
Apache Dorisの概要
Apache Dorisとは
Apache Dorisは、高いクエリ速度で知られるMPPベースのリアルタイムデータウェアハウスです。大規模データセットに対するクエリでは、サブセカンド以内で結果を返します。高同時実行性のポイントクエリと高スループットの複雑な分析の両方をサポートします。レポート分析、アドホッククエリ、統合データウェアハウス、およびデータレイククエリアクセラレーションに使用できます。Apache Dorisに基づいて、ユーザーはユーザー行動分析、A/Bテストプラットフォーム、ログ分析、ユーザープロファイル分析、およびeコマース注文分析のためのアプリケーションを構築できます。
Apache Dorisは、以前はPaloとして知られており、元々Baiduの広告レポートビジネスをサポートするために作成されました。2017年に正式にオープンソース化され、2018年7月にBaiduによってApache Software Foundationに寄贈され、Apacheメンターの指導の下でインキュベータープロジェクト管理委員会のメンバーによって運営されました。2022年6月、Apache DorisはApacheインキュベーターからTop-Level Projectとして卒業しました。現在までに、Apache Dorisコミュニティは異なる業界の数百の企業から700人以上のコントリビューターを集め、月間120人以上のアクティブコントリビューターがいます。
Apache Dorisは幅広いユーザーベースを持っています。TikTok、Baidu、Tencent、NetEaseなどの大手企業を含む世界中の5000社以上の本番環境で使用されています。また、金融、小売、通信から、エネルギー、製造業、医療などの業界で広く使用されています。
使用シナリオ
以下の図に示すように、さまざまなデータ統合と処理の後、データソースは通常、リアルタイムデータウェアハウスDorisとオフラインレイクハウス(Hive、Iceberg、Hudiなど)に取り込まれます。これらはOLAP分析シナリオで広く使用されています。
