索引概述
Apache Doris 提供多种索引来加速查询。本文帮助你判断是否需要、以及需要哪一种索引,并提供各索引的详细链接。
从这里开始
每张表都已经拥有两种由 Doris 自动构建和维护的索引:
- 前缀索引:建立在排序键上,可加速对前导 Key 列的过滤。将你最频繁的过滤列设计为前导 Key 列即可利用它。
- ZoneMap 索引:建立在每一列上,可跳过不满足范围或等值过滤条件的数据块。
仅当上述索引无法覆盖某种查询模式时,才需要添加手动索引:
| 你的查询模式 | 推荐索引 | 使用频率 |
|---|---|---|
| 在最高频的列上过滤 | 将其设为前导 Key 列(前缀索引) | 总是优先设计 |
| 在非 Key 列上做等值或范围过滤 | 倒排索引 | 经常 |
文本 LIKE 子串匹配 | NGram BloomFilter 索引 | 有时 |
| 等值过滤且更看重索引体积而非灵活性 | BloomFilter 索引 | 很少;通常更推荐倒排索引 |
| 全文检索:关键词、短语或多字段 | 倒排索引 | 需要文本检索时 |
| 向量相似度(Top-K 最近邻) | 向量索引(ANN) | 用于 RAG、语义搜索、推荐、多媒体检索 |
