Index Overview
Apache Doris accelerates queries with several index types. This page helps you decide which index, if any, to add, and links to the details of each.
Start Here
Every table already has two indexes that Doris builds and maintains for you:
- A prefix index on the sort key, which speeds up filters on the leading Key columns. Make your most frequent filter a leading Key column to use it.
- A ZoneMap index on every column, which skips data blocks that fall outside a range or equality filter.
Add a manual index only when these don't cover your query pattern:
| Your query pattern | Recommended index | When needed |
|---|---|---|
| Filter on your highest-frequency column | Make it a leading Key column (prefix index) | Always design this first |
| Equality or range filter on a non-Key column | Inverted index | Often |
LIKE substring match on text | NGram BloomFilter index | Sometimes |
| Equality filter where index size matters more than flexibility | BloomFilter index | Rarely; the inverted index is usually preferred |
| Full-text search: keyword, phrase, or multi-field | Inverted index | When you search text |
| Vector similarity (Top-K nearest neighbor) | Vector index (ANN) | For RAG, semantic search, recommendation, and media retrieval |
If a query is slower than expected, use QueryProfile to see how much each index filtered out and how long it took. See each index's page for details.
How Each Index Works
Apache Doris provides four categories of indexes for different query scenarios: point-query indexes, skip indexes, full-text search indexes, and vector indexes.
