Iceberg
TL;DR Apache Doris is a full Apache Iceberg engine, not just a reader. One
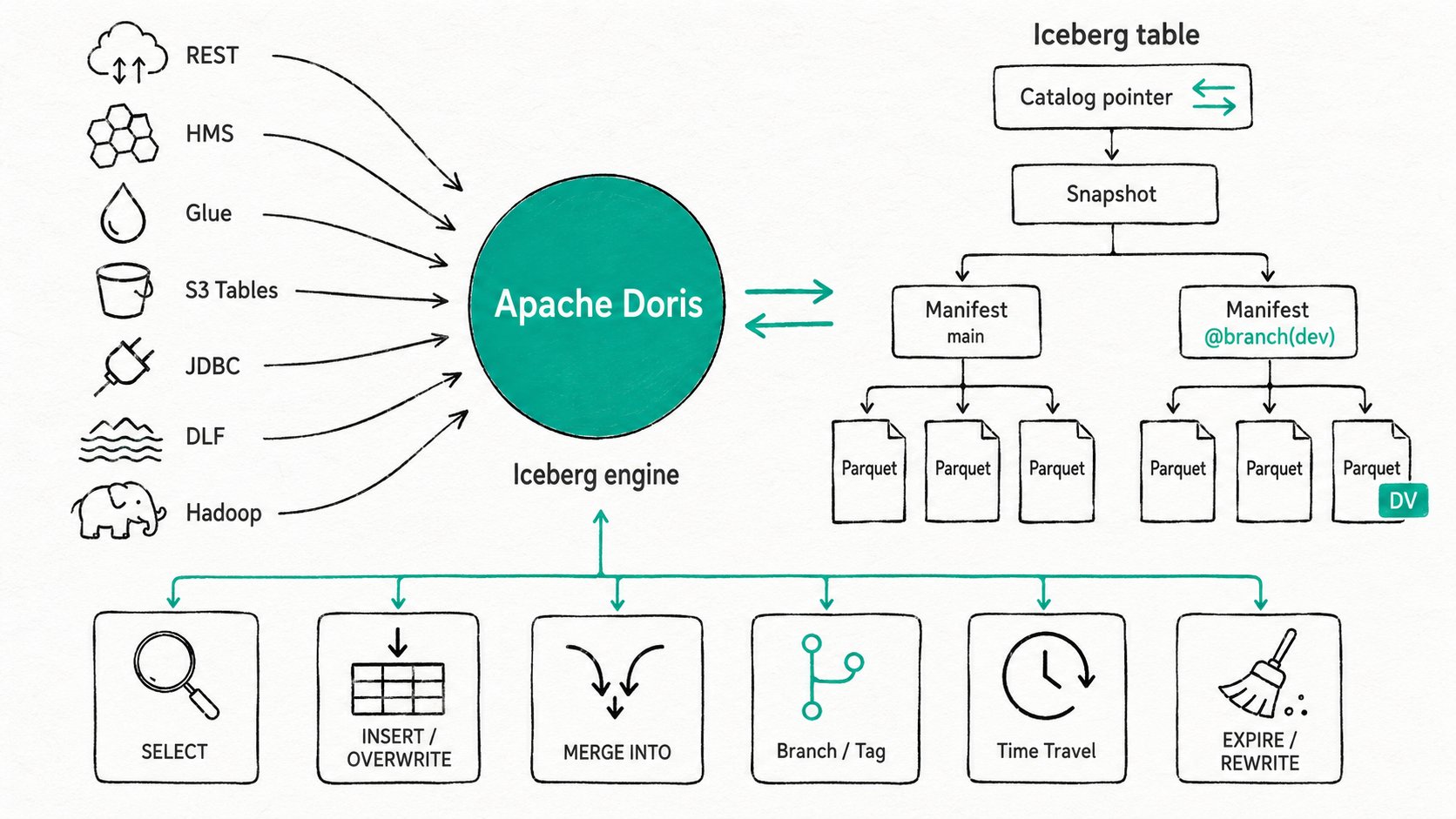
CREATE CATALOGconnects Apache Doris to any of seven Iceberg backends (REST, HMS, Glue, S3 Tables, JDBC, DLF, Hadoop). From there you can query,INSERT,UPDATE,DELETE,MERGE INTO, branch and tag, time-travel, evolve schema and partitions, and run maintenance (expire_snapshots,rewrite_data_files,rewrite_manifests) without leaving SQL. Apache Doris reads and writes V2 position and equality deletes, and V3 deletion vectors (Puffin) are supported since 4.1.