如果查询慢于预期,可用 QueryProfile 查看各索引过滤掉了多少数据、耗时多少。详见各索引的专题文档。
各类索引的工作原理
Apache Doris 针对不同查询场景提供四类索引:点查索引、跳数索引、全文检索索引 与 向量索引。
场景一:满足条件的行较少(点查索引)
适用场景:精确匹配少量数据,例如根据主键查询、根据用户 ID 拉取明细。
加速原理:通过索引直接定位到满足 WHERE 条件的行,并读取这些行,避免逐行扫描。
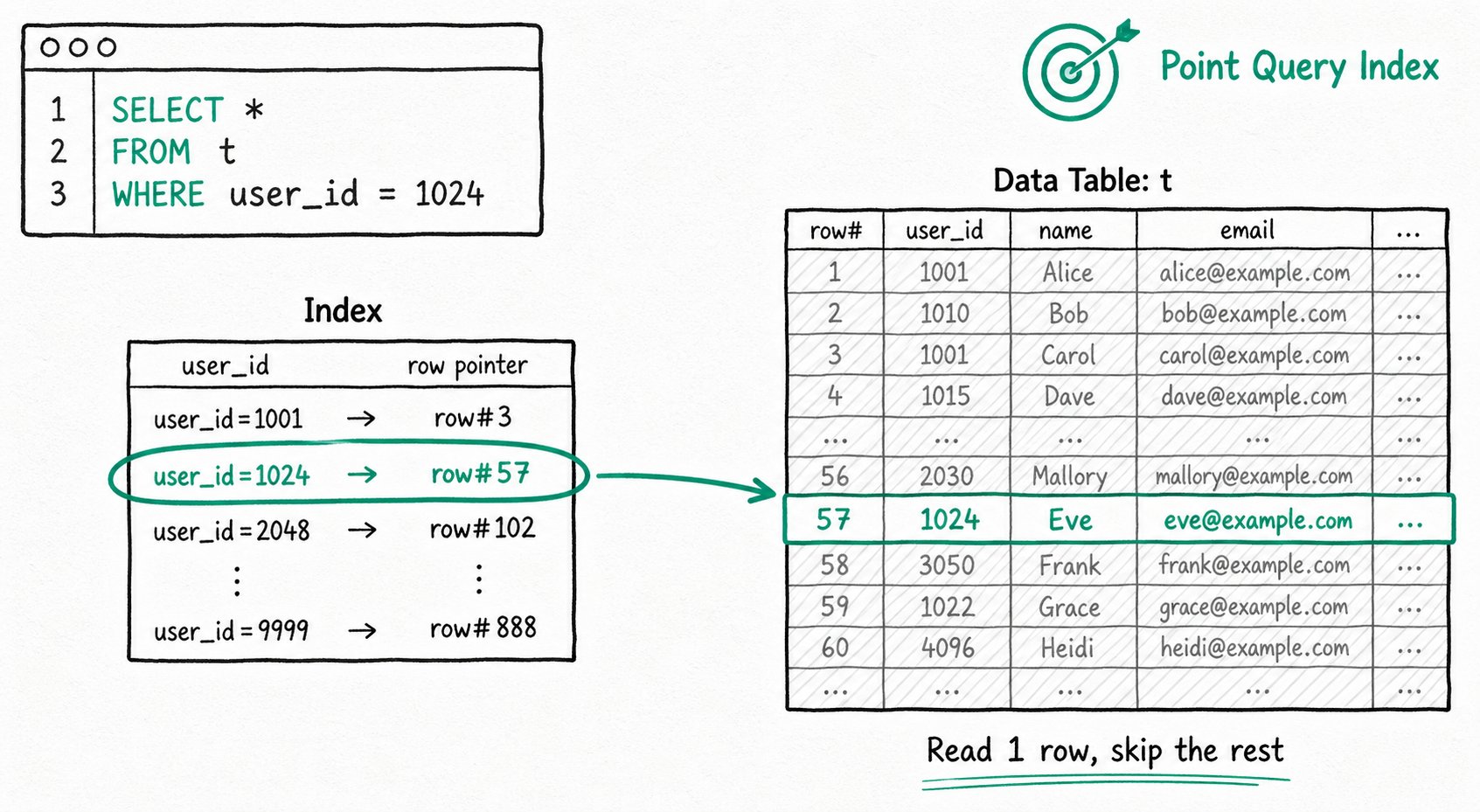
Apache Doris 提供两种点查索引:
- 前缀索引:Doris 按排序键有序存储数据,并每隔 1024 行创建一个稀疏前缀索引。每个索引项记录所在组第一行的排序列值。当查询按排序列过滤时,Doris 定位到对应的行组并从那里开始扫描。
- 倒排索引:Doris 构建一张倒排表,把每个值映射到包含它的行。等值查询时,先查到匹配的行,再只读取这些行,避免全表扫描并减少 I/O。倒排索引也能加速范围过滤和文本关键词检索;算法更复杂,但思路相同。
BITMAP 索引已被倒排索引取代。
场景二:满足条件的行较多(跳数索引)
适用场景:分析类查询,需要过滤大批量数据,例如时间范围聚合、维度筛选等。
