How Tencent Music saved 80% in costs by migrating from Elasticsearch to Apache Doris
As a long-time user of Apache Doris, Tencent Music Entertainment (NYSE: TME) has undergone four generations of data platform evolution, with the Doris community actively supporting its transformation. From replacing ClickHouse as the analytical engine to gradually offloading Elasticsearch's functionalities, TME has now taken a big step—fully replacing Elasticsearch with Doris as its unified search engine. They can handle full-text search, audience segmentation, and aggregation analysis directly within Doris. By combining their self-developed SuperSonic with AI-powered natural language processing, they can perform data analytics through simple, conversational queries. The shift from Elasticsearch to Apache Doris has slashed their storage costs by 80% while boosting write performance by 4x. In this article, we dive into TME's journey, uncovering key insights that can serve as a blueprint for others navigating similar transitions.
What they do
The TME content library provides two types of functionality:
- Search: Quickly locate artists, songs, and other textual data based on flexible query conditions.
- Tag-based segmentation: Filter data based on specific tags and criteria among billions of records and deliver sub-second query responses
A hybrid solution: Elasticsearch + Apache Doris
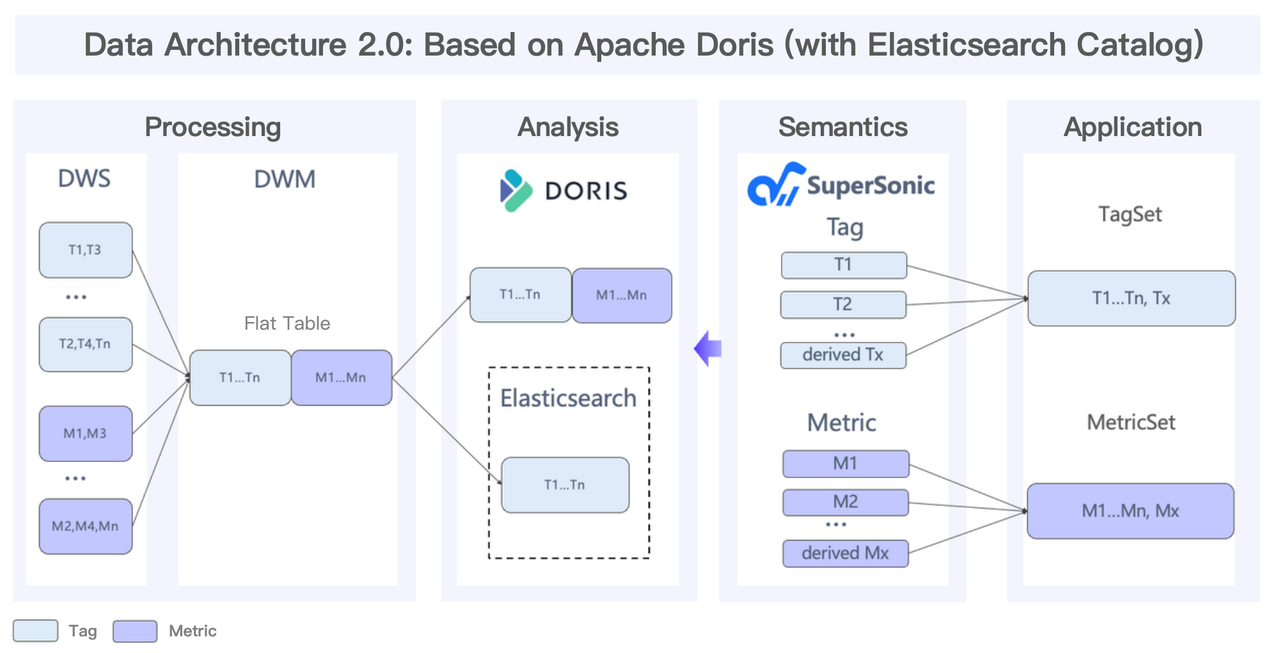
TME previously used both Elasticsearch and Apache Doris in its content library platform to leverage the strengths from both:
- Elasticsearch excelled in full-text search. It can quickly match specific keywords or phrases using inverted indexing while supporting indexing of all fields and flexible filtering conditions. However, it struggled with data aggregation, lacked support for complex queries like JOINs, and had high storage overhead.
