Kafka and CDC Integration
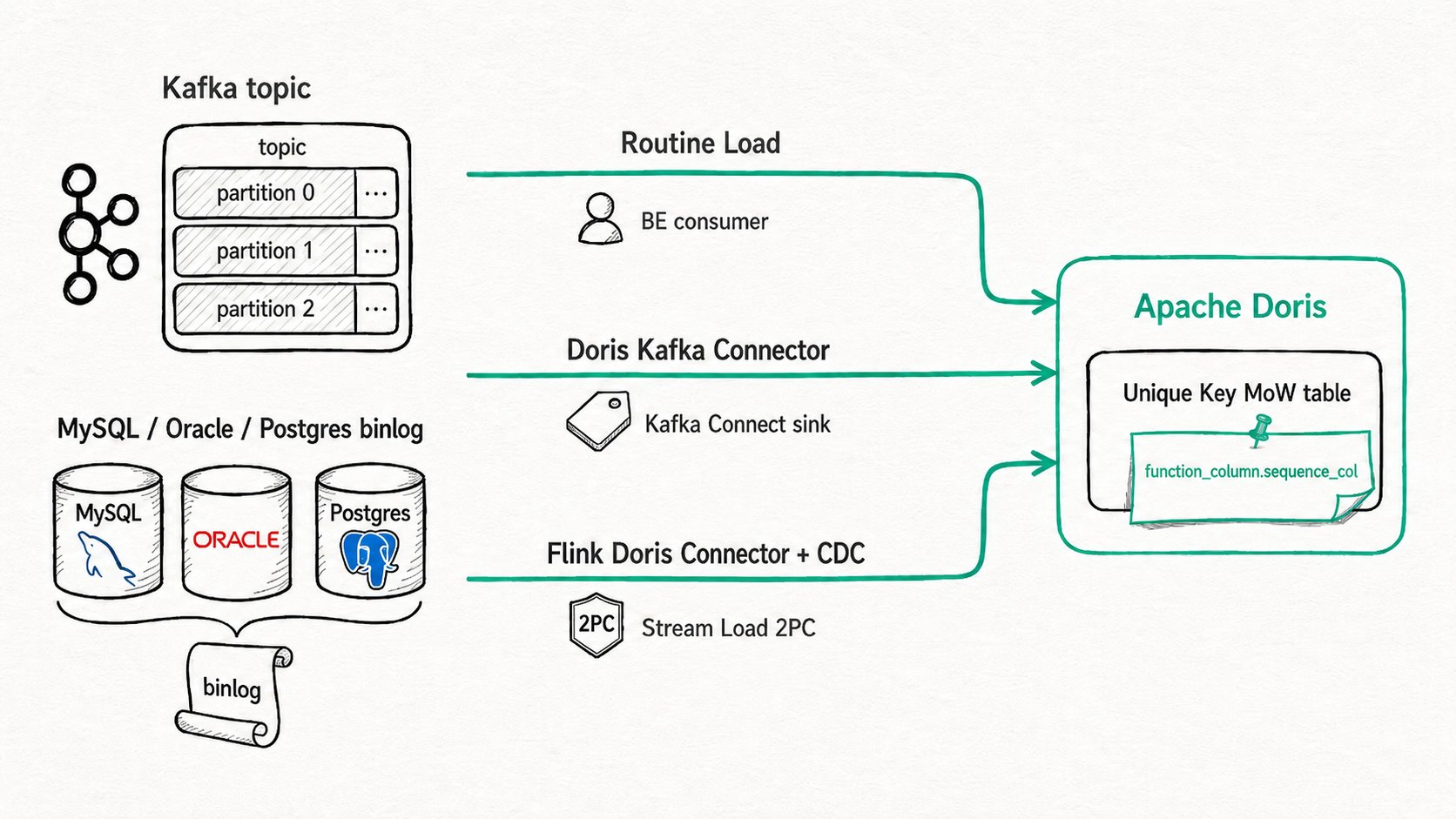
TL;DR Apache Doris ingests Kafka topics and CDC change streams natively through three paths. Use Routine Load when you want a Kafka consumer that lives inside the FE and needs no external service. Use the Flink Doris Connector with Flink CDC when you want whole-database MySQL/Postgres/Oracle sync with exactly-once via Stream Load 2PC. Use the Doris Kafka Connector when Kafka Connect is already running and your payloads are Avro, Protobuf, or Debezium. All three paths land in the same Unique Key Merge-on-Write tables, so out-of-order events and deletes work the same way regardless of which path you pick.