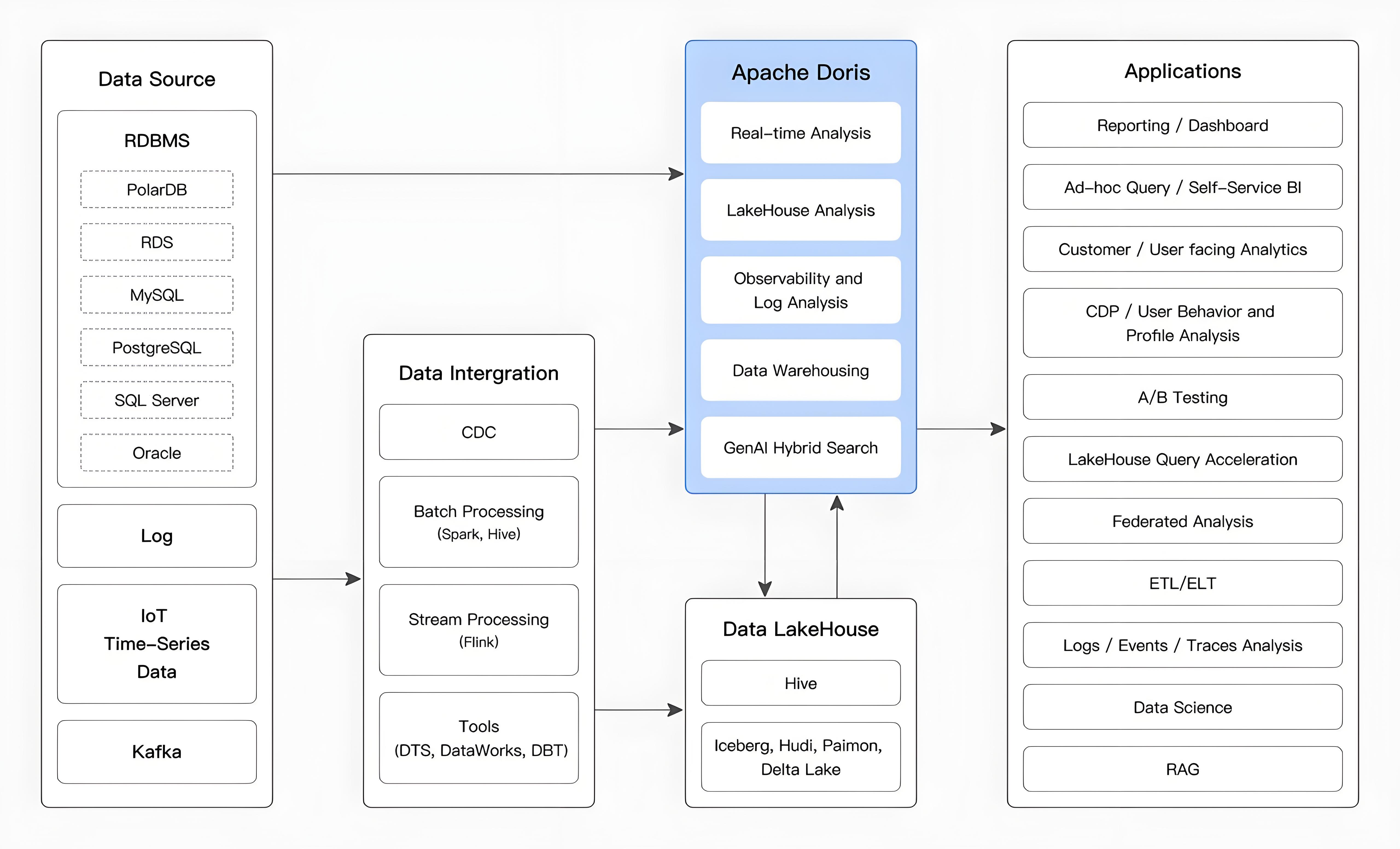
Apache Dorisは以下のシナリオで広く使用されています:
-
リアルタイムデータ分析:
-
リアルタイムレポートと意思決定:Dorisは企業の内部および外部使用のためのリアルタイム更新されたレポートとダッシュボードを提供し、自動化プロセスでのリアルタイム意思決定をサポートします。
-
アドホック分析:Dorisは多次元データ分析機能を提供し、迅速なビジネスインテリジェンス分析とアドホッククエリを可能にし、ユーザーが複雑なデータから洞察をすばやく発見するのを支援します。
-
ユーザープロファイリングと行動分析:Dorisは参加、定着、コンバージョンなどのユーザー行動を分析でき、また行動分析のための母集団洞察や群衆選択などのシナリオもサポートします。
-
-
レイクハウス分析:
-
レイクハウスクエリアクセラレーション:Dorisは効率的なクエリエンジンでレイクハウスデータクエリを加速します。
-
フェデレーテッド分析:Dorisは複数のデータソースにわたるフェデレーテッドクエリをサポートし、アーキテクチャを簡素化してデータサイロを排除します。
-
リアルタイムデータ処理:Dorisはリアルタイムデータストリームとバッチデータ処理機能を組み合わせ、高同時実行性と低レイテンシの複雑なビジネス要件のニーズを満たします。
-
-
SQLベースのオブザーバビリティ:
- ログとイベント分析:Dorisは分散システムのログとイベントのリアルタイムまたはバッチ分析を可能にし、問題の特定とパフォーマンスの最適化を支援します。
全体アーキテクチャ
Apache DorisはMySQLプロトコルを使用し、MySQL構文と高い互換性があり、標準SQLをサポートします。ユーザーはさまざまなクライアントツールを通じてApache Dorisにアクセスでき、BIツールとシームレスに統合されます。Apache Dorisをデプロイする際、ハードウェア環境とビジネスニーズに基づいて、ストレージ・コンピュート統合アーキテクチャまたはストレージ・コンピュート分離アーキテクチャを選択できます。