- Apache Doris offered efficient OLAP capabilities for complex analytical queries while optimizing storage through high compression rates, but before the release of Apache Doris 2.0, it had limited search capabilities due to the absence of inverted index.
That's why TME built a hybrid architecture. In this setup, Elasticsearch handled full-text search and tag-based segmentation, while Apache Doris powered OLAP analytics. With Doris' Elasticsearch catalog, data in Elasticsearch can be queried directly through Doris, creating a unified query interface for seamless data retrieval.
Despite the advantages of the hybrid architecture, TME encountered several challenges during its implementation:
- High storage costs: Elasticsearch continued to consume huge storage space.
- Write performance bottlenecks: As data volumes grew, the write pressure on the Elasticsearch cluster intensified. Full data writes were taking over 10 hours, nearing the business's operational limits.
- Architectural complexity: The multi-component architecture meant complex maintenance, extra costs due to redundant data storage, and higher risk of data inconsistency.
A unified solution based on Apache Doris
In version 2.0, Apache Doris introduced inverted index and started to support full-text search. This release drove TME to consider entrusting Doris with the full scope of full-text search, tag-based segmentation, and aggregation analysis tasks.
What enables Doris to fully replace Elasticsearch?
- In terms of full-text search, Doris accelerates standard equality and range queries (
=,!=,>,>=,<,<=) and supports comprehensive text field searches, including tokenization for English, Chinese and Unicode, multi-keyword searches (MATCH_ANY,MATCH_ALL), phrase searches (MATCH_PHRASE,MATCH_PHRASE_PREFIX,MATCH_PHRASE_REGEXP), slop in phrase, and multi-field searches (MULTI_MATCH). It improves performance by orders of magnitude compared to traditional databases usingLIKE-based fuzzy matching. - As for inverted index, Doris implements it directly within the database kernel. Inverted indexing in Doris is seamlessly integrated with SQL syntax and supports any logical combinations for
AND,OR, andNOToperations, so it allows for complex filtering and search queries. This is an example query involving five filtering conditions: full-text (title MATCH 'love' OR description MATCH_PHRASE 'true love'), date range filtering (dt BETWEEN '2024-09-10 00:00:00' AND '2024-09-10 23:59:59'), numeric range filtering (rating > 4), and equality check on strings (country = 'Canada'). These conditions are combined into a single SQL query, after which results are grouped byactorand sorted by the highest count.
SELECT actor, count() as cnt
FROM table1
WHERE dt BETWEEN '2024-09-10 00:00:00' AND '2024-09-10 23:59:59'
AND (title MATCH 'love' OR description MATCH_PHRASE 'true love')
AND rating > 4
AND country = 'Canada'
GROUP BY actor
ORDER BY cnt DESC LIMIT 100;
This is the data platform after TME transitioned from a hybrid Elasticsearch + Doris architecture to a unified Doris solution.