Why use Kafka and CDC integration in Apache Doris?
Apache Doris Kafka and CDC integration puts streaming ingestion, exactly-once delivery, and out-of-order handling inside the engine, so the path from a topic or binlog to a queryable row stays short. Most warehouses make you bolt on streaming ingest. You stand up a Kafka consumer, re-implement offset bookkeeping, retry, schema mapping, and deletes, and hope the consumer dies cleanly when the warehouse falls over. Or you run Flink in front and pay for an extra cluster. Or you give up on "real-time" and ship five-minute batches via bulk load.
- A CDC pipeline replays its last batch after a checkpoint failure and doubles every row it had buffered.
- An out-of-order update on a Unique Key table loses to the older version because nothing told the engine which write is fresher.
- A Kafka topic carrying Avro or Protobuf does not fit an HTTP load API that only speaks JSON or CSV.
Doris pushes most of this into the engine, so the path from a Kafka topic or a MySQL binlog to a queryable row is short and the failure modes are ones you can name.
What is the Apache Doris Kafka and CDC integration?
Apache Doris Kafka and CDC integration is a set of streaming and CDC ingestion paths that share one backbone: transactional loads identified by a Label, Unique Key Merge-on-Write tables for upserts and deletes, and a sequence column that pins the winning version when events arrive out of order. The paths differ in who runs the consumer.
Key terms
Routine Load: a long-running Kafka consumer managed by the FE. OneCREATE ROUTINE LOADstatement and the FE schedules tasks to BEs that pull batches and turn each batch into a transactional load.Stream Load 2PC: an HTTP load that stops atPRECOMMITTEDuntil a follow-up call sendstxn_operation: commitortxn_operation: abort. The two-phase split is what makes external sinks exactly-once.Flink Doris Connector: an external Flink sink that drives Stream Load 2PC and ties commits to Flink checkpoints. Combined with Flink CDC, it does whole-database sync and propagates DDL.Doris Kafka Connector: a Kafka Connect sink plugin. Inherits Kafka Connect's converter ecosystem, so Avro, Protobuf, and Debezium payloads work without a custom serializer.function_column.sequence_col: a per-table property on Unique Key MOW tables that selects the column whose value decides which version of a row wins. The safety net for out-of-order CDC.
How does the Apache Doris Kafka and CDC integration work?
The Apache Doris Kafka and CDC integration paths converge on one lifecycle once data hits the FE: pull a batch, wrap it in a labeled transaction, commit on confirmation, then publish to all replicas.
- The consumer pulls a batch. Routine Load schedules a task on a BE that pulls from Kafka up to
max_batch_rows(default 20M),max_batch_size(default 1 GB), ormax_batch_interval(default 60 s), whichever hits first. Flink CDC streams rows over a chunked HTTP Stream Load, which stays open across the checkpoint window. - The batch becomes a transaction. The BE opens a transaction with a
Label. Routine Load generates the label; Flink Doris Connector tags it with the checkpoint id. Either way, resubmitting the same label deduplicates. - Commit waits for confirmation. Routine Load commits as soon as the batch lands and advances the Kafka offset on success only. Flink CDC stops at
PRECOMMITTED; the next checkpoint barrier triggerstxn_operation: commit, and a failed checkpoint triggersabort, which discards the staged data. - Publish makes rows visible. A background daemon ships
PublishVersionto every replica. When the transaction reachesVISIBLE, the new rows are queryable. Tablets in the same transaction never tear. - Errors pause the job, not the data. If a Routine Load batch breaches
max_error_number(default 0), the job moves toPAUSEDand keeps the last error URL on the FE. Resume after fixing the source data; offsets stay where they were.