ストレージ・コンピュート統合アーキテクチャ
Apache Dorisのストレージ・コンピュート統合アーキテクチャは合理化されており、保守が容易です。以下の図に示すように、2種類のプロセスのみで構成されています:
-
Frontend (FE): 主にユーザーリクエストの処理、クエリ解析と計画、メタデータ管理、ノード管理タスクを担当します。
-
Backend (BE): 主にデータストレージとクエリ実行を担当します。データはシャードに分割され、BEノード全体に複数のレプリカで保存されます。
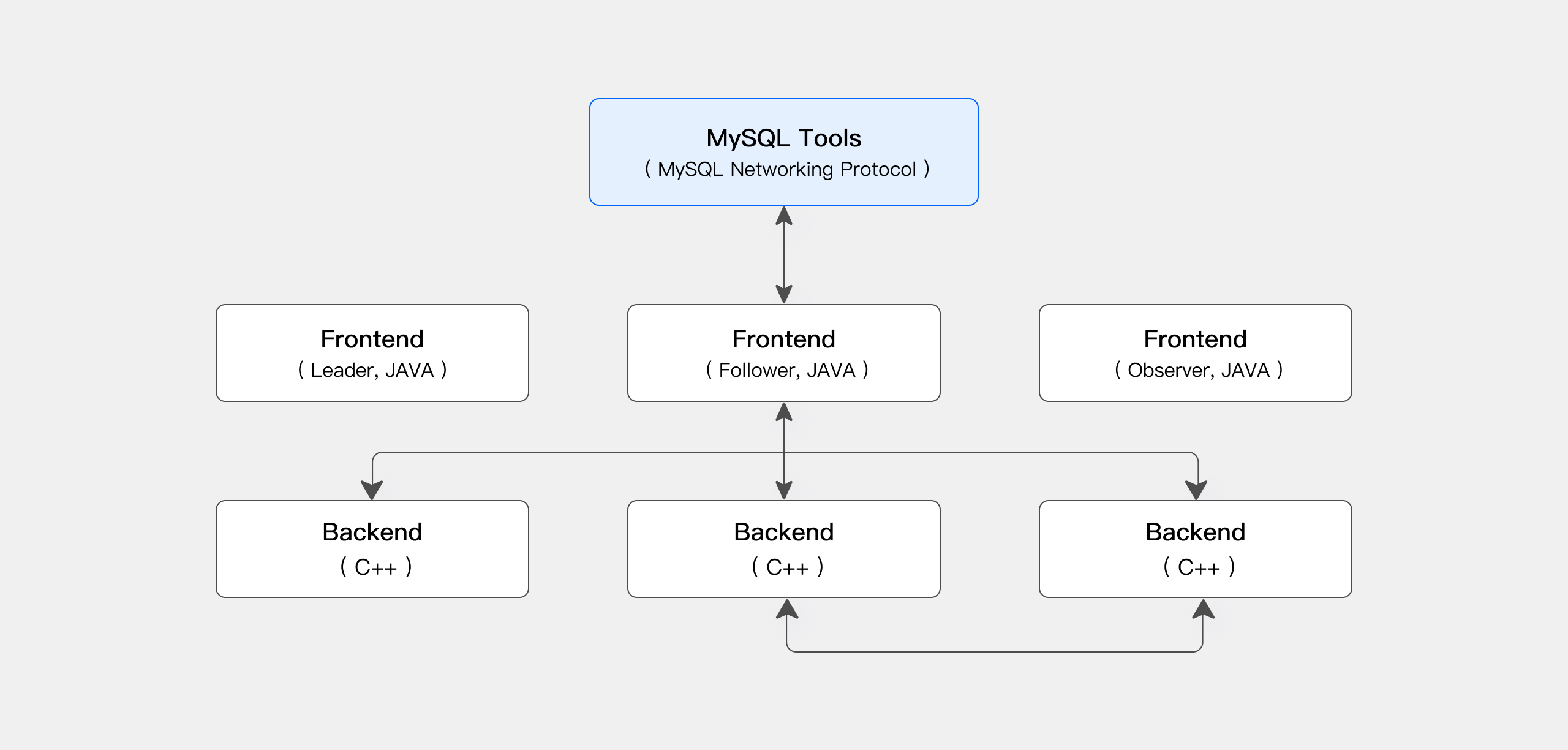
本番環境では、災害復旧のために複数のFEノードをデプロイできます。各FEノードはメタデータの完全なコピーを保持します。FEノードは3つの役割に分かれています:
| 役割 | 機能 |
|---|---|
| Master | FE Masterノードはメタデータの読み書き操作を担当します。Masterでメタデータの変更が発生すると、BDB JEプロトコルを介してFollowerまたはObserverノードに同期されます。 |
| Follower | Followerノードはメタデータの読み取りを担当します。Masterノードが失敗した場合、Followerノードが新しいMasterとして選択されます。 |
| Observer | Observerノードはメタデータの読み取りを担当し、主にクエリ同時実行性を向上させるために使用されます。クラスターリーダーシップ選挙には参加しません。 |
FEとBEプロセスの両方が水平スケーラブルであり、単一クラスターで数百台のマシンと数十ペタバイトのストレージ容量をサポートできます。FEとBEプロセスは一貫性プロトコルを使用して、サービスの高可用性とデータの高信頼性を確保します。ストレージ・コンピュート統合アーキテクチャは高度に統合されており、分散システムの運用複雑性を大幅に削減します。