加速原理:通过索引判断哪些数据块不满足 WHERE 条件,跳过这些数据块,只读取可能满足条件的数据块,再做一次逐行过滤得到最终结果。
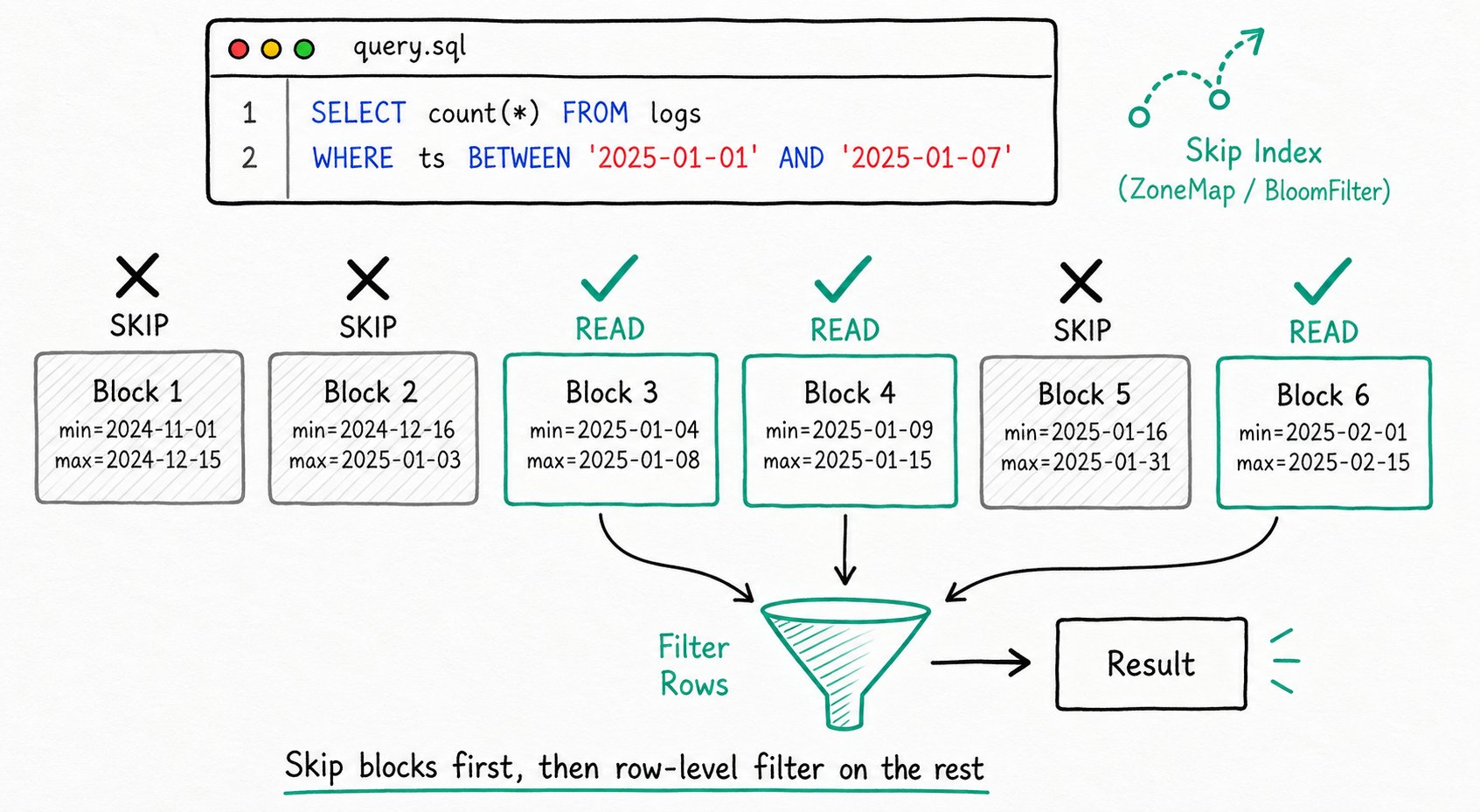
Apache Doris 提供三种跳数索引:
- ZoneMap 索引:Doris 自动为每一列维护统计信息(最小值、最大值、是否有 NULL),按数据文件(Segment)和数据块(Page)记录。对于等值、范围、IS NULL 过滤,Doris 用这些统计判断某个文件或数据块是否可能包含匹配行。若不可能,则跳过该文件或数据块,减少 I/O。
- BloomFilter 索引:Doris 将列的取值存入 BloomFilter,这种结构能以很小的存储判断某个值是否存在。等值查询时,若该值不在 BloomFilter 中,Doris 跳过对应文件或数据块,减少 I/O。
- NGram BloomFilter 索引:加速文本
LIKE查询。原理与 BloomFilter 索引类似,但存入的是文本的 NGram 分词,而非完整取值。LIKE查询时,Doris 对 pattern 做同样的分词,逐个检查 token 是否在过滤器中。只要有一个 token 缺失,该文件或数据块就无法匹配,Doris 直接跳过。