Why use the Apache Doris Iceberg catalog?
The Apache Doris Iceberg catalog is a full read-and-write engine, so the same cluster that serves dashboards also lands rows, runs maintenance, and manages branches in Iceberg without handing off to Spark or Flink. Iceberg's appeal is engine neutrality. Your data sits in Parquet on object storage, the table layout lives in an open spec, and any engine that speaks the spec can read and write the same table without copying it. The promise breaks the moment your engine treats Iceberg as a read-only side door. You connect, run a few SELECTs, and the first time you need to land a row you are back to spinning up Spark or Flink for the write path. Two clusters, two SQL dialects, two sets of credentials, one table.
Apache Doris does both halves. The cluster that serves your dashboards is the same one that maintains the Iceberg tables behind them.
- Federated queries that join Iceberg facts with the Doris warehouse run as one MPP plan, not a copy job.
- ELT pipelines write back into Iceberg through standard SQL, so other engines see the new snapshot immediately.
- Maintenance (compaction, snapshot expiry, manifest rewrite) is
ALTER TABLE ... EXECUTE, not a separate Spark job.
This card covers the Iceberg-specific surface. For federation across mixed catalog types see Multi Catalog; for the write surface that spans Iceberg, Hive, and Paimon together, see Managing Lake Tables.
What is the Apache Doris Iceberg catalog?
The Apache Doris Iceberg catalog is a native connector built on top of the Iceberg Java library. The connector speaks Iceberg's catalog API directly, so commits go through the same code path Spark and Trino use and produce snapshots those engines can read without translation.
Key terms
- Catalog type: the metastore backend that maps table names to current metadata pointers. Doris supports seven:
rest,hms,glue,s3tables,dlf,jdbc,hadoop. - Format version: V1 (append-only), V2 (merge-on-read with position and equality deletes), V3 (deletion vectors stored as Puffin files, row lineage, default values). Doris reads V1 through V3 and writes V2 by default. V3 writes need format version 4.1+.
- Snapshot: an immutable version of an Iceberg table. Every commit produces a new one.
- Branch and tag: named references to snapshots. Branches move with new commits, tags are fixed. Doris supports both for read (
@branch(name),@tag(name)) and DDL (ALTER TABLE ... CREATE BRANCH). - Position delete, equality delete, deletion vector: three ways Iceberg records row-level deletes. Position deletes mark a row by its file path and ordinal. Equality deletes match by column values. Deletion vectors store a Roaring bitmap per data file in a Puffin sidecar.
How does the Apache Doris Iceberg catalog work?
The Apache Doris Iceberg catalog connects through one of seven metastore backends, plans queries against the current snapshot (or a branch/tag/time-travel target), reconciles row-level deletes inline, and commits writes through Iceberg's catalog API.
- Connect once.
CREATE CATALOG ... PROPERTIES ('type' = 'iceberg', 'iceberg.catalog.type' = '<backend>', ...)registers a metastore and a storage system. The catalog handle persists across FE restarts. - Plan against snapshots. When a query touches an Iceberg table, the FE resolves it to the current snapshot (or a branch, tag, or time-travel target), reads the manifest list, prunes partitions and data files using min/max stats, and pushes filters down. BE workers stream the surviving Parquet or ORC files.
- Reconcile deletes on the fly. Position deletes are applied as a left anti-join on
<file_path, row_position>. Equality deletes match on the delete schema. V3 deletion vectors fold into the scan as a bitmap lookup, which is cheaper than a join for high-cardinality deletes. - Commit atomically on write.
INSERT,INSERT OVERWRITE,CTAS,UPDATE,DELETE, andMERGE INTOgo through Doris'sIcebergTransaction. BE writers stage Parquet (or, for new tables on V3, deletion vectors when rewriting). The FE assembles the manifest list and asks the catalog to swap the table pointer. On conflict, the statement fails with a clear snapshot-mismatch error instead of producing torn writes. - Maintain in place. Snapshot expiry, data-file compaction, manifest rewrite, branch fast-forward, and snapshot cherrypick run as
ALTER TABLE <t> EXECUTE <action>(...)and commit through the same catalog API. No external scheduler, no Spark job on the side.