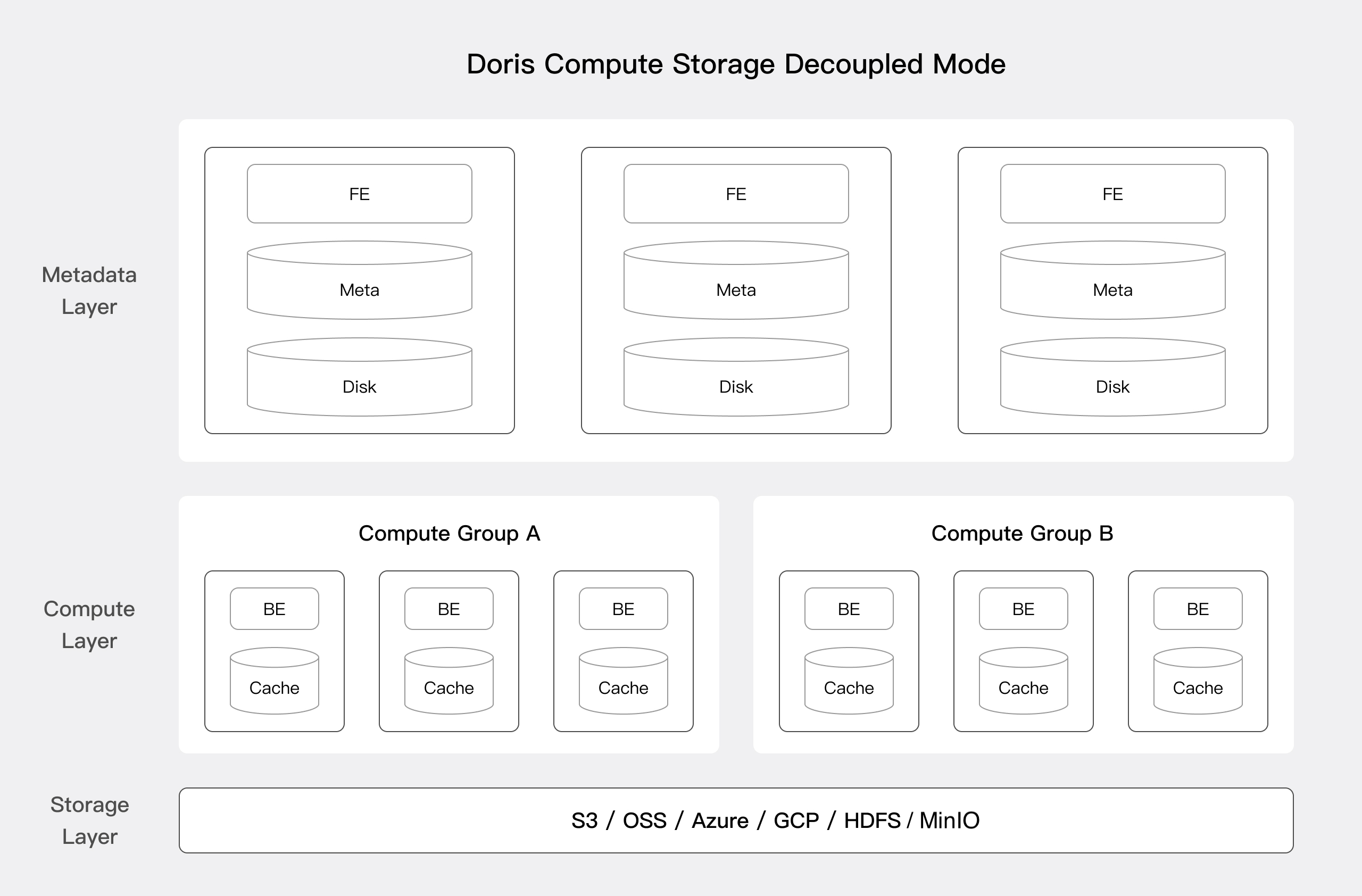
コンピュート・ストレージ分離
バージョン3.0から、コンピュート・ストレージ分離デプロイメントアーキテクチャを選択できます。Apache Dorisのコンピュート・ストレージ分離バージョンは、統一された共有ストレージレイヤーをデータストレージスペースとして利用します。ストレージと計算を分離することで、ユーザーはストレージ容量と計算リソースを独立してスケールでき、それによって最適なパフォーマンスとコスト効率を実現します。以下の図に示すように、コンピュート・ストレージ分離アーキテクチャは3つのレイヤーに分かれています:
-
メタデータレイヤー:メタデータレイヤーは主にリクエストプランニング、クエリ解析と計画、およびメタデータストレージと管理を担当します。
-
コンピュートレイヤー:コンピュートレイヤーは複数のコンピュートグループで構成され、それぞれが独立したテナントとしてビジネス計算を処理できます。各コンピュートグループ内には複数のステートレスBEノードがあり、BEノードはいつでも弾力的にスケールアップまたはスケールダウンできます。
-
ストレージレイヤー:ストレージレイヤーは、S3、HDFS、OSS、COS、OBS、Minio、CephなどのDorisのデータファイル(Segmentファイルと転置インデックスファイルを含む)を保存するための共有ストレージソリューションを使用できます。
Apache Dorisのコア機能
-
高可用性:Apache Dorisでは、メタデータとデータの両方が複数のレプリカで保存され、定数プロトコルを介してデータログを同期します。レプリカの過半数が書き込みを完了すると、データ書き込みが成功したと見なされ、少数のノードが失敗してもクラスターが利用可能であることを保証します。Apache Dorisは同一都市と地域間の災害復旧の両方をサポートし、デュアルクラスターマスター・スレーブモードを可能にします。一部のノードで障害が発生した場合、クラスターは自動的に故障ノードを隔離し、全体的なクラスターの可用性が影響を受けることを防ぎます。