Scenario 1: Few Rows Match the Condition (Point-Query Indexes)
Applicable scenarios: Precisely matching a small amount of data, such as querying by primary key or fetching detail records by user ID.
Acceleration principle: The index directly locates the rows that satisfy the WHERE condition and reads only those rows, avoiding a row-by-row scan.
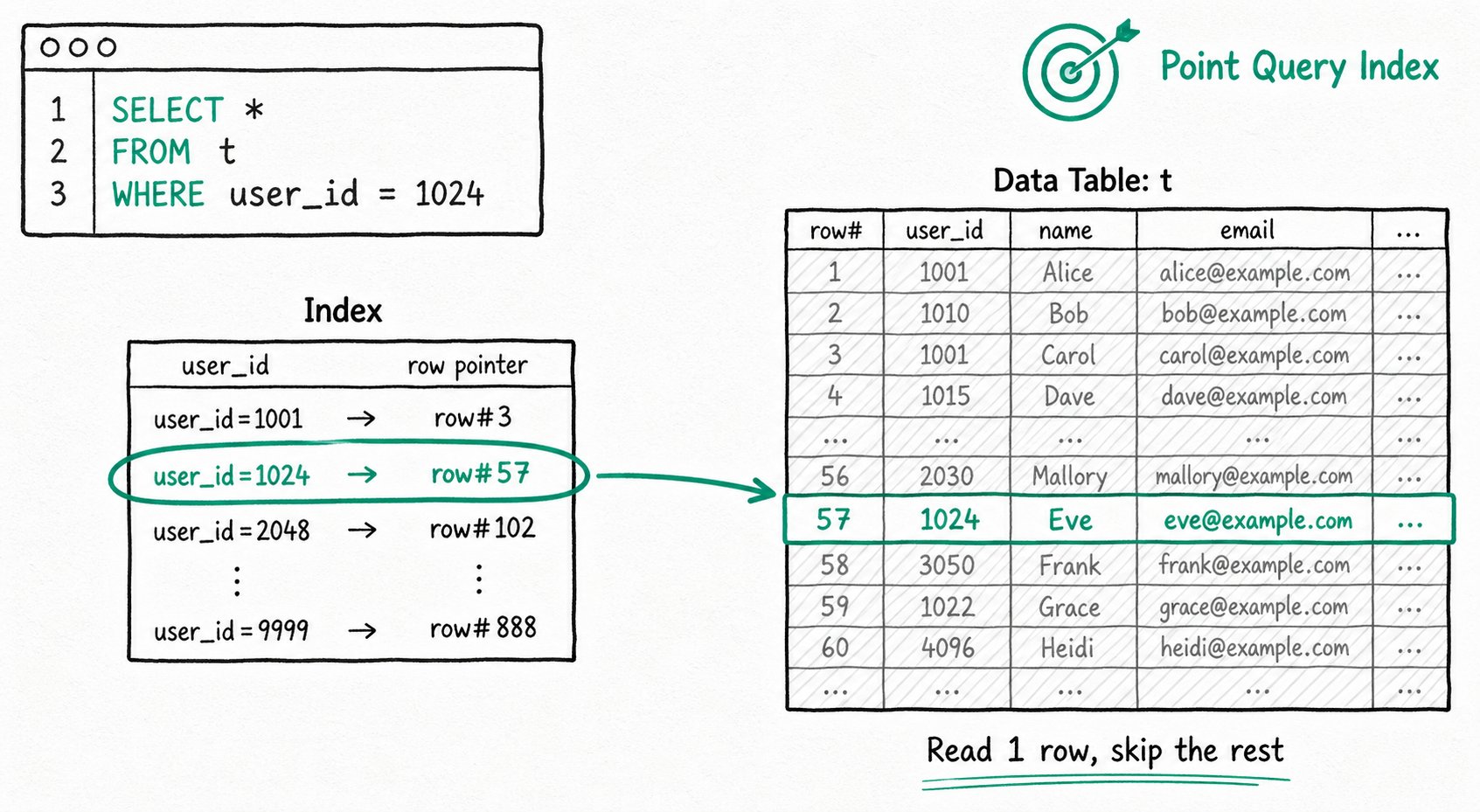
Apache Doris provides two point-query indexes:
- Prefix index: Doris stores data sorted by the sort key and builds a sparse prefix index every 1024 rows. Each index entry holds the sort-column values of the first row in its group. When a query filters on the sort columns, Doris jumps to the right group and scans from there.
- Inverted index: Doris builds an inverted table that maps each value to the rows that contain it. For an equality query, it looks up the matching rows and reads only those, which avoids a full scan and cuts I/O. Inverted indexes also speed up range filters and text keyword search; the algorithm is more involved, but the idea is the same.
The BITMAP index has been replaced by the inverted index.
Scenario 2: Many Rows Match the Condition (Skip Indexes)
Applicable scenarios: Analytical queries that need to filter large batches of data, such as time-range aggregation and dimension filtering.
Acceleration principle: The index identifies which data blocks do not satisfy the WHERE condition, skips those blocks, reads only the blocks that may satisfy the condition, and then performs a row-by-row filter to obtain the final result.
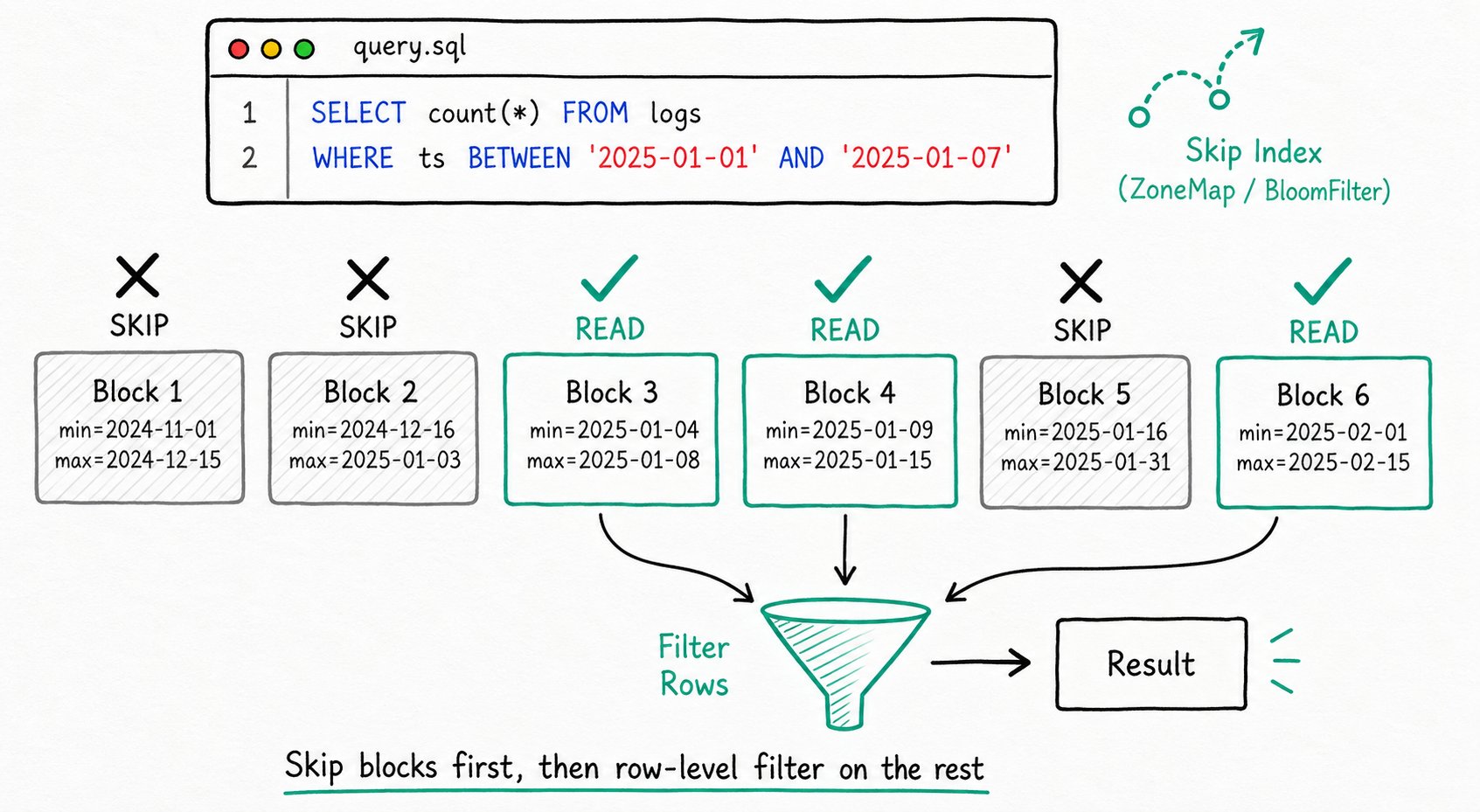
Apache Doris provides three skip indexes:
- ZoneMap index: Doris automatically keeps per-column statistics (min, max, and whether NULLs exist) for each data file (Segment) and data block (Page). For equality, range, and IS NULL filters, it uses these stats to decide whether a file or block can contain matching rows. If it can't, Doris skips that file or block and cuts I/O.
- BloomFilter index: Doris stores the column's values in a BloomFilter, a structure that tells you whether a value is present with very little storage. For an equality query, if the value isn't in the filter, Doris skips that file or block and cuts I/O.
- NGram BloomFilter index: Speeds up text
LIKEqueries. It works like the BloomFilter index, but stores NGram tokens of the text instead of whole values. For aLIKEquery, Doris tokenizes the pattern the same way and checks each token against the filter. If any token is missing, the file or block can't match, so Doris skips it.
Scenario 3: Full-Text Search on Text (Inverted Index)
Applicable scenarios: Log analysis, content search, support-ticket mining, and other scenarios that need to find data in text fields by keyword, phrase, or pattern matching.
Acceleration principle: A tokenizer splits text into terms, and an inverted table is built that maps each term to the corresponding row numbers. At query time, the search terms are tokenized in the same way, the row number sets containing these terms are retrieved from the inverted table and merged according to AND/OR/NOT relationships, and the matching rows are then read directly. This avoids a row-by-row scan and regular-expression matching of the original text.