Quick start
CREATE CATALOG iceberg_rest PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'uri' = 'http://rest:8181',
'warehouse' = 's3://lake/wh',
's3.endpoint' = 'http://minio:9000',
's3.access_key' = 'admin', 's3.secret_key' = 'password'
);
SWITCH iceberg_rest;
CREATE DATABASE IF NOT EXISTS sales;
CREATE TABLE sales.orders (id BIGINT, region STRING, amount DECIMAL(10,2), ts DATETIME)
PARTITION BY LIST (region, day(ts)) ()
PROPERTIES ('format-version' = '2');
INSERT INTO sales.orders VALUES (1, 'bj', 99.50, '2026-05-08 10:00:00');
ALTER TABLE sales.orders CREATE BRANCH dev;
INSERT INTO sales.orders@branch(dev) VALUES (2, 'sh', 12.00, '2026-05-08 11:00:00');
ALTER TABLE sales.orders EXECUTE expire_snapshots('retain_last' = '5');
Expected result
+----------+
| count(*) |
+----------+
| 1 | -- main branch
| 2 | -- dev branch (SELECT ... FROM sales.orders@branch(dev))
+----------+
Trino or Spark pointed at the same REST endpoint see the same snapshots Doris just wrote.
When should you use the Apache Doris Iceberg catalog?
The Apache Doris Iceberg catalog fits federated lakehouse analytics, SQL-only ELT into Iceberg, branch-based workflows, and in-place maintenance; it is not the right tool for high-frequency single-row updates or Hudi writes.
Good fit
- Federated analytics across Iceberg and the Apache Doris warehouse, with no copy job into Apache Doris first.
- ELT pipelines that land curated data into Iceberg from JDBC, Kafka, or Hive sources, all in SQL.
- Team workflows that need git-style isolation: write into a dev branch, validate, then
fast_forwardthe main branch. - Reproducible backfills and audits using
FOR VERSION AS OFor named tags. - Streaming jobs that need scheduled compaction.
rewrite_data_filesandexpire_snapshotskeep the small-files problem in check. - Migrations off Hive. Create the Iceberg table from Doris, dual-write while you cut over, then retire the Hive copy.
Not a good fit
- High-frequency row-level updates. Iceberg commits are snapshot-based, so per-statement overhead is far higher than a Doris Unique Key table. Use Doris internal tables for CDC sinks that need single-row latency.
- DELETE or UPDATE on V1 Iceberg tables. Row-level DML needs format version 2 or 3. Either set
'format-version' = '2'at create time, or upgrade the table. - Hudi writes. Doris is a Hudi reader today. Use Spark or Flink for Hudi writes.
- Cross-catalog transactions. A statement that writes to two Iceberg catalogs (or to an Iceberg table and a Doris table) is not a single ACID unit. Stage in one and replicate.
- Skipping maintenance. Without
expire_snapshots, storage and metadata grow unboundedly and time-travel reads slow down. Schedule it. - Filesystem (
hadoop) catalogs for concurrent writers. File-based catalogs have no lock service. Use REST, HMS, Glue, JDBC, or DLF for any multi-writer setup.
Further reading
- Iceberg catalog reference: the full DDL, DML, branch/tag, time-travel, and table-action syntax, with version notes for every capability.
- Managing Lake Tables: the write and lifecycle surface Doris exposes across Iceberg, Hive, and Paimon.
- Multi Catalog: how Doris federates Iceberg alongside Hive, JDBC, ES, and the internal warehouse under three-part names.
- Catalog Integrations: per-backend connection details for HMS, Glue, REST, S3 Tables, DLF, JDBC, and Hadoop.
- Lakehouse overview: where Iceberg fits in Doris's broader federated-analytics story.
- Doris + Iceberg best practices: a working REST + MinIO demo with partition transforms, time travel, V2 DML, and PyIceberg interop.
- iceberg_meta() table function: query snapshots, manifests, files, refs, and history without dropping into the Iceberg Java API.