-
高い互換性:Apache DorisはMySQLプロトコルと高い互換性があり、標準SQL構文をサポートし、ほとんどのMySQLとHive関数をカバーします。この高い互換性により、ユーザーは既存のアプリケーションとツールをシームレスに移行・統合できます。Apache DorisはMySQLエコシステムをサポートし、ユーザーがMySQL Clientツールを使用してDorisに接続し、より便利な運用と保守を可能にします。また、BIレポートツールとデータ転送ツールのMySQLプロトコル互換性をサポートし、データ分析とデータ転送プロセスにおける効率と安定性を確保します。
-
リアルタイムデータウェアハウス:Apache Dorisに基づいて、リアルタイムデータウェアハウスサービスを構築できます。Apache Dorisは秒レベルのデータ取り込み機能を提供し、上流のオンライントランザクションデータベースからの増分変更を数秒以内にDorisにキャプチャします。ベクトル化エンジン、MPPアーキテクチャ、Pipeline実行エンジンを活用して、Dorisはサブセカンドのデータクエリ機能を提供し、それによって高性能、低レイテンシのリアルタイムデータウェアハウスプラットフォームを構築します。
-
統合レイクハウス:Apache Dorisは、データレイクやリレーショナルデータベースなどの外部データソースに基づいて統合レイクハウスアーキテクチャを構築できます。Doris統合レイクハウスソリューションは、データレイクとデータウェアハウス間のシームレスな統合と自由なデータフローを可能にし、ユーザーがデータウェアハウス機能を直接利用してデータレイクのデータ分析問題を解決し、同時にデータレイクデータ管理機能を十分に活用してデータ価値を向上させるのを支援します。
-
