
Workload Group Bind Compute Group
Background
Doris supports logical partitioning of BE (Backend) resources within a cluster through the Compute Group feature, forming independent sub-cluster units to achieve physical isolation of computing and storage resources for different business parties. Due to the significant differences in load characteristics among business parties, their configuration requirements for Workload Groups often exhibit obvious distinctions.
In early versions, the Workload Groups configured by users would take effect globally across all Compute Groups, forcing different business parties to share the same set of Workload Group configurations. For example, Business A’s high-concurrency queries and Business B’s large-scale data analysis might require completely different resource quotas, but the old architecture could not meet such differentiated needs, limiting the flexibility of resource management.
To address this, the latest version introduces a mechanism for binding Workload Groups to Compute Groups, allowing each Compute Group to be configured with independent Workload Groups.
Compute Group Introduction
The Compute Group, initially serving as a core concept under the storage-computation separation architecture, is designed to achieve logical partitioning of independent sub-clusters within a single cluster. In the storage-computation integration architecture, the concept with equivalent functionality is called the Resource Group. Both can realize the isolation and grouped management of cluster resources.
When discussing Doris' computational resource management system, Compute Group and Resource Group can be regarded as logically equivalent concepts, an understanding that significantly reduces comprehension costs. At the specific interface invocation level, however, both still maintain their original independent invocation specifications and usage logic unchanged.
Therefore, the concept and usage of binding Workload Groups to Compute Groups mentioned in this article are applicable to both the storage-computation integration architecture and the storage-computation separation architecture.
Introduction to Principles
Suppose there are two Compute Groups in the cluster, named Compute Group A and Compute Group B, which serve business party A and business party B respectively, and the two business systems operate completely independently.
