Parquet Reader Optimization
TL;DR Apache Doris ships a native C++ vectorized Parquet reader for external catalogs and TVFs, avoiding any Java or Arrow round trip. The reader prunes whole row groups and individual pages from the file's own statistics, evaluates predicates on dictionary IDs, and reads filter columns before payload columns. Remote reads are coalesced into fewer requests, so most queries finish without ever decoding the columns they don't need.
Why use the Parquet reader in Apache Doris?
The Apache Doris native Parquet reader exists to cut the three dominant lakehouse scan costs: fetching bytes from object storage, decompressing and decoding pages, and converting values into the engine's runtime representation. A Hive or Iceberg table on S3 is, in the end, a pile of Parquet files, and a naive reader pays all three costs on every query.
That cost shows up in shapes anyone who has tuned a lakehouse query has hit:
- A
WHERE order_date >= '2026-04-01'filter scans every row group of every Parquet file because the reader never looked at the file's per-row-group min/max. - A point lookup like
WHERE user_id = 12345reads the entireuser_idcolumn when only one row group could possibly contain that ID. - A
SELECT *over a wide event table on S3 issues hundreds of small HTTP GETs per file, one per column chunk. - A predicate like
country = 'JP'decompresses and decodes UTF-8 across millions of rows, even though the column is dictionary-encoded and the answer could be one integer comparison per row.
The Apache Doris Parquet reader is built to avoid each of these before any page leaves storage.
What is the Apache Doris Parquet reader?
The Apache Doris Parquet reader is a native C++ component that reads Parquet metadata, prunes at every available granularity (row group, page, dictionary, column), and decodes values directly into the same Block format the vectorized executor consumes. There is no Java library or Arrow round trip in the path.
Key terms
Row group: the unit a Parquet file is partitioned into for parallel reads. Each one carries min/max and null-count statistics per column.PageIndex: an optional Parquet structure (ColumnIndex + OffsetIndex) that exposes the same statistics at page granularity, plus the byte offset of each page so a reader can seek directly to it.Lazy materialization: a two-pass read that decodes filter columns first, then fetches payload columns only for the rows that survived.Dictionary filtering: evaluating a predicate against a column chunk's dictionary page once, then comparing rows against the resulting set of dictionary IDs.
How does the Apache Doris Parquet reader work?
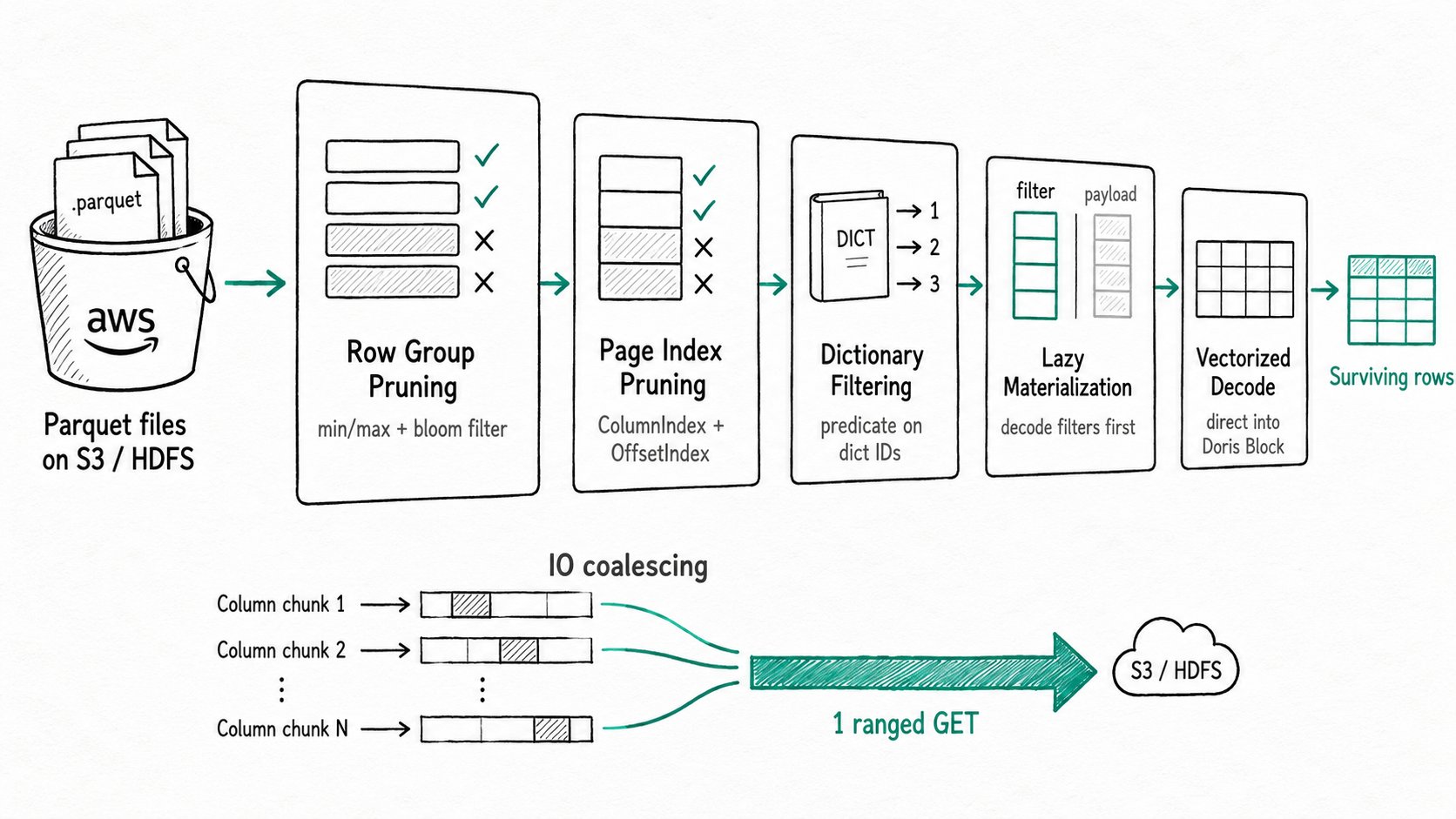
The Apache Doris Parquet reader runs a five-stage pipeline where each step shrinks what the next step has to look at.