柔軟なモデリング:Apache Dorisは、ワイドテーブルモデル、事前集約モデル、スター/スノーフレークスキーマなど、さまざまなモデリングアプローチを提供します。データインポート中に、FlinkやSparkなどのコンピュートエンジンを通じてデータをワイドテーブルに平坦化してDorisに書き込むか、データを直接Dorisにインポートし、ビュー、マテリアライズドビュー、またはリアルタイム多テーブル結合を通じてデータモデリング操作を実行できます。
技術概要
Dorisは効率的なSQLインターフェースを提供し、MySQLプロトコルと完全に互換性があります。そのクエリエンジンはMPP(Massively Parallel Processing)アーキテクチャに基づいており、複雑な分析クエリを効率的に実行し、低レイテンシのリアルタイムクエリを実現できます。データエンコーディングと圧縮のための列型ストレージテクノロジーを通じて、クエリパフォーマンスとストレージ圧縮率を大幅に最適化します。
インターフェース
Apache DorisはMySQLプロトコルを採用し、標準SQLをサポートし、MySQL構文と高い互換性があります。ユーザーはさまざまなクライアントツールを通じてApache Dorisにアクセスし、Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Supersetを含むがこれに限定されないBIツールとシームレスに統合できます。Apache DorisはMySQLプロトコルをサポートする任意のBIツールのデータソースとして機能できます。
ストレージエンジン
Apache Dorisは列型ストレージエンジンを持ち、列単位でデータをエンコード、圧縮、読み取りします。これにより非常に高いデータ圧縮率を実現し、不要なデータスキャンを大幅に削減し、IOとCPUリソースをより効率的に使用できます。
Apache Dorisは、データスキャンを最小化するためのさまざまなインデックス構造をサポートします:
-