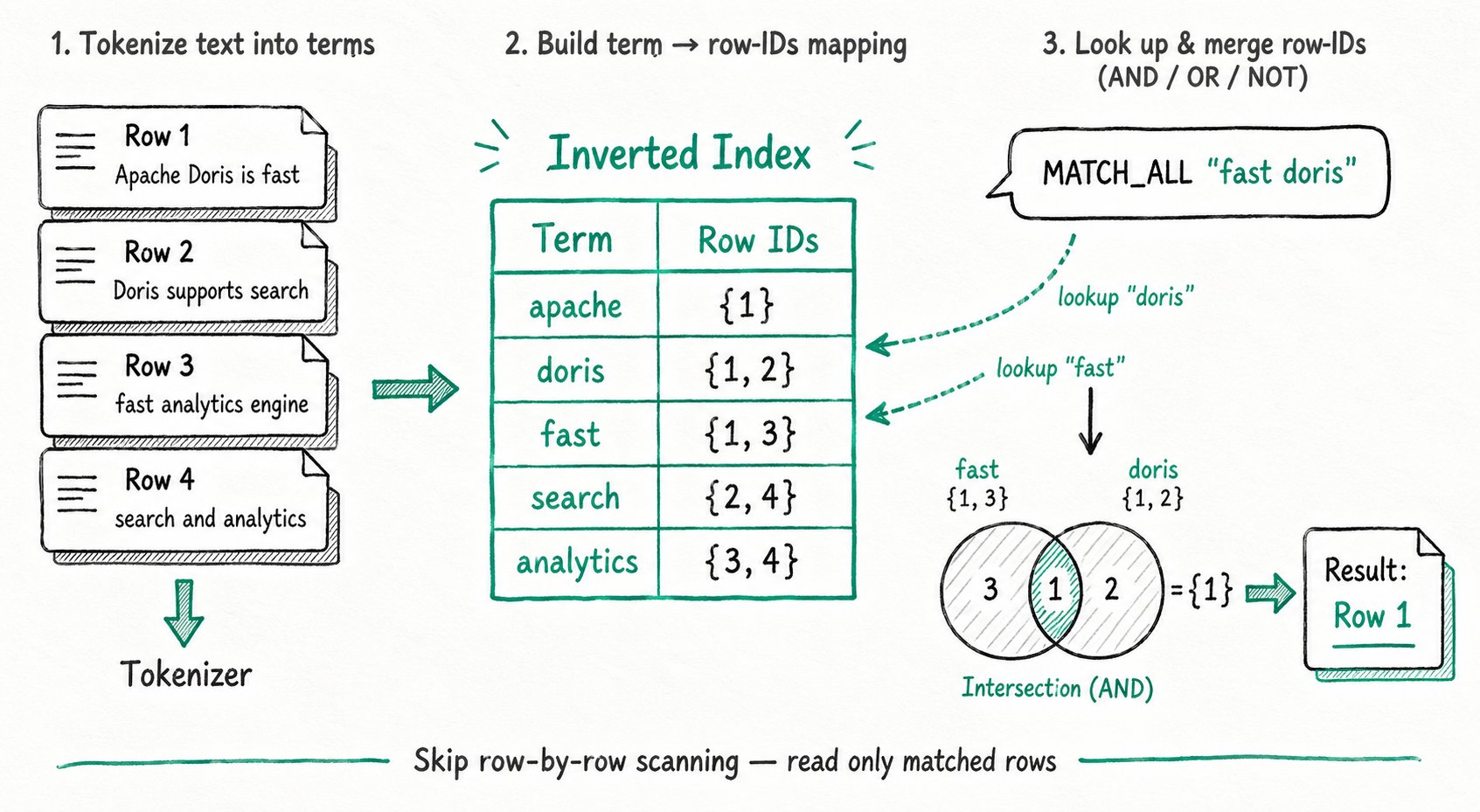
For detailed usage, see Inverted Index. The Apache Doris inverted index supports:
- Keyword search:
MATCH_ANY(any one of the words hits) andMATCH_ALL(all of the words hit). - Phrase queries:
MATCH_PHRASEsupports order-sensitive phrase matching with a configurable word distanceslop;MATCH_PHRASE_PREFIXsupports phrase plus last-word prefix matching;MATCH_REGEXPsupports regular-expression matching on tokenized terms. - Multilingual tokenization: Built-in tokenizers including
english,chinese,unicode,icu,basic, andik, covering Chinese, English, mixed text, and multilingual scenarios. - Multi-column combined search: Use the
multi_matchfunction to perform OR/AND/phrase/prefix search across multiple fields. - Combination with regular filters: Combine arbitrarily with equality, range,
IN, and other conditions, as well as other indexes through AND/OR/NOT, reusing the same inverted index to complete the query.