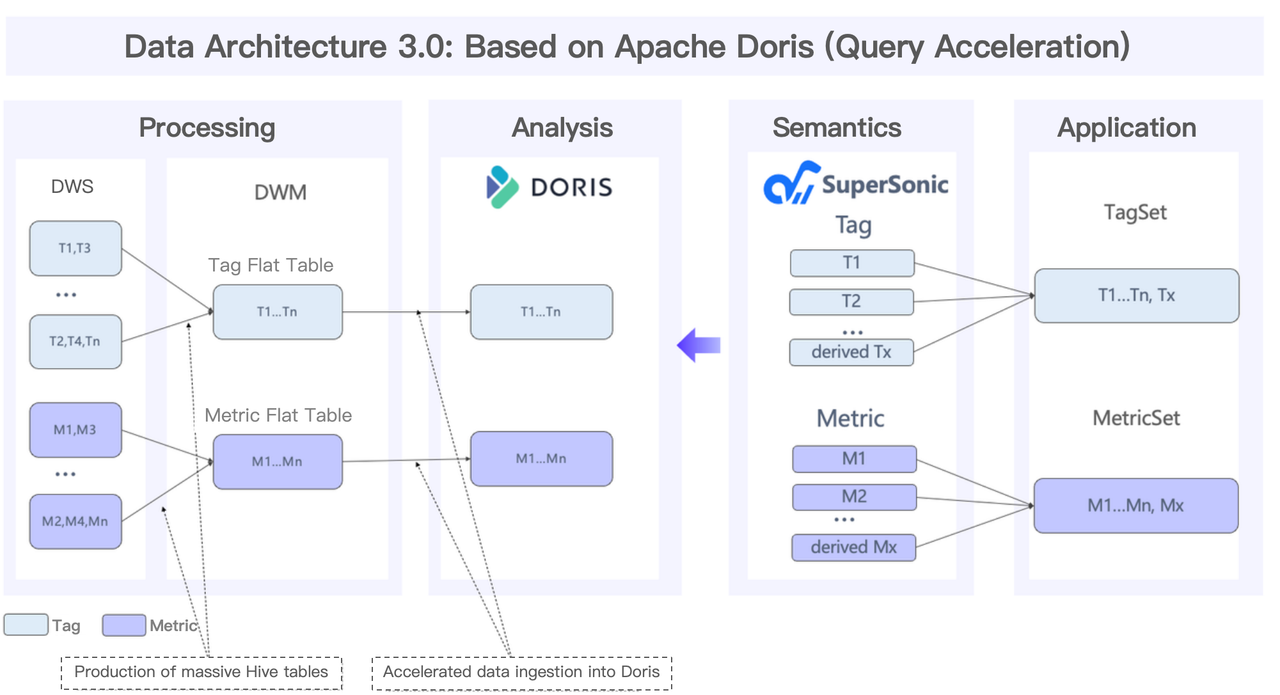
With this upgrade, users can now experience:
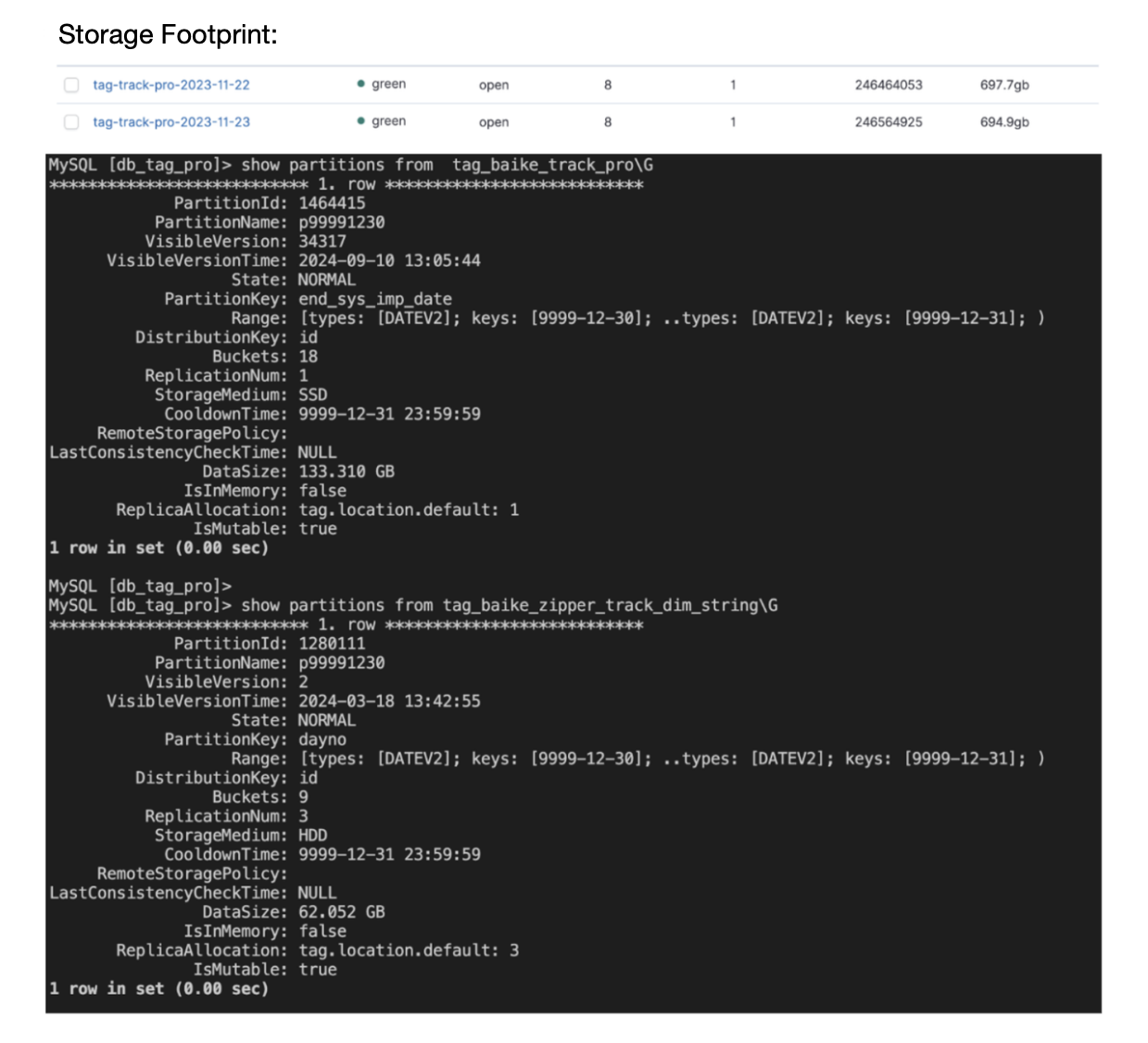
- A big cost reduction: Doris now handles both search and analytical workloads, leading to an 80% reduction in operational costs. For example, a single business' daily full data previously required 697.7 GB in Elasticsearch but now only takes 195.4 GB in Doris.
- Improved performance: Data ingestion time was cut down from over 10 hours to under 3 hours, making Doris' write performance 4x faster than Elasticsearch. Additionally, Doris supports complex custom tag-based queries, enabling previously impractical analytics and significantly enhancing user experience.
- Simplified architecture: With a unified Doris-based architecture, TME now maintains a single technology stack and eliminates data inconsistency issues
The transition to a Doris-only architecture required several key design optimizations. In the following sections, we'll dive deeper into the technical strategies and lessons learned from this migration.
The game changer: Inverted Index
To optimize storage, TME adopts a dimension table + fact table model to efficiently handle search and analytics workloads:
- Dimension table: Built using the Primary Key model, dimension tables are can be easily updated via the partial column update feature of Doris. These tables are meant for both searching and tag-based segmentation.
- Fact table: Designed with the Aggregate model, this table stores daily metric data. Given the high data volume and the independence of daily datasets, a new partition is created every day to enhance query performance and manageability.
To ensure a seamless transition from Elasticsearch to Apache Doris, TME designs the table schemas and indexes based on Doris' inverted index docs. The mapping follows these key principles:
- Elasticsearch's
Keywordtype maps to Doris'Varchar/Stringtype with non-tokenized inverted indexing (USING INVERTED). - Elasticsearch's
Texttype maps to Doris'Varchar/Stringtype with tokenized inverted indexing (USING INVERTED PROPERTIES("parser" = "english/unicode")).
