Inverted Index
TL;DR The Apache Doris inverted index is a CLucene-backed secondary index declared on any column with
INDEX ... USING INVERTED. The index accelerates equality, range,IN,IS NULL, array membership, and full-textMATCH_*predicates by reading a posting list instead of scanning rows. Available since Apache Doris 2.0.
Why use the inverted index in Apache Doris?
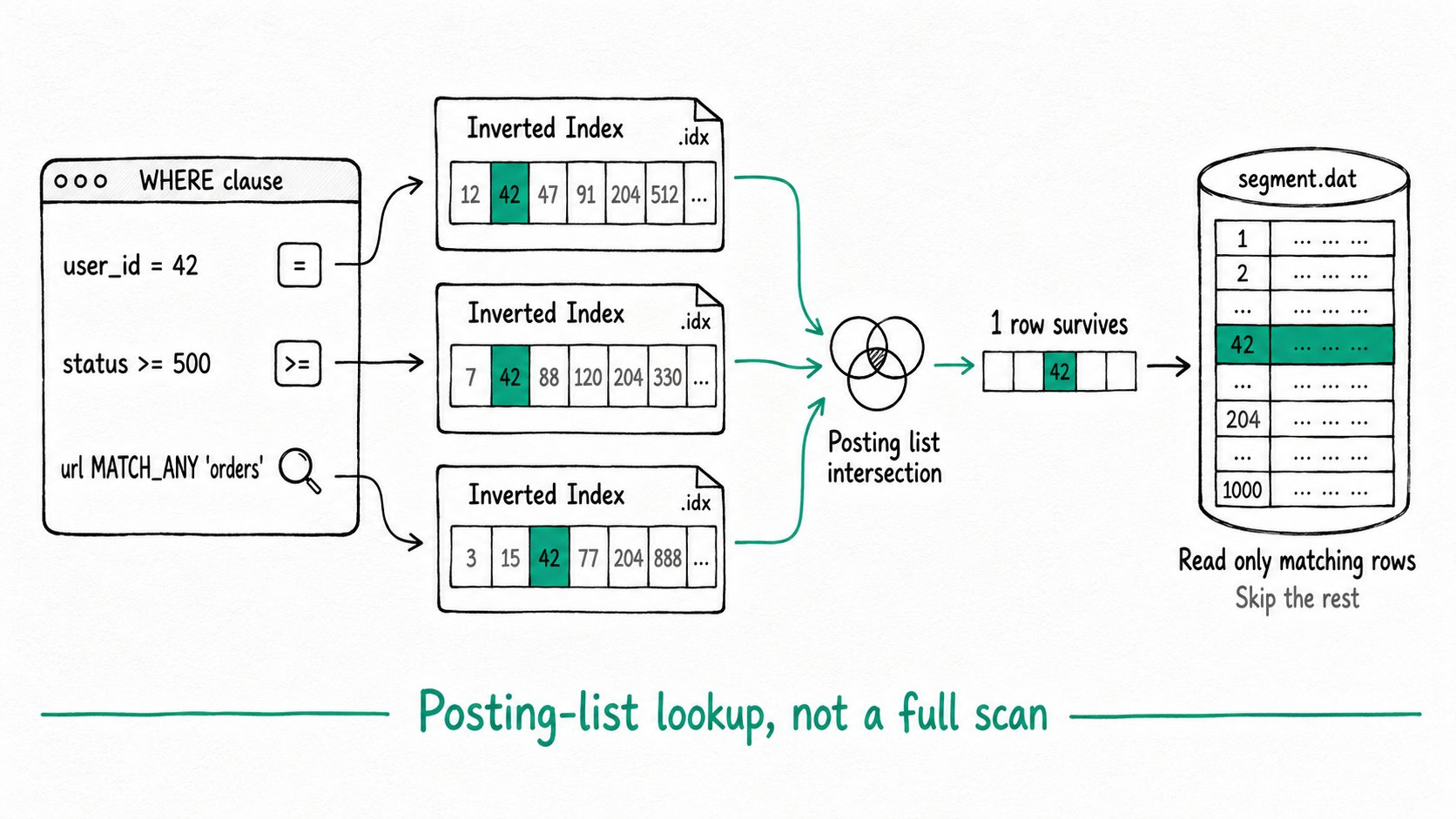
The Apache Doris inverted index turns the dominant cost of OLAP queries, evaluating WHERE predicates, from a full scan into a posting-list lookup. A 2 TB events table with a predicate on user_id, a range on request_time, and a keyword search on url would otherwise decode every column for every row in every surviving segment. The usual workaround, an incremental materialized view or a separate search cluster, doubles storage and operational cost.
The cases that hurt:
- Equality lookups on high-cardinality columns (
WHERE order_id = ?) scan whole tablets because nothing rules out segments cheaply. - Range filters on numeric or datetime columns (
WHERE event_time BETWEEN ...) are bounded only by ZoneMap min/max and still touch every page in range. - Keyword search on text columns has no answer in the base SQL engine.
LIKE '%term%'falls back to a scan, and shipping the data to Elasticsearch means a second pipeline to keep in sync.
The Apache Doris inverted index handles all three with the same DDL.
What is the Apache Doris inverted index?
The Apache Doris inverted index is a column-level secondary index that maps each value, or each tokenized term for text columns, to the set of row IDs that contain it. It is built on top of CLucene, a C++ port of Lucene, and is fully integrated with Apache Doris columnar storage and vectorized execution.