Scenario 4: Vector Similarity Search (Vector Index)
Applicable scenarios: RAG (retrieval-augmented generation), semantic search, recommendation systems, and image/audio/video retrieval that need to find Top-K nearest neighbors by vector similarity or to filter by a distance threshold.
Acceleration principle: The traditional approach computes the distance between the query vector and every record, with a cost that grows linearly with the data volume. A vector index (ANN, Approximate Nearest Neighbor) builds a graph (such as HNSW) or clustering (such as IVF) structure over the vector set in advance, restricting the search space to a small set of candidate vectors. This trades a controllable loss of accuracy for an order-of-magnitude speedup.
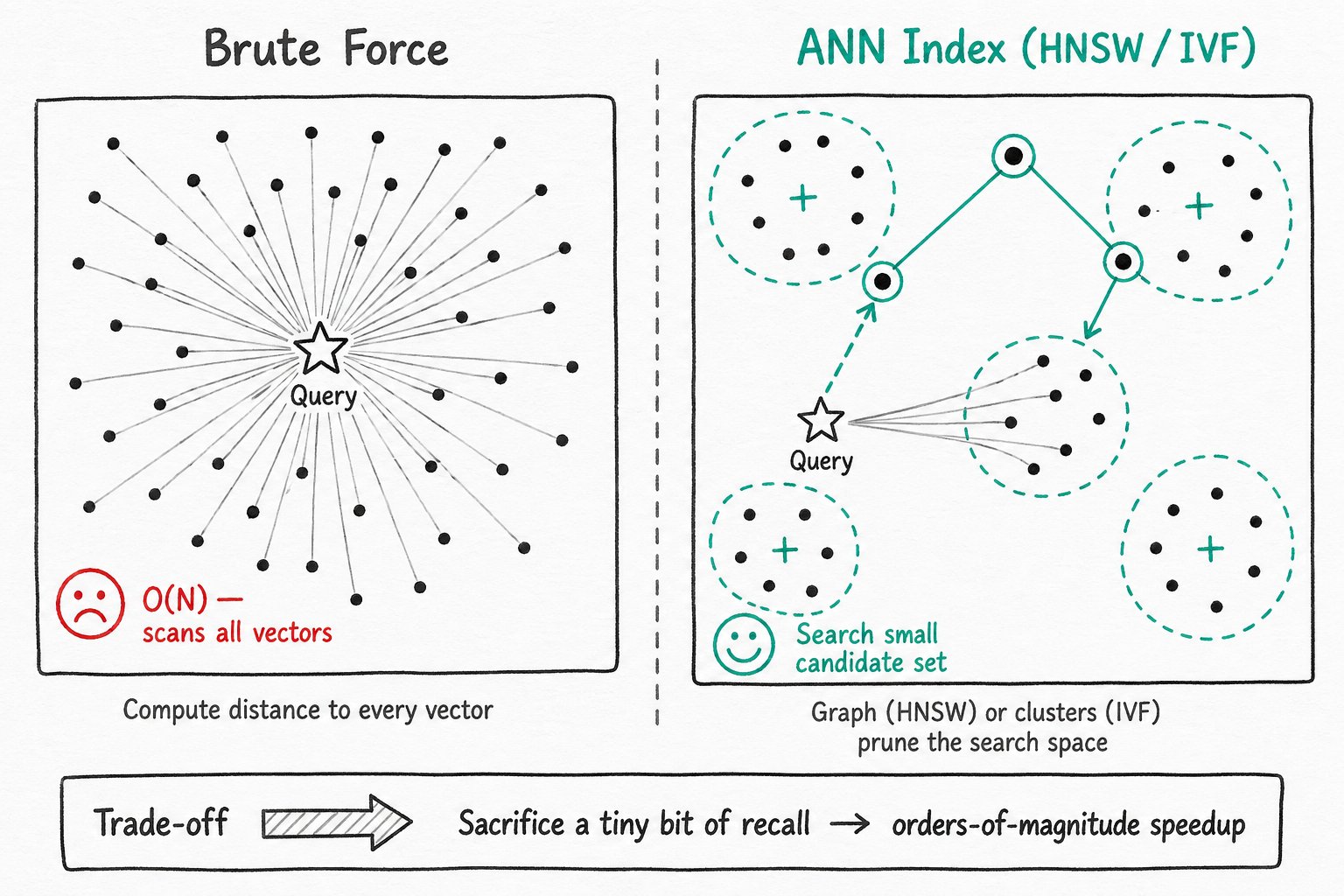
For detailed usage, see Vector Index. Apache Doris supports ANN indexes starting from version 4.0. The main capabilities include:
- Multiple index algorithms: Supports
hnsw,ivf, andivf_on_disk, which suit in-memory high-QPS, memory-constrained, and ultra-large-scale on-disk scenarios respectively. - Multiple distance metrics: Supports
l2_distance(Euclidean distance) andinner_product(inner product). After applying L2 normalization to vectors, Cosine similarity can be implemented equivalently. - TopN / range / combined queries: Use
l2_distance_approximateandinner_product_approximateto implement ANN TopN, also supports range search based on a distance threshold, and supports combining TopN with Range conditions in the same SQL statement. - Hybrid search with scalar filters: Works together with secondary indexes such as the inverted index. Structured conditions (such as
MATCH_ANY 'music') can first filter the candidate set, and then ANN TopN runs on that candidate set, enabling vector search with filter conditions. - Vector quantization: Supports
flat,sq8,sq4,pq, and other quantization methods to flexibly trade off recall against memory and disk usage.
Index Management Methods
Based on whether manual user management is required, Apache Doris indexes fall into two categories:
| Management Method | Index Types | Description |
|---|---|---|
| Automatically maintained | Prefix index, ZoneMap index | Built-in smart indexes in Apache Doris, no user management required |
| Manually created | Inverted index, BloomFilter index, NGram BloomFilter index, Vector index | Users choose based on the query scenario and create or drop them manually |
Comparison of Index Characteristics