Quick start
CREATE TABLE events (
user_id BIGINT, event_type STRING, ts DATETIME
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 8;
CREATE ROUTINE LOAD events_kafka ON events
COLUMNS(user_id, event_type, ts)
PROPERTIES (
"format" = "json",
"jsonpaths" = "[\"$.user_id\",\"$.event_type\",\"$.ts\"]"
)
FROM KAFKA (
"kafka_broker_list" = "localhost:9092",
"kafka_topic" = "events",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
Expected result
+--------+--------------+---------+----------------------+
| Id | Name | State | Statistic |
+--------+--------------+---------+----------------------+
| 100123 | events_kafka | RUNNING | {"loadedRows":4821,..|
+--------+--------------+---------+----------------------+
SHOW ROUTINE LOAD FOR events_kafka reports a job in RUNNING state, the last consumed offset per partition, and the count of loaded rows. PAUSE, RESUME, and STOP work the same as on any other Doris job.
For CDC, swap the consumer for the Flink Doris Connector with Flink CDC (one Flink job, MySQL source, Doris sink, sink.enable-2pc = true). The schema and sequence column live on the Doris side:
CREATE TABLE orders (
order_id BIGINT, status STRING, updated DATETIME
)
UNIQUE KEY(order_id) DISTRIBUTED BY HASH(order_id) BUCKETS 8
PROPERTIES ("function_column.sequence_col" = "updated");
The sequence_col line is what protects you when a delayed CDC event arrives after a fresher one: the older updated loses, the newer wins, and the result is the same regardless of arrival order.
When should you use the Apache Doris Kafka and CDC integration?
Use the Apache Doris Kafka and CDC integration when streaming events or upstream database changes need to land in Doris with exactly-once delivery and correct ordering, not on a five-minute batch cadence.
Good fit
- A Kafka topic carrying CSV or JSON that you want in Doris with no extra service. Routine Load is the shortest path.
- MySQL, Postgres, or Oracle CDC into Doris with exactly-once delivery and DDL propagation. Flink Doris Connector with Flink CDC.
- Kafka Connect already runs in your stack and the payloads are Avro, Protobuf, or Debezium. Doris Kafka Connector skips the format mismatch.
- Real-time dashboards over Unique Key tables that need correct ordering on out-of-order writes. Pair any path above with
function_column.sequence_col.
Not a good fit
- Avro from Kafka through Routine Load. Routine Load reads CSV and JSON only. Either convert upstream or use the Doris Kafka Connector with the appropriate converter.
- Per-event
INSERT INTO ... VALUESfrom a microservice. That is not a Kafka problem and not a CDC problem; reach for Group Commit so the BE batches small writes server-side. - Routine Load on a topic with short Kafka retention. If retention is 24 h and the job stays paused for two days, the persisted offset falls behind the earliest available offset, and Kafka rejects the resume with "out of range". Raise retention, or run a connector that buffers.
- Monitoring offset lag through the FE alone. The FE does not currently expose a lag metric (open issue). Scrape the Kafka-side consumer-lag exporter or watch BE-side rates.
- Stream Load 2PC against Merge-on-Write Unique Key tables on cloud / storage-compute-separated deployments: the BE rejects this combination, so the Flink Connector's exactly-once path falls back to
Label-based dedup plus the sequence column there. On-prem clusters keep the full Stream Load 2PC path on MoW.
Performance and numbers
From "How Flink's real-time writes to Apache Doris stay both fast and exactly-once" (July 2022 release blog): under 30 concurrent Stream Loads, end-to-end latency stayed below one second; 20 Flink tasks sustained an upstream rate near 100,000 events per second; CPU on the BE dropped about 25% versus the previous load path under high concurrency. Source: Apache Doris blog.
Further reading
- Routine Load reference
- Flink Doris Connector and Flink CDC
- Doris Kafka Connector for Avro, Protobuf, and Debezium
- Load Transactions: the model behind 2PC
- Data Update and Delete: sequence column and Merge-on-Write
- Binlog Table Stream: the change feed that runs the other direction, exposing Doris row changes to downstream consumers.
- Iceberg: a common destination for curated CDC pipelines — write-back via SQL keeps other engines' readers in sync.
- Unique Key: the table model CDC sinks land into — pair with a sequence column on the source LSN/commit timestamp.