Doris存储文件格式优化
文件格式
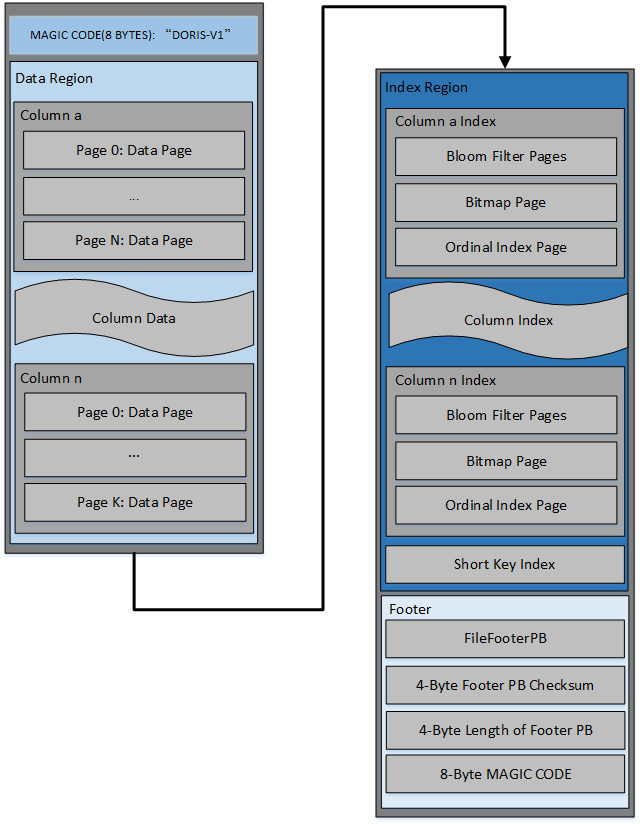
文件包括:
- 文件开始是8个字节的magic code,用于识别文件格式和版本
- Data Region:用于存储各个列的数据信息,这里的数据是按需分page加载的
- Index Region: doris中将各个列的index数据统一存储在Index Region,这里的数据会按照列粒度进行加载,所以跟列的数据信息分开存储
- Footer信息
- FileFooterPB:定义文件的元数据信息
- 4个字节的footer pb内容的checksum
- 4个字节的FileFooterPB消息长度,用于读取FileFooterPB
- 8个字节的MAGIC CODE,之所以在末位存储,是方便不同的场景进行文件类型的识别
文件中的数据按照page的方式进行组织,page是编码和压缩的基本单位。现在的page类型包括以下几种:
DataPage
DataPage分为两种:nullable和non-nullable的data page。
nullable的data page内容包括:
+----------------+
| value count |
|----------------|
| first row id |
|----------------|
| bitmap length |
|----------------|
| null bitmap |
|----------------|
| data |
|----------------|
| checksum |
+----------------+
non-nullable data page结构如下:
|----------------|
| value count |
|----------------|
| first row id |
|----------------|
| data |
|----------------|
| checksum |
+----------------+
其中各个字段含义如下:
- value count
- 表示page中的行数
- first row id
- page中第一行的行号
- bitmap length
- 表示接下来bitmap的字节数
- null bitmap
- 表示null信息的bitmap
- data
- 存储经过encoding和compress之后的数据
- 需要在数据的头部信息中写入:is_compressed
- 各种不同编码的data需要在头部信息写入一些字段信息,以实现数据的解析
- TODO:添加各种encoding的header信息
- checksum
- 存储page粒度的校验和,包括page的header和之后的实际数据
Bloom Filter Pages
针对每个bloom filter列,会在page的粒度相应的生成一个bloom filter的page,保存在bloom filter pages区域
Ordinal Index Page
针对每个列,都会按照page粒度,建立行号的稀疏索引。内容为这个page的起始行的行号到这个block的指针(包括offset和length)
Short Key Index page
我们会每隔N行(可配置)生成一个short key的稀疏索引,索引的内容为:short key->行号(ordinal)
Column的其他索引
该格式设计支持后续扩展其他的索引信息,比如bitmap索引,spatial索引等等,只需要将需要的数据写到现有的列数据后面,并且添加对应的元数据字段到FileFooterPB中
元数据定义
SegmentFooterPB的定义为:
message ColumnPB {
required int32 unique_id = 1; // 这里使用column id, 不使用column name是因为计划支持修改列名
optional string name = 2; // 列的名字, 当name为__DORIS_DELETE_SIGN__, 表示该列为隐藏的删除列
required string type = 3; // 列类型
optional bool is_key = 4; // 是否是主键列
optional string aggregation = 5; // 聚合方式
optional bool is_nullable = 6; // 是否有null
optional bytes default_value = 7; // 默认值
optional int32 precision = 8; // 精度
optional int32 frac = 9;
optional int32 length = 10; // 长度
optional int32 index_length = 11; // 索引长度
optional bool is_bf_column = 12; // 是否有bf词典
optional bool has_bitmap_index = 15 [default=false]; // 是否有bitmap索引
}
// page偏移
message PagePointerPB {
required uint64 offset; // page在文件中的偏移
required uint32 length; // page的大小
}
message MetadataPairPB {
optional string key = 1;
optional bytes value = 2;
}
message ColumnMetaPB {
optional ColumnMessage encoding; // 编码方式