The following table summarizes the strengths and limitations of each index type for quick selection:
| Category | Index | Strengths | Limitations |
|---|---|---|---|
| Point-query index | Prefix index | Built-in index with the best performance | Each table has only one set of prefix indexes |
| Point-query / full-text search | Inverted index | Supports tokenization and keyword matching, can be built on any column, supports combining multiple conditions, with continuously expanding function-level acceleration | Index storage space is large, comparable to the original data |
| Skip index | ZoneMap index | Built-in index with small storage footprint | Supports few query types, only equality and range |
| Skip index | BloomFilter index | More fine-grained than ZoneMap, with moderate storage footprint | Supports few query types, only equality |
| Skip index | NGram BloomFilter index | Accelerates LIKE queries, with moderate storage footprint | Supports few query types, only LIKE acceleration |
| Vector index | ANN index | Supports vector similarity TopN / range / combined search, can be linked with scalar filters; supports multiple quantization methods to balance recall and resource usage | Only applicable to Array<Float> columns that are NOT NULL, and only supports the DUPLICATE KEY table model |
Index Support for Operators and Functions
The following table lists the acceleration support of each index type for common operators and functions:
| Operator / Function | Prefix Index | Inverted Index | ZoneMap Index | BloomFilter Index | NGram BloomFilter Index |
|---|---|---|---|---|---|
= | YES | YES | YES | YES | NO |
!= | YES | YES | NO | NO | NO |
IN | YES | YES | YES | YES | NO |
NOT IN | YES | YES | NO | NO | NO |
>, >=, <, <=, BETWEEN | YES | YES | YES | NO | NO |
IS NULL | YES | YES | YES | NO | NO |
IS NOT NULL | YES | YES | NO | NO | NO |
LIKE | NO | NO | NO | NO | YES |
MATCH, MATCH_* | NO | YES | NO | NO | NO |
array_contains | NO | YES | NO | NO | NO |
array_overlaps | NO | YES | NO | NO | NO |
is_ip_address_in_range | NO | YES | NO | NO | NO |
Index Design Principles
Index design and tuning for a database table are closely tied to data characteristics and query patterns, and require testing and tuning based on the actual scenario. Although there is no silver bullet, Apache Doris keeps lowering the difficulty of using indexes. When designing indexes, use the decision table in Start Here to choose and test them.