场景三:文本全文检索(倒排索引)
适用场景:日志分析、内容搜索、客服工单挖掘等需要在文本字段中按关键词、短语、模式匹配查找的场景。
加速原理:将文本通过分词器切分成词项(Term),对每个词项构建到对应行号的倒排表。查询时先对检索词做同样的分词,再从倒排表中取出包含这些词的行号集合,并按 AND/OR/NOT 等关系合并,最终直接读取这些行,避免对原文逐行扫描和正则匹配。
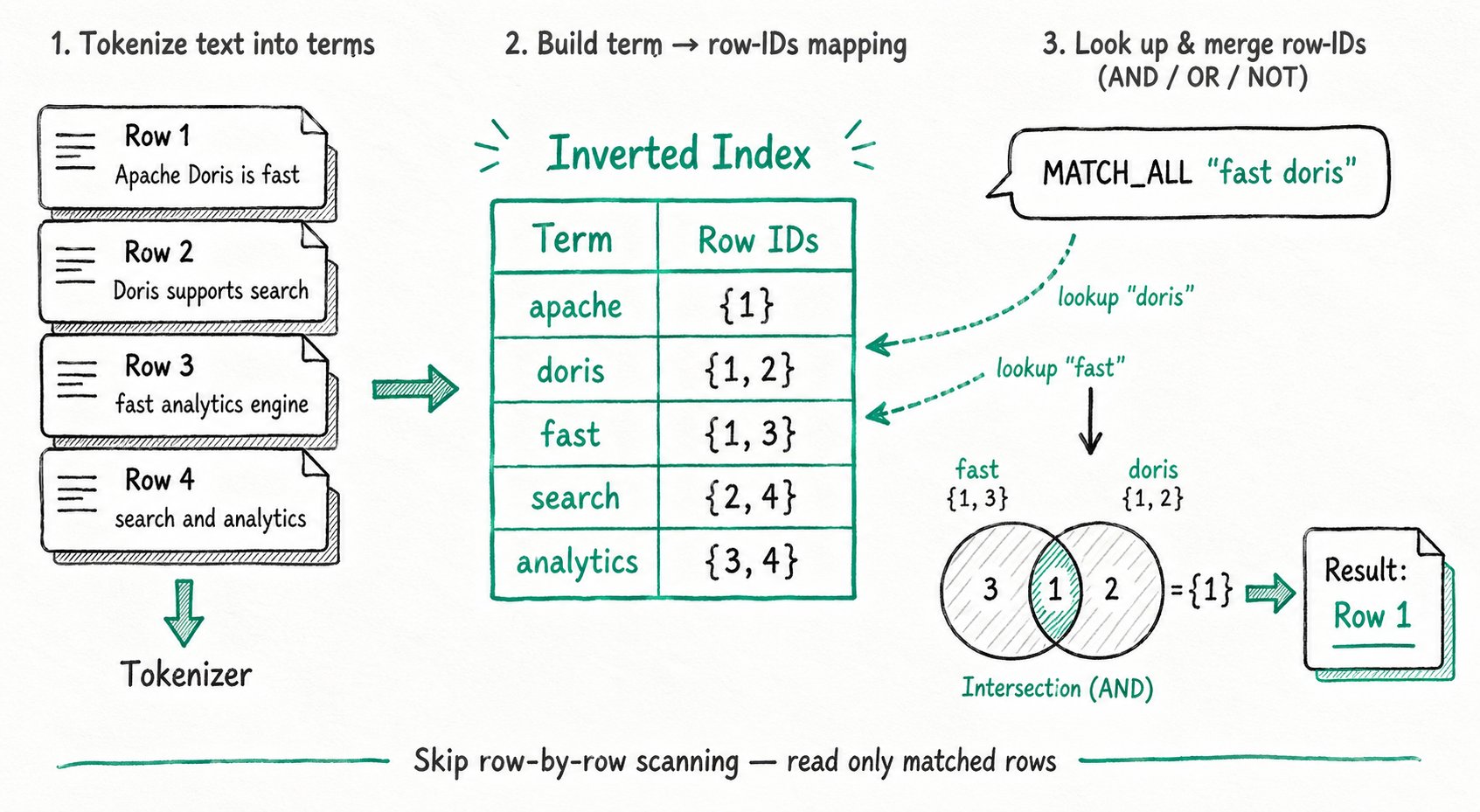
详细用法见倒排索引。Apache Doris 倒排索引支持:
- 关键词检索:
MATCH_ANY(任意一个词命中)、MATCH_ALL(多个词都命中)。 - 短语查询:
MATCH_PHRASE支持顺序敏感的短语匹配,可指定词距slop;MATCH_PHRASE_PREFIX支持短语 + 末词前缀匹配;MATCH_REGEXP支持对分词后词项做正则匹配。 - 多语言分词:内置
english、chinese、unicode、icu、basic、ik等多种分词器,覆盖中英文、混合文本与多语言场景。 - 多列联合检索:通过
multi_match函数对多个字段做 OR/AND/短语/前缀检索。 - 与普通过滤组合:与等值、范围、