ソート複合キーインデックス:ユーザーは最大3つの列を指定して複合ソートキーを形成できます。これは効果的にデータをプルーニングし、高同時実行性のレポートシナリオをより良くサポートできます。
-
Min/Maxインデックス:これは数値型の等価性と範囲クエリで効果的なデータフィルタリングを可能にします。
-
BloomFilterインデックス:これは高カーディナリティ列の等価フィルタリングとプルーニングに非常に効果的です。
-
転置インデックス:これは任意のフィールドの高速検索を可能にします。
Apache Dorisはさまざまなデータモデルをサポートし、異なるシナリオに対して最適化しています:
-
詳細モデル(Duplicate Key Model): ファクトテーブルの詳細ストレージ要件を満たすように設計された詳細データモデル。
-
Primary Key Model(Unique Key Model): 一意キーを保証し、同じキーを持つデータは上書きされ、行レベルのデータ更新を可能にします。
-
Aggregate Model(Aggregate Key Model): 同じキーを持つ値列をマージし、事前集約を通じてパフォーマンスを大幅に向上させます。
Apache Dorisは強い一貫性を持つ単一テーブルマテリアライズドビューと非同期でリフレッシュされる多テーブルマテリアライズドビューもサポートします。単一テーブルマテリアライズドビューはシステムによって自動的にリフレッシュされ、保守され、ユーザーの手動介入を必要としません。多テーブルマテリアライズドビューは、クラスター内スケジューリングまたは外部スケジューリングツールを使用して定期的にリフレッシュでき、データモデリングの複雑性を削減します。
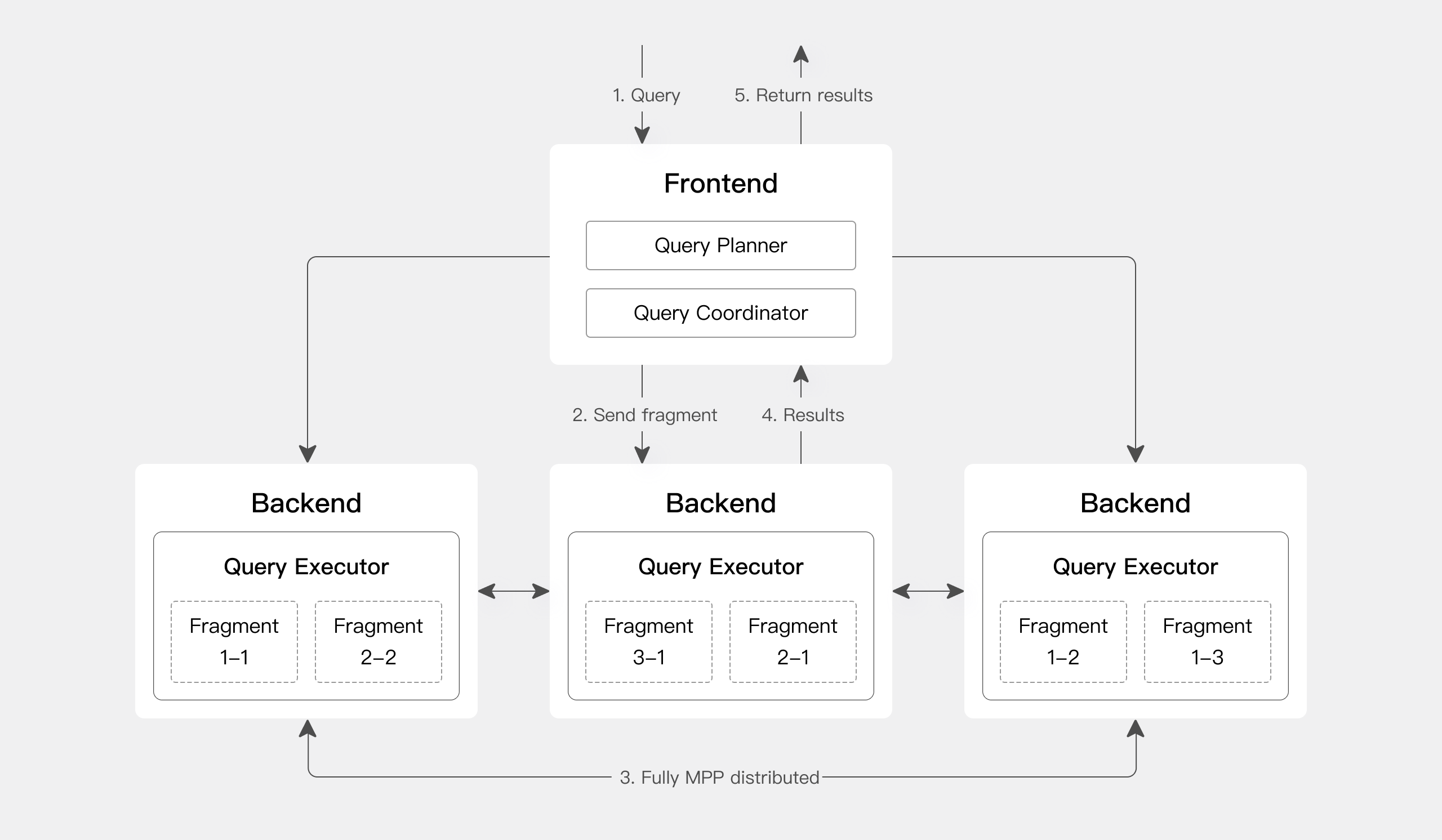
クエリエンジン
Apache DorisはMPPベースのクエリエンジンを持ち、ノード間およびノード内での並列実行を行います。大きなテーブルの複雑なクエリをより良く処理するために、分散シャッフル結合をサポートします。