CREATE TABLE `tag_baike_zipper_track_dim_string` (
`dayno` date NOT NULL COMMENT 'date',
`id` int(11) NOT NULL COMMENT 'id',
`a4` varchar(65000) NULL COMMENT 'song_name',
`a43` varchar(65000) NULL COMMENT 'zyqk_singer_id',
INDEX idx_a4 (`a4`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true") COMMENT '',
INDEX idx_a43 (`a43`) USING INVERTED PROPERTIES("parser" = "english") COMMENT ''
) ENGINE=OLAP
UNIQUE KEY(`dayno`, `id`)
COMMENT 'OLAP'
PARTITION BY RANGE(`dayno`)
(PARTITION p99991230 VALUES [('9999-12-30'), ('9999-12-31')))
DISTRIBUTED BY HASH(`id`) BUCKETS auto
PROPERTIES (
...
);
Before enabling inverted index in Doris:
Take the following complex query as an example: Without inverted indexing, it was slow and took minutes to return results.
-- like (Low performance):
SELECT * FROM db_tag_pro.tag_track_pro_3 WHERE
dayno='2024-08-01' AND ( concat('#',a4,'#') like '%#I'm so busy dancing#%'
or concat('#',a43,'#') like '%#1000#%')
-- explode (Low performance and often triggers ERROR 1105 (HY000)):
SELECT *
FROM (
SELECT tab1.*,a4_single,a43_single FROM (
SELECT *
FROM db_tag_pro.tag_track_pro_3
WHERE dayno='2024-08-01'
) tab1
lateral view explode_split(a4, '#') tmp1 as a4_single
lateral view explode_split(a43, '#') tmp2 as a43_single
) tab2
where a4_single='I'm so busy dancing' or a43_single='1000'
After enabling inverted index in Doris:
The query response times reduces from minutes to just seconds. A tip is to set store_row_column to enable row-based storage. This optimizes select* queries that reads all columns from a table.
-- Retrieve the corresponding ID from the dimension table
SELECT id FROM db_tag_pro.tag_baike_zipper_track_dim_string WHERE
( a4 MATCH_PHRASE 'I'm so busy dancing' OR a43 MATCH_ALL '1000' ) AND dayno ='2024-08-01'
-- Fetch the detailed data from the fact table based on the ID
SELECT * FROM db_tag_pro.tag_baike_track_pro WHERE id IN ( 563559286 )
Moreover, Apache Doris overcomes a key limitation found in Elasticsearch—handling overly long SQL queries that previously failed due to length constraints. Doris supports longer and more complex queries with ease. Additionally, using Doris as the unified engine means that users can leverage materialized views and BITMAP data type to further optimize intermediate query results. This eliminates the need for cross-engine synchronization.
Multi-service resource isolation
To ensure a cost-effective and seamless user experience, TME leverages Doris' resource isolation mechanism for efficient workload management across different business scenarios.
- Layer 1: Physical isolation (Resource Group) They divide the cluster into two Resource Groups to serve difference workloads: Core and Normal. The Core group is dedicated to mission-critical tasks such as content search and tag-based segmentation, while the Normal group handles general-purpose queries. This node-level physical isolation ensures that high-priority operations remain unaffected by other workloads.
- Layer 2: Logical isolation (Workload Group) Within each physically isolated Resource Group, resources are further divided into Workload Groups. For example, TME creates multiple Workload Groups within the Normal resource group, and assign a default Workload Group to each user. In this way, they prevent any single user from monopolizing cluster resources.
