER BY dist
LIMIT 100;
Execution flow:
- Phase one: each segment uses Ann Index Only Scan + virtual column to output only 100
distvalues and theirrowids. - Phase two: if there are M segments in total, perform a global sort on the
100 * Mdistvalues to obtain the final TopN and theirrowids. - Finally, the Materialize operator materializes the required columns on the corresponding tablet/rowset/segment based on these
rowids.