Apache Dorisのクエリエンジンは完全にベクトル化されており、すべてのメモリ構造が列型フォーマットでレイアウトされています。これにより仮想関数呼び出しを大幅に削減し、キャッシュヒット率を向上させ、SIMD命令を効率的に使用できます。Apache Dorisは非ベクトル化エンジンと比較して、ワイドテーブル集約シナリオで5〜10倍高いパフォーマンスを提供します。
Apache Dorisはアダプティブクエリ実行技術を使用して、ランタイム統計に基づいて実行計画を動的に調整します。例えば、ランタイムフィルターを生成してプローブ側にプッシュできます。具体的には、プローブ側の最下位レベルのスキャンノードにフィルターをプッシュし、処理するデータ量を大幅に削減し、結合パフォーマンスを向上させます。Apache DorisのランタイムフィルターはIn/Min/Max/Bloom Filterをサポートします。
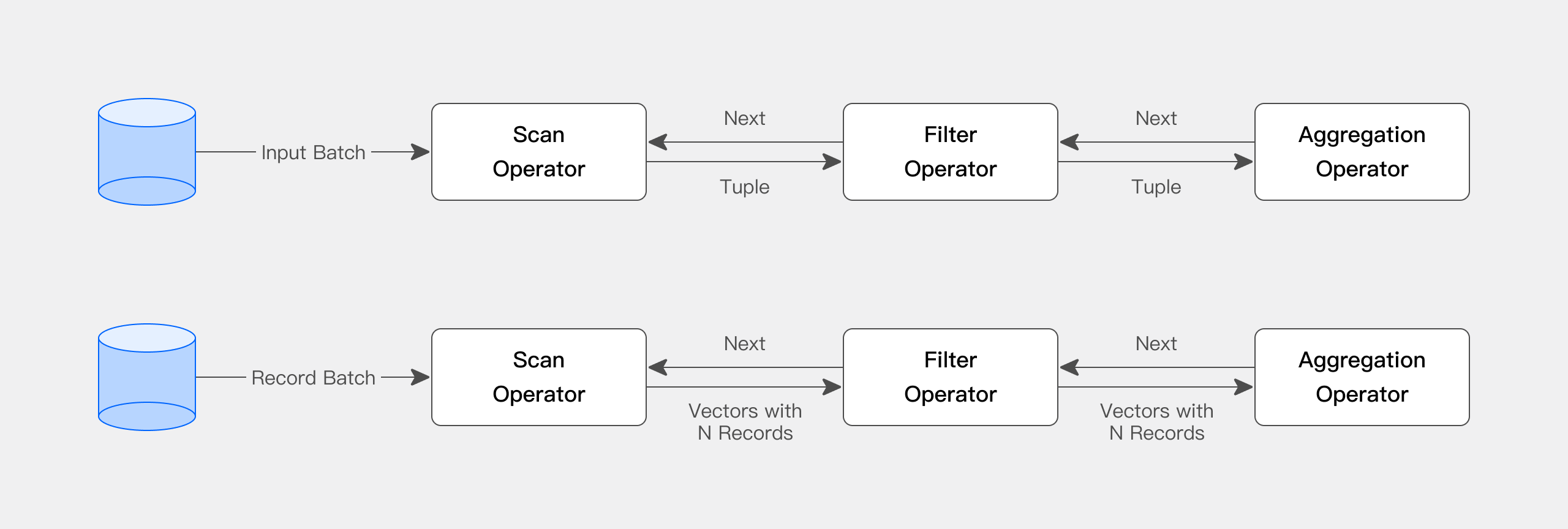
Apache DorisはPipeline実行エンジンを使用し、クエリを複数のサブタスクに分割して並列実行し、マルチコアCPU機能を完全に活用します。同時に、クエリスレッドの数を制限することでスレッド爆発問題に対処します。Pipeline実行エンジンはデータのコピーと共有を削減し、ソートと集約操作を最適化し、それによってクエリ効率とスループットを大幅に向上させます。
オプティマイザーに関して、Apache DorisはCBO(Cost-Based Optimizer)、RBO(Rule-Based Optimizer)、HBO(History-Based Optimizer)の組み合わせ最適化戦略を採用しています。RBOは定数折りたたみ、サブクエリリライト、述語プッシュダウンなどをサポートします。CBOは結合リオーダリングやその他の最適化をサポートします。HBOは履歴クエリ情報に基づいて最適な実行計画を推奨します。これらの複数の最適化措置により、Dorisがさまざまなタイプのクエリにわたって高性能なクエリ計画を列挙できることを保証します。