An inverted index is declared in DDL with INDEX <name>(<col>) USING INVERTED [PROPERTIES(...)]. Supported column types include the integer family, DECIMAL, DATE, DATETIME, IPV4, IPV6, CHAR/VARCHAR/STRING, and ARRAY<T> of those. For text columns you can attach a parser to control tokenization.
Key terms
Posting list: the row-ID set associated with a value or term. Predicate evaluation becomes a posting-list lookup plus a set operation (AND/OR/NOT).Parser: the tokenizer used for text columns. Built-in choices:none(whole-string, default),english,chinese,unicode,standard, plus custom analyzers since 3.1.MATCH operators:MATCH_ANY(any term),MATCH_ALL(all terms),MATCH_PHRASE(adjacent terms),MATCH_PHRASE_PREFIX,MATCH_REGEXP. They require an inverted index with a parser; ordinary=andLIKEdo not..idx file: the on-disk index payload. One.idxfile lives next to each segment file under the tablet directory, so the index is segment-bound and follows the rowset through compaction.
How does the Apache Doris inverted index work?
The Apache Doris inverted index follows a build-once, probe-many flow that keeps the index co-located with the segment it indexes.
- Build at write time. When a rowset is flushed, the BE writes a CLucene-format index to a sibling
.idxfile. Each row in the segment maps 1:1 to a CLuceneDocID, so the index never has to maintain a separate row-to-doc table. - Choose a path at query time. For a predicate the planner pushes down, the BE consults the inverted index first: it tokenizes the literal with the same parser used at build time, walks the term dictionary, and reads the posting list.
- Combine with set operations.
AND,OR, andNOTbetween predicates become intersections, unions, and complements over posting lists, all without touching column data. - Hand a row bitmap to the scanner. The scanner reads only the surviving rows from the columnar store. ZoneMap, BloomFilter, and inverted index results compose: each one shrinks the work the next layer has to do.
- Stay segment-local. Because indexes live next to segments, compaction merges them with the data and remote storage tiering carries them along. There is no global index to rebuild.
Quick start
CREATE TABLE access_log (
ts DATETIME NOT NULL,
user_id BIGINT NOT NULL,
status INT NOT NULL,
url STRING NOT NULL,
INDEX idx_user(user_id) USING INVERTED,
INDEX idx_status(status) USING INVERTED,
INDEX idx_url(url) USING INVERTED PROPERTIES("parser"="english")
) DUPLICATE KEY(ts) DISTRIBUTED BY HASH(user_id) BUCKETS 4;
INSERT INTO access_log VALUES
('2026-05-01 10:00:00', 42, 200, '/api/orders/list'),
('2026-05-01 10:01:00', 42, 500, '/api/orders/create'),
('2026-05-01 10:02:00', 99, 200, '/api/users/profile');
SELECT user_id, status, url FROM access_log
WHERE user_id = 42 AND status >= 500 AND url MATCH_ANY 'orders';
Expected result
+---------+--------+---------------------+
| user_id | status | url |
+---------+--------+---------------------+
| 42 | 500 | /api/orders/create |
+---------+--------+---------------------+
Each predicate is served by an index probe. user_id = 42 and status >= 500 use the inverted index for equality and range. url MATCH_ANY 'orders' tokenizes the column with the english parser and looks up the posting list for orders. The scanner only reads the one row that survives the AND of the three posting lists.
When should you use the Apache Doris inverted index?
The Apache Doris inverted index pays off on high-cardinality predicates, text and array search, and any column where ZoneMap pruning is too coarse.
Good fit
- High-cardinality equality and
INon non-key columns:order_id,trace_id,device_id. - Range and
BETWEENfilters on numeric orDATETIMEcolumns where ZoneMap alone is too coarse. IS NULL/IS NOT NULLon sparse columns; the index records nulls and probes them in O(1).- Keyword and phrase search on log, document, and content columns. See Full-text search for the operator set and BM25 scoring for relevance ranking.
- Array-membership predicates:
array_contains(tags, 'x')andarray_overlaps(tags, ['a','b']).
Not a good fit
- Leading-wildcard
LIKE '%abc%'. The inverted index does not accelerate substringLIKE; reach for the NGram BloomFilter index instead. - The most frequent filter column on the table. Promote it to a Key column so the prefix index handles it; the prefix index is denser and free.
- Tiny tables (a few million rows) where a full scan finishes in milliseconds. The index pays for itself only when the data it skips dwarfs the cost of probing.
- Columns where the predicate already matches most rows. Posting lists win when they are short; if 80% of rows survive, the scanner does the same work either way.
- Storage-constrained tables: an inverted index on a wide text column can rival the column itself in size. If footprint matters more than text search, use a BloomFilter index.
Further reading
- Inverted index user guide: full DDL syntax, parser options, and management commands.
- Search operators reference: every
MATCH_*operator with examples. - Index overview: how the inverted index compares with prefix, ZoneMap, BloomFilter, and NGram BloomFilter.
- Full-text search: tokenizers, phrase queries, and the
SEARCH()DSL built on top of this index. - BM25 relevance scoring: ranking matches with
score(), available since 4.0. - Hybrid search: combining inverted index with the ANN vector index in a single SQL query.
- How inverted index works in Apache Doris: a deeper write-up on internals and benchmarks.