At the same time, two Workload Groups are configured in the cluster: group_a created by Business A and group_b created by Business B. The sum of the resource configuration quotas of the two groups exactly fills 100% of the cluster's total resources.
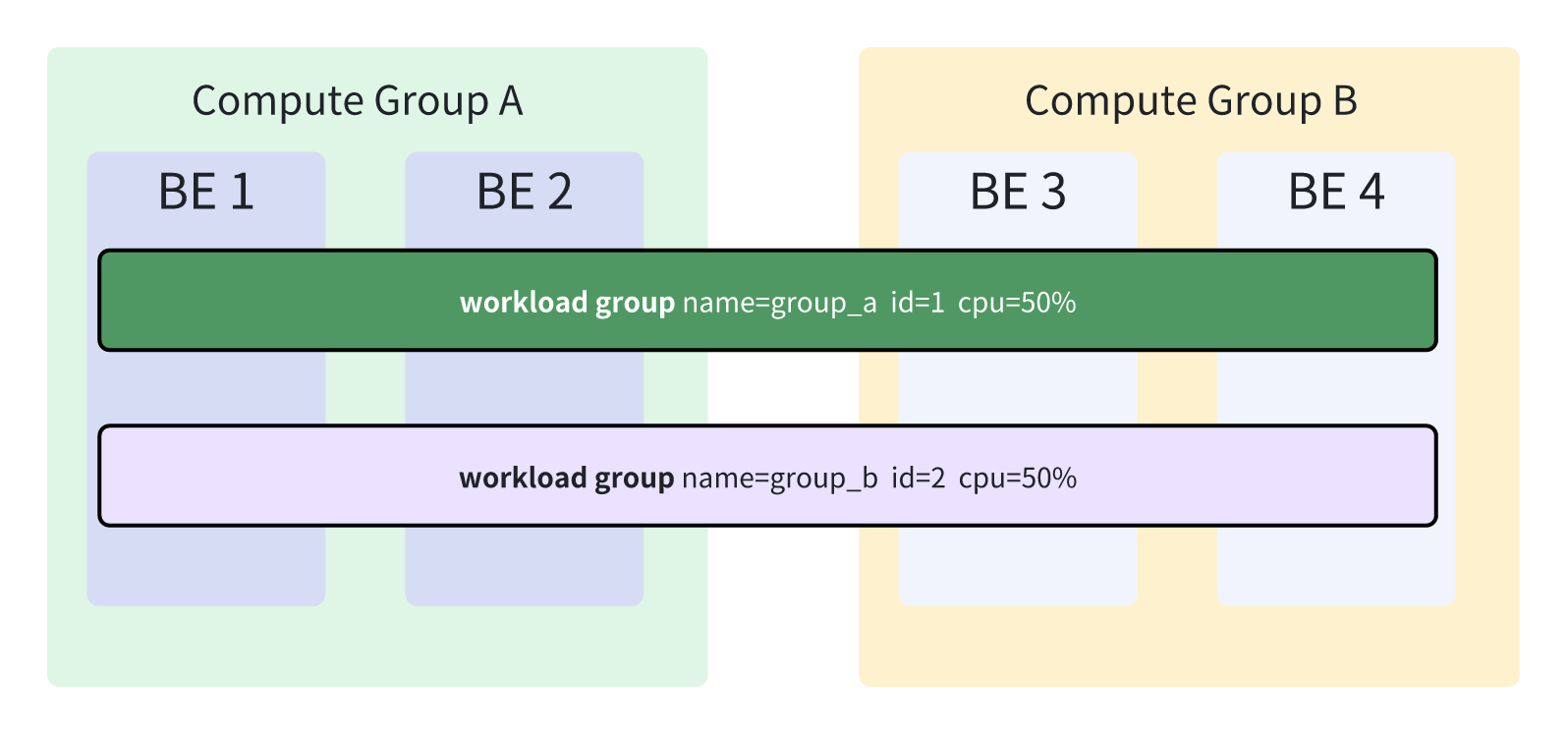
Design of Workload Group in Previous Versions
In previous versions, group_1 and group_2 would take effect on all BE nodes, even if different BEs were already grouped according to Compute Groups. In previous designs, once Business A created group_a, no new Workload Groups could be created because the cumulative resource values of all Workload Groups had already reached 100%. Additionally, since group_b was created by Business B—and Business A and Business B are completely independent business parties—Business A could neither access nor modify group_b. Even if the permission policies grant both parties access to Workload Groups, due to the complete independence of business logic, there may still be significant differences in their resource configuration requirements (e.g., high-concurrency queries of Business A and batch computing of Business B requiring different resource allocations). This makes it difficult for the old architecture to meet the needs of differentiated management.
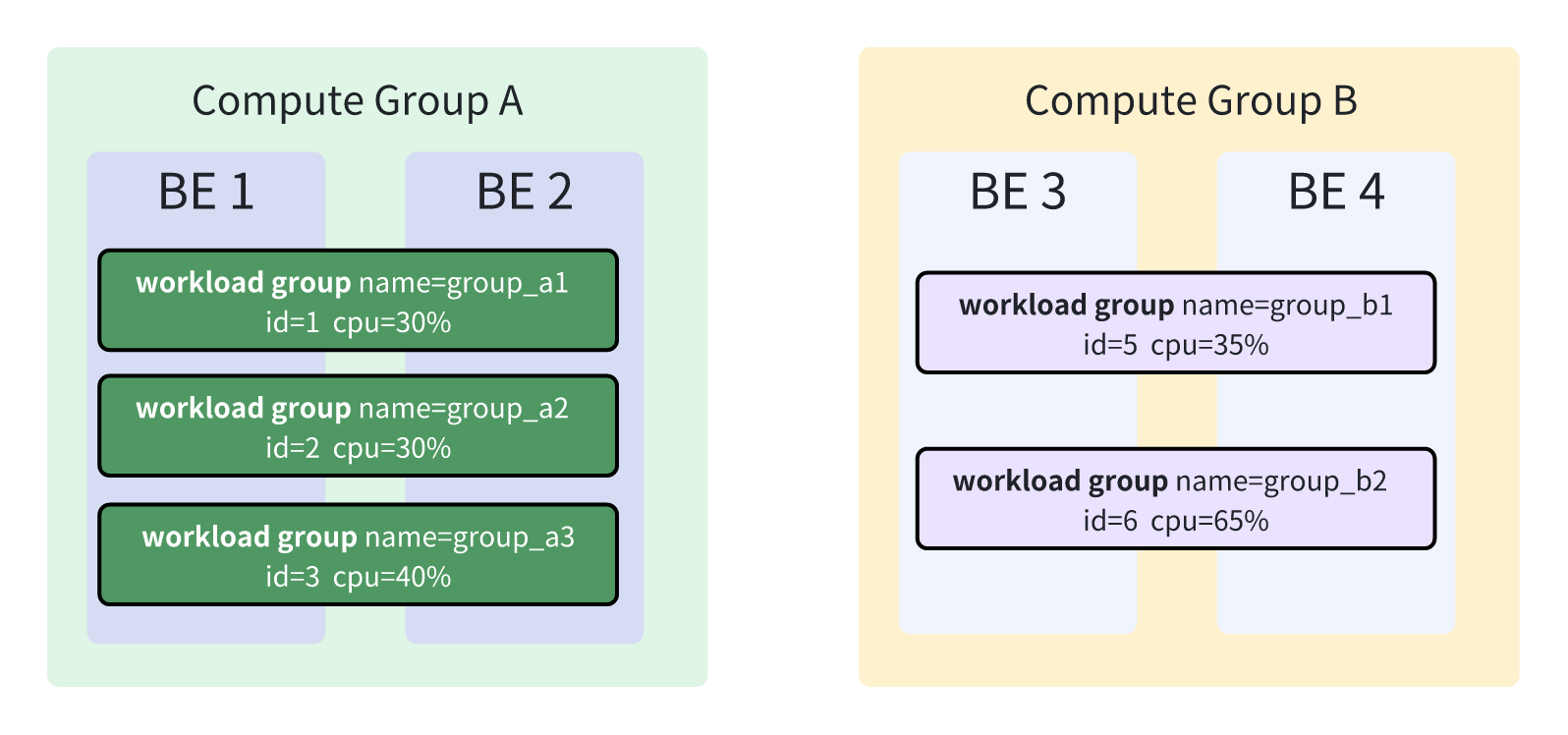
Current Design
In the current version, Workload Group supports binding to Compute Group, which means different Compute Groups can have different Workload Group configurations. As shown in the figure below:
Usage
Doris provides a default Compute Group mechanism: when a new BE node is added without a specified assignment, it is automatically placed into the default Compute Group. Specifically, in a compute-storage separation architecture, the default Compute Group is named default_compute_group, whereas in an integrated compute-storage architecture, it is named default.
- Create a Workload Group named group_a and bind it to the Compute Group named compute_group_a.
create workload group group_a for compute_group_a properties('cpu_share'='1024')
- If the Compute Group is not specified during creation, the Workload Group will be bound to the default Compute Group.