- Row-group pruning. When the file is opened, the reader walks each row group's column statistics and drops the whole group if the predicate cannot match its min/max range. The same step probes the Parquet bloom filter when the file has one. Both checks run on metadata only, before any column page is fetched. Controlled by
enable_parquet_filter_by_min_maxandenable_parquet_filter_by_bloom_filter. - Page pruning via PageIndex. For each surviving row group, the reader parses ColumnIndex and OffsetIndex to drop individual pages whose min/max cannot match. OffsetIndex gives the byte range of each surviving page, so the reader skips straight to the next one without scanning the rejected bytes. Toggle with the BE config
enable_parquet_page_index. - Dictionary filtering. When a column chunk is dictionary-encoded and the predicate is a single-slot expression, the reader decodes only the dictionary page, evaluates the predicate against it, and rewrites the predicate to operate on dictionary IDs. The data pages then turn into bit-packed integer comparisons.
- Lazy materialization. Surviving rows still have to be assembled. The reader splits columns into filter columns (referenced by predicates) and payload columns, decodes the filter columns to build a row-selection bitmap, and only then fetches the payload columns for the surviving rows. Controlled by the session variable
enable_parquet_lazy_mat, on by default. - IO coalescing and direct decode. Adjacent column chunks within a row group are merged into a single ranged read, so the engine issues one HTTP GET instead of many. Decoded values land directly in Doris vectorized columns, with no Arrow round trip.
The result: rows that survive to the executor have already been confirmed to match, and only the columns the query asked for were ever decoded.
Quick start
SELECT region, count(*) AS orders, sum(amount) AS revenue
FROM s3(
"uri" = "s3://demo-bucket/orders/year=2026/*.parquet",
"format" = "parquet",
"s3.endpoint" = "https://s3.us-east-1.amazonaws.com",
"s3.access_key" = "AK...",
"s3.secret_key" = "SK..."
)
WHERE order_date >= '2026-04-01' AND status = 'PAID'
GROUP BY region;
Expected result (profile excerpt)
VFileScanNode
FilteredRowGroups: 18 / 24
FilteredPages: 210 / 980
LazyReadFilteredRows: 92.1%
RemoteIOMergedRanges: 14 (from 96 chunks)
The reader dropped 18 of 24 row groups on the date predicate, then dropped 210 pages inside the survivors using PageIndex on status. Lazy materialization skipped decoding region and amount for the 92.1% of rows that didn't match. Ninety-six column chunks were merged into 14 ranged GETs against S3.
When should you use the Apache Doris Parquet reader?
The Apache Doris Parquet reader is used automatically whenever a query reads Parquet, so the question is how to make sure it can do its job.
Good fit
- Hive, Iceberg, Hudi, and Paimon catalogs whose data files are Parquet.
- Direct file analysis through the s3() and
hdfs()TVFs. - Selective queries on wide tables: predicate-heavy filters give lazy materialization the most to skip.
- Equality and range predicates on columns that the writer recorded statistics for.
- Dictionary-encoded string columns with point or
INpredicates.
Not a good fit
- Tables stored as thousands of tiny Parquet files. Each footer must be parsed and each chunk is at least one ranged read; per-file overhead dominates. Compact toward 128 MB to 1 GB files.
- Files written without column statistics or PageIndex. The reader has nothing to prune on and falls back to full scans. Enable statistics in the writer (Spark 3.2+ and parquet-mr 1.11+ both write PageIndex).
- Selective predicates inside deeply nested struct fields. Some optimizations (page index, dictionary filtering) are disabled for complex types; the reader walks the surviving rows in full. Flatten the access path or use top-level columns when possible.
- DATETIME columns written as INT96 by older Hive writers. INT96 statistics are routinely corrupted, and the reader skips min/max pruning on them. If you control the writer, write INT64 timestamps. See the Hive catalog notes on INT96.
Further reading
- Parquet file format reference: the user-facing knobs (
enable_parquet_lazy_mat,enable_parquet_page_index, buffer-size BE configs) and version availability. - Analyzing files on S3/HDFS: how to query Parquet files directly with the
s3()andhdfs()TVFs. - Data Pruning: the broader story of how Doris skips reading data, of which the Parquet reader is one layer.
- Vectorized Execution: the engine the reader decodes into, and why skipping the Arrow round trip matters.
- Data Cache: when to cache decoded Parquet pages locally so repeated scans skip the remote read entirely.
- Metadata Cache: the FE-side cache for schema, partition, and file lists that the Parquet reader's pruning depends on.
- Multi-Catalog: how Parquet tables on S3, HDFS, Hive, Iceberg, and Paimon plug into Doris in the first place.
- Catalog Integrations: the per-source connector reference for the catalogs that hold Parquet files.
- Building the next-generation data lakehouse (Apache Doris blog): the original public writeup of the native Parquet reader.
- Iceberg: the lakehouse table format whose Parquet scans this optimization accelerates most directly.