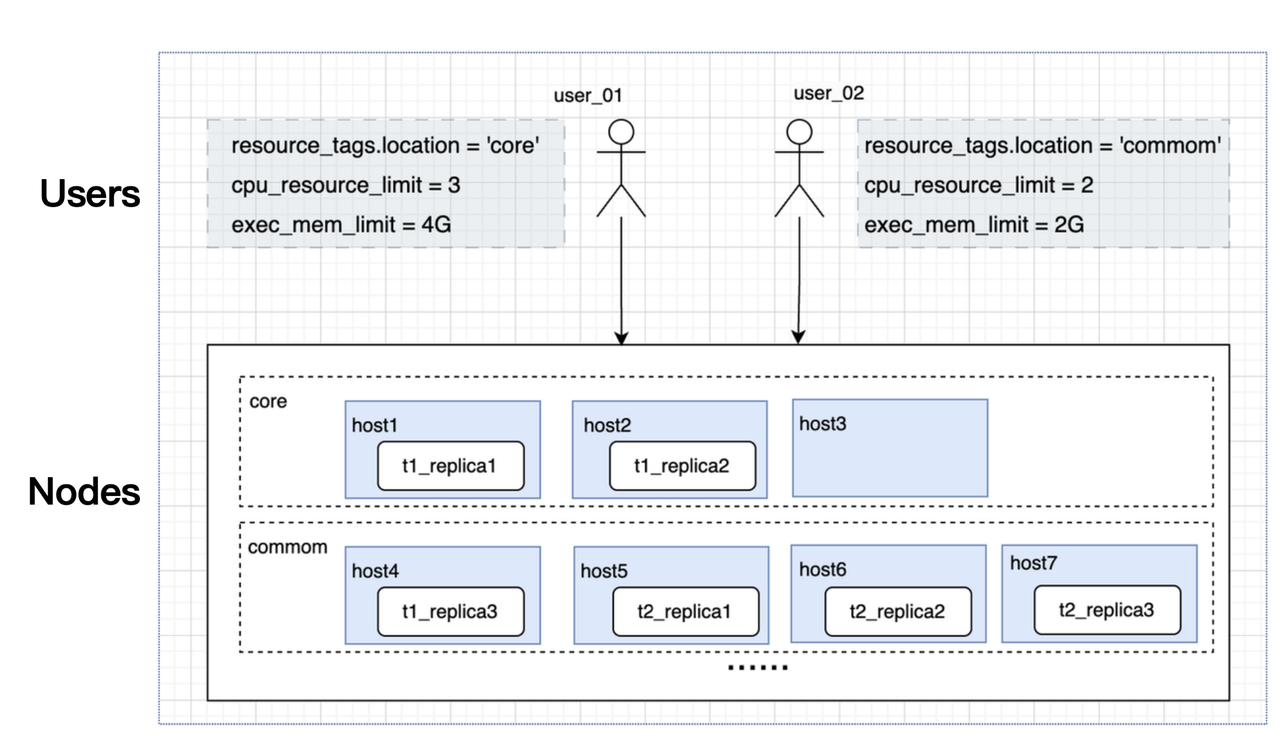
These resource isolation mechanisms improve system stability. In TME's case, the frequency of alerts has reduced from over 20 times per day to single digits per month. The team can now focus more on system optimization and performance improvements rather than constant firefighting.
A seamless migration
TME implements the migration via their self-developed SuperSonic project, which has a built-in Headless BI feature to simplify the process. All they need is to convert the queries written in Elasticsearch's Domain Specific Language (DSL) into SQL statements, and switch the data sources for pre-defined metrics and tags.
The idea of Headless BI is to decouple data modeling, management, and consumption. With it, business analysts can define metrics and tags directly on the Headless BI platform without worrying about the underlying data sources. Because Headless BI abstracts away differences between various data storage and analytics engines, users can experience a transparent, frictionless migration without disruptions.