optional PagePointerPB dict_page // 词典page
repeated PagePointerPB bloom_filter_pages; // bloom filter词典信息
optional PagePointerPB ordinal_index_page; // 行号索引数据
optional PagePointerPB page_zone_map_page; // page级别统计信息索引数据
optional PagePointerPB bitmap_index_page; // bitmap索引数据
optional uint64 data_footprint; // 列中索引的大小
optional uint64 index_footprint; // 列中数据的大小
optional uint64 raw_data_footprint; // 原始列数据大小
optional CompressKind compress_kind; // 列的压缩方式
optional ZoneMapPB column_zone_map; //文件级别的过滤条件
repeated MetadataPairPB column_meta_datas;
}
message SegmentFooterPB {
optional uint32 version = 2 [default = 1]; // 用于版本兼容和升级使用
repeated ColumnPB schema = 5; // 列Schema
optional uint64 num_values = 4; // 文件中保存的行数
optional uint64 index_footprint = 7; // 索引大小
optional uint64 data_footprint = 8; // 数据大小
optional uint64 raw_data_footprint = 8; // 原始数据大小
optional CompressKind compress_kind = 9 [default = COMPRESS_LZO]; // 压缩方式
repeated ColumnMetaPB column_metas = 10; // 列元数据
optional PagePointerPB key_index_page; // short key索引page
}
读写逻辑
写入
大体的写入流程如下:
- 写入magic
- 根据schema信息,生成对应的ColumnWriter,每个ColumnWriter按照不同的类型,获取对应的encoding信息(可配置),根据encoding,生成对应的encoder
- 调用encoder->add(value)进行数据写入,每隔K行,生成一个short key index entry,并且,如果当前的page满足一定条件(大小超过1M或者行数为K),就生成一个新的page,缓存在内存中。
- 不断的循环步骤3,直到数据写入完成。将各个列的数据依序刷入文件中
- 生成FileFooterPB信息,写入文件中。
相关的问题:
-
short key的索引如何生成?
- 现在还是按照每隔多少行生成一个short key的稀疏索引,保持每隔1024行生成一个short的稀疏索引,具体的内容是:short key -> ordinal
-
ordinal索引里面应该存什么?
- 存储page的第一个ordinal到page pointer的映射信息
-
不同encoding类型的page里存什么?
- 词典压缩
- plain
- rle
- bshuf
读取
- 读取文件的magic,判断文件类型和版本
- 读取FileFooterPB,进行checksum校验
- 按照需要的列,读取short key索引和对应列的数据ordinal索引信息
- 使用start key和end key,通过short key索引定位到要读取的行号,然后通过ordinal索引确定需要读取的row ranges, 同时需要通过统计信息、bitmap索引等过滤需要读取的row ranges
- 然后按照row ranges通过ordinal索引读取行的数据
相关的问题:
-
如何实现在page内部快速的定位到某一行?
page内部是的数据是经过encoding的,无法快速进行行级数据的定位。不同的encoding方式,在内部进行快速的行号定位的方案不一样,需要具体分析:
- 如果是rle编码的,需要通过解析rle的header进行skip,直到到达包含该行的那个rle块之后,再进行反解。
- binary plain encoding:会在page的中存储offset信息,并且会在page header中指定offset信息的offset,读取的时候会先解析offset信息到数组中,这样子就可以通过各个行的offset数据信息快速的定位block某一行的数据
-
如何实现块的高效读取?可以考虑将相邻的块在读取的时候进行merge,一次性读取? 这个需要在读取的时候,判断block是否连续,如果连续,就一次性的读取
编码
现有的doris存储中,针对string类型的编码,采用plain encoding的方式,效率比较低。经过对比,发现在百度统计的场景下,数据会因为string类型的编码膨胀超过一倍。所以,计划引入基于词典的编码压缩。
压缩
实现可扩展的压缩框架,支持多种压缩算法,方便后续添加新的压缩算法,计划引入zstd压缩。
TODO
- 如何实现嵌套类型?如何在嵌套类型中进行行号定位?
- 如何优化现在的ScanRange拆分导致的下游bitmap、column statistic统计等进行多次?