IN等条件以及其他索引任意 AND/OR/NOT 组合,复用同一份倒排索引完成查询。
场景四:向量相似度检索(向量索引)
适用场景:RAG(检索增强生成)、语义搜索、推荐系统、图像 / 音频 / 视频检索等需要按向量相似度查找 Top-K 最近邻或基于距离阈值过滤的场景。
加速原理:传统方式需要将查询向量与每条数据计算一次距离,代价随数据量线性增长。向量索引(ANN,Approximate Nearest Neighbor)通过预先在向量集合上构建图(如 HNSW)或聚类(如 IVF)结构,把搜索空间限制在少量候选向量上,从而以可控的精度损失换取数量级的查询提速。
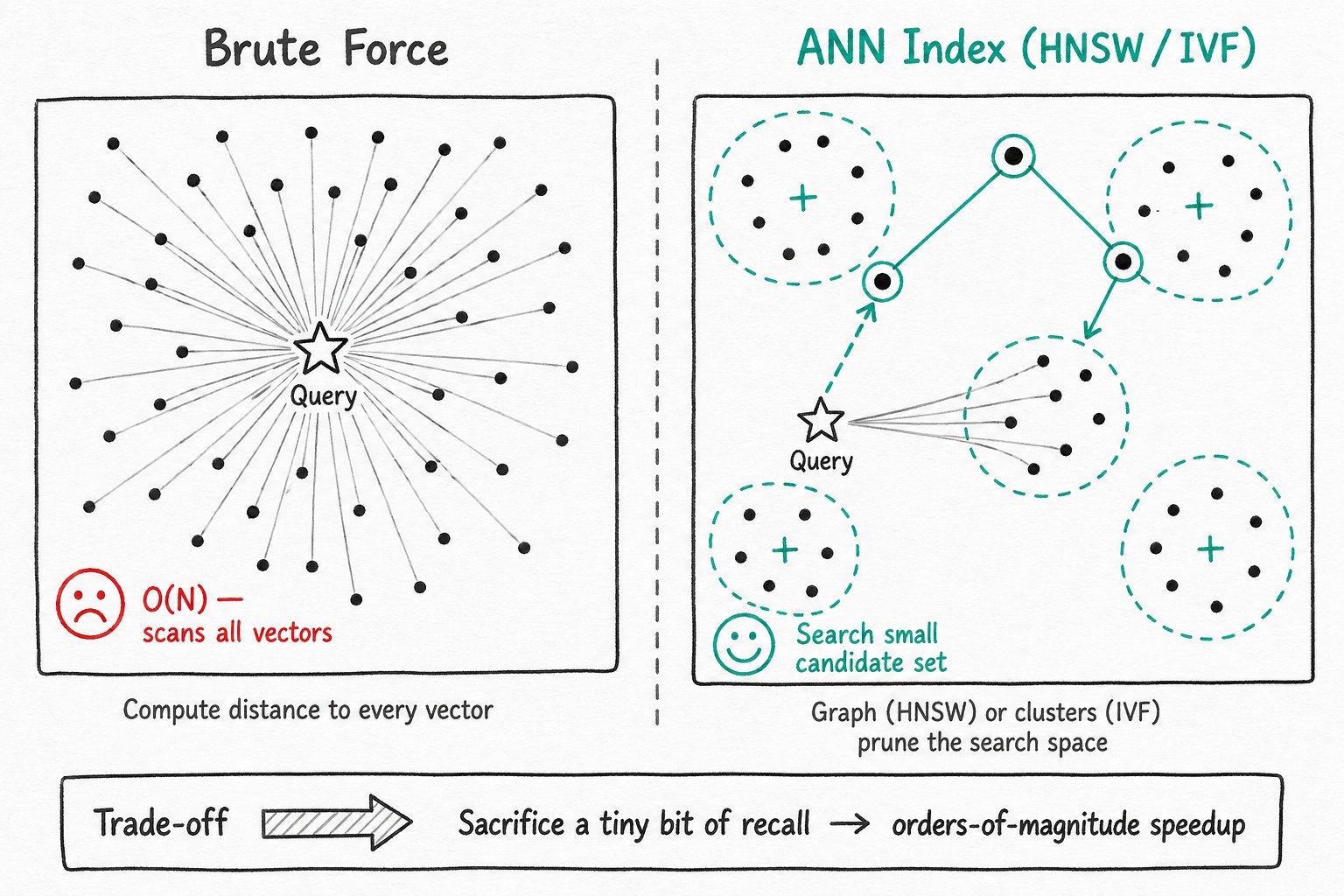
详细用法见向量索引。Apache Doris 自 4.0 版本起支持 ANN 索引,主要能力包括:
- 多种索引算法:支持
hnsw、ivf、ivf_on_disk,分别适用于内存高 QPS、内存受限、超大规模磁盘场景。 - 多种距离度量:支持
l2_distance(欧氏距离)和inner_product(内积),对向量做 L2 归一化后可等价实现 Cosine 相似度。 - TopN / 范围 / 组合查询:通过
l