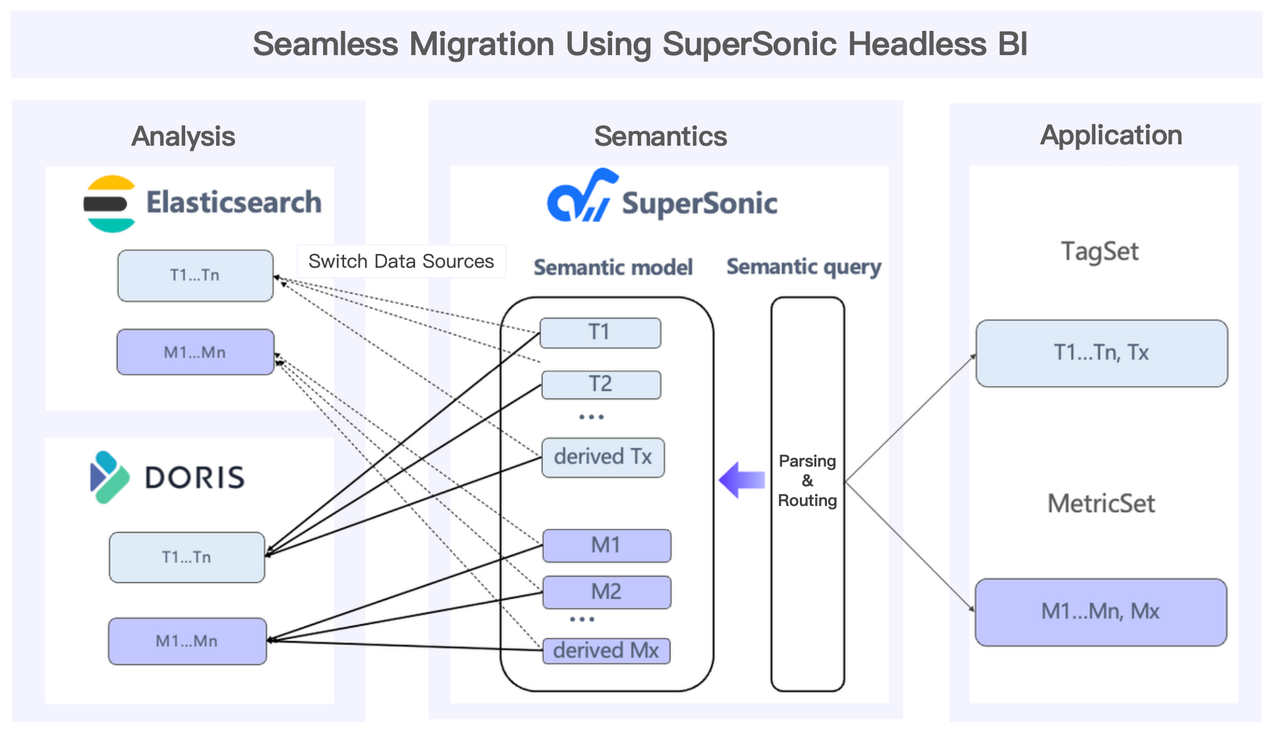
The Headless BI enables seamless data source migration and largely simplifies data management and querying. SuperSonic takes this a step further by integrating Chat BI capabilities with Headless BI, so users can perform unified data governance and data analysis using natural language. Originally developed and battle-tested in-house by TME, the SuperSonic platform is now open source: https://github.com/tencentmusic/supersonic
What's next
The migration from Elasticsearch to Apache Doris has yielded impressive gains. Write performance has improved 4x and storage usage has dropped by 72%, while the overall operational costs have been cut by up to 80%.
By replacing its Elasticsearch cluster with Doris, TME has unified its content library's search and analytics engines into a single, streamlined platform. The system now supports complex custom tag-based segmentation with sub-second response. The next-phase plan of TME is to explore broader use cases of Apache Doris and prepare to adopt the compute-storage decoupled mode to drive even greater cost efficiency.
For direct communication, real-world insights, and best practices, join #elasticsearch-to-doris channel in the Apache Doris community.