create workload group group_a properties('cpu_share'='1024')
- Drop the Workload Group named group_a from compute_group_a.
create workload group group_a for compute_group_a properties('cpu_share'='1024')
- If the Compute Group is not specified when deleting a Workload Group, the system will attempt to drop the Workload Group from the Compute Group named default.
create workload group group_a properties('cpu_share'='1024')
- Similarly, when modifying a Workload Group, the Compute Group must be specified in the ALTER statement. If the Compute Group is not specified, the system will attempt to modify the Workload Group under the default Compute Group. Note that the ALTER statement only modifies the properties of the Workload Group and cannot change its binding relationship with the Compute Group.
alter workload group group_a for compute_group_a properties('cpu_share'='2048')
NOTE
- Modifying the binding relationship between a Workload Group and a Compute Group is not currently supported. A Workload Group belongs to a fixed Compute Group upon creation and cannot be moved between Compute Groups.
- When upgrading Doris from an older version to a newer one, the system will automatically create new Workload Groups with identical names (but different IDs) for each Compute Group based on the old Workload Groups. For example, if the old-version cluster contains two Compute Groups and there is a Workload Group named group_a, after the upgrade, Doris will create a new group_a Workload Group for each of these two Compute Groups. These new Workload Groups will have different IDs from the original group_a, and the original group_a that was not associated with any Compute Group will be automatically dropped by the system.
- The authentication management of Workload Groups remains unchanged. The authentication of Workload Groups is still achieved by associating with their names.
- In Doris, there is a default Workload Group named normal. Whenever a new Compute Group is created, Doris automatically generates a normal Workload Group for it. Conversely, when a Compute Group is dropped, its corresponding normal Workload Group is automatically removed. This means that the lifecycle management of the normal Workload Group is fully automated by Doris and does not require manual intervention.