
Compaction Principles
1. The Role of Compaction
Apache Doris uses an LSM-Tree based storage engine where data is appended sequentially to new data files during writes, rather than directly updating existing files. This design ensures high write performance, but over time, data files of different versions and sizes accumulate, leading to the following issues:
- Query performance degradation: Queries require multi-way merge sorting across multiple files
- Storage space waste: Contains data marked for deletion or duplicate data
Compaction (data compression and organization) is the key mechanism to solve these problems. It automatically merges and rewrites data files in the background, aggregating data with the same primary key or adjacent ranges into fewer, more ordered files, and cleans up deleted or expired data. This maintains high query performance while optimizing storage space utilization.
In Doris, Compaction is a continuous and automatic process that doesn't require manual triggering. However, understanding its principles and operational status helps with performance tuning in high-concurrency and big data scenarios.
1.1 Improving Query Performance
Doris's data import mechanism: Each import generates a rowset for each tablet in the target partition.
- Each rowset contains 0 to n segments
- Each segment corresponds to an ordered file on disk
During queries, the storage layer needs to return aggregated or deduplicated results, so it performs multi-way merge sorting on data from multiple rowsets/segments. As the number of rowsets increases, the number of merge paths also increases, leading to decreased query efficiency.
Compaction's role:
- BE nodes continuously merge these rowsets in the background, reducing the number of merge paths, thereby improving query efficiency
- Compaction is executed at the tablet granularity
1.2 Data Cleaning
In addition to performance improvement, Compaction also handles data cleaning responsibilities:
- Cleaning marked-for-deletion data
- Doris DELETE operations don't immediately delete data; instead, they generate a delete rowset (containing only delete predicates, not actual data). During Compaction, data matching these predicates is filtered and actually deleted
- For Merge-on-Write type tables, data marked with delete signs is also cleaned during the Compaction phase
- Removing duplicate data
- Aggregate model: Aggregates rows with the same key
- Unique model: Only keeps the latest data for the same key
This ensures both data correctness and reduces storage space usage.
2. Key Concepts
2.1 Compaction Score
Compaction Score is an indicator that measures the degree of data disorder in a tablet, and it's also the basis for determining Compaction priority. It's equivalent to the number of merge paths that the tablet needs to participate in during query execution.
- Higher Score means higher query overhead
- Therefore, Compaction prioritizes tablets with higher Scores
Example:
"rowsets": [
"[0-100] 3 DATA NONOVERLAPPING 0200000000001c30804822f519cf378fbe6f162b7de393a6 500.32 MB",
"[101-101] 2 DATA OVERLAPPING 02000000000021d0804822f519cf378fbe6f162b7de393a6 180.46 MB",
"[102-102] 1 DATA NONOVERLAPPING 0200000000002211804822f519cf378fbe6f162b7de393a6 50.59 MB"
]
- The [0-100] rowset has 3 segments but no overlap → occupies 1 path
- The [101-101] rowset has 2 segments with overlap → occupies 2 paths
- The [102-102] rowset occupies 1 path Therefore, this tablet's Compaction Score = 4.
2.2 Compaction Types
- Cumulative Compaction: Merges small incremental rowsets to improve merge efficiency
- Base Compaction: Merges all rowsets before a certain rowset into a new rowset
- Full Compaction: Merges all rowsets
- Cumulative Point: The boundary point that divides Base and Cumulative Compaction
The ideal strategy is: First merge small rowsets through Cumulative Compaction, and after accumulating to a certain scale, perform Base Compaction.
3. Compaction Strategy
3.1 Tablet Selection Strategy
Since Compaction's goal is to improve query performance, it prioritizes tablets with the highest Compaction Score.
3.2 Rowset Selection Strategy
After identifying the target tablet, appropriate rowsets need to be selected for Compaction. The principles are:
- Reduce Compaction Score as much as possible while minimizing computational load
- Control write amplification ratio
- Avoid occupying excessive system resources
Main considerations:
- Cost-effectiveness
- Cumulative Compaction: The sizes of rowsets participating in the merge shouldn't differ too much; the largest rowset size ≤ half of the total
- Base Compaction: Only triggers when the ratio of Base rowset to other candidate rowsets ≥ 0.3
- Write amplification control
- Cumulative Compaction:
- Only triggers when candidate rowset Score > 5
- Only triggers when data volume exceeds promotion size
- Base Compaction: Only triggers when candidate rowset Score > 5
- Cumulative Compaction:
- System resource control
- Number of rowsets in a single Cumulative Compaction ≤ 1000
- Number of rowsets in a single Base Compaction ≤ 20
4. Compaction Process
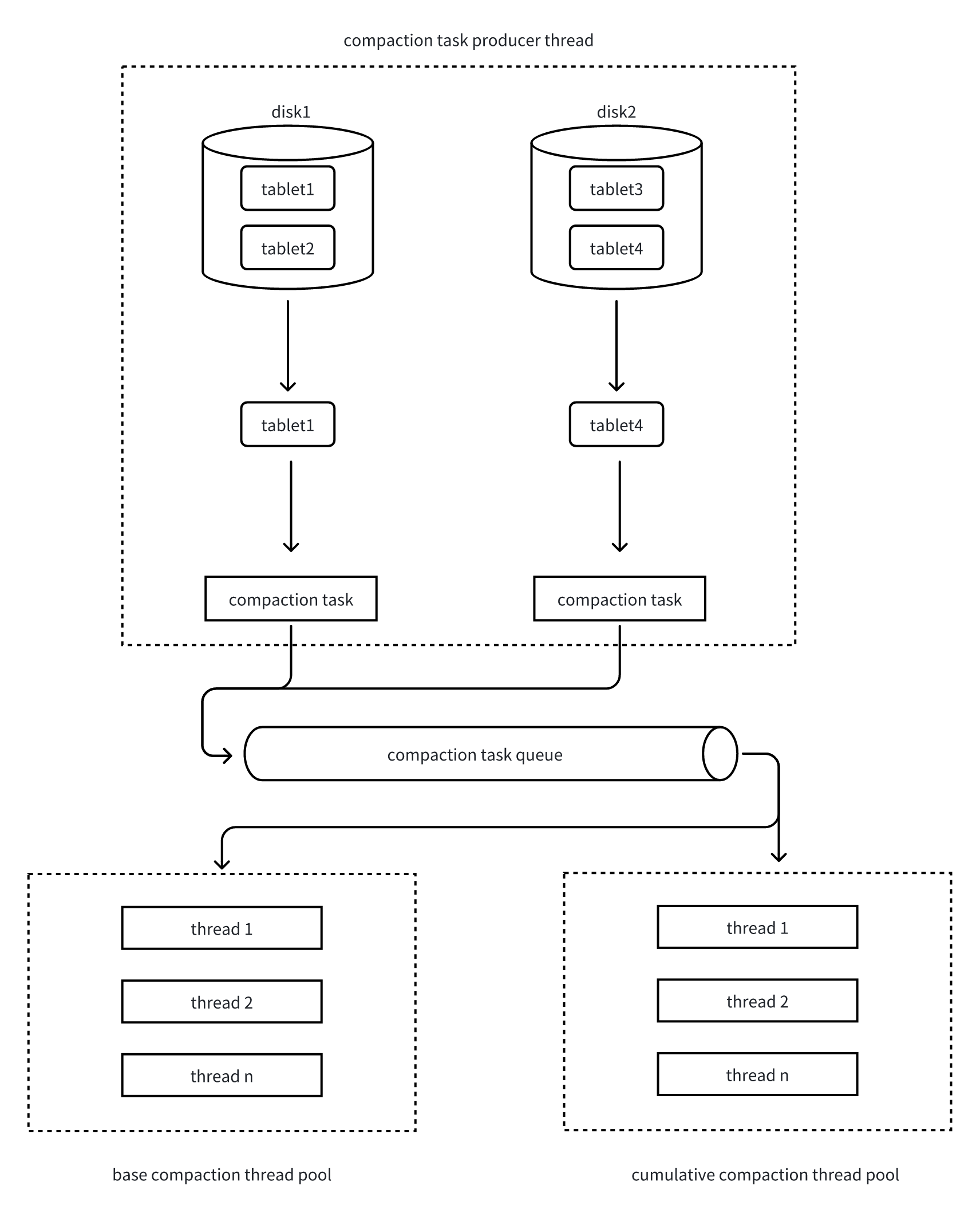
Compaction execution follows a producer-consumer model:
- Tablet scanning and task generation
- Compaction task producer threads periodically scan all tablets and calculate their Compaction Scores
- Each round selects the tablet with the highest Score from each disk
- Base Compaction is selected every 10 rounds, with the other 9 rounds being Cumulative Compaction
- Concurrency control
- Check if the current disk's Compaction task count exceeds the configured limit
- If not exceeded, allow the tablet to enter Compaction
- Rowset selection
- Select continuous rowsets with similar sizes as input
- Avoid inefficient multi-way merges due to significant data volume disparities
- Task submission
- Package the tablet and candidate rowsets into a Compaction Task
- Submit to the corresponding thread pool queue based on task type (Base/Cumulative)
- Task execution
- Compaction thread pool retrieves tasks from the queue
- Execute multi-way merge sorting, merging multiple rowsets into a new rowset
5. Common Compaction Parameters
| Parameter Name | Meaning | Default Value |
|---|---|---|
| tive_compaction_rounds_for_each_base_compaction_round | How many rounds of cumulative compaction tasks are generated before one base compaction task is generated. Adjusting this parameter can control the ratio between cumulative and base compaction tasks | 9 |
| compaction_task_num_per_fast_disk | Maximum number of concurrent compaction tasks per SSD disk | 8 |
| compaction_task_num_per_disk | Maximum number of concurrent compaction tasks per HDD disk | 4 |
| max_base_compaction_threads | Number of worker threads in the Base compaction thread pool | 4 |
| max_cumu_compaction_threads | Number of worker threads in the Cumulative compaction thread pool. -1 means the thread pool size is determined by the number of disks, with one thread per disk | -1 |
| base_compaction_min_rowset_num | Condition for triggering base compaction. When triggered by rowset count, this is the minimum number of rowsets required for base compaction | 5 |
| base_compaction_max_compaction_score | Maximum compaction score for rowsets participating in a base compaction | 20 |
| cumulative_compaction_min_deltas | Minimum compaction score for rowsets participating in a cumulative compaction | 5 |
| cumulative_compaction_max_deltas | Maximum compaction score for rowsets participating in a cumulative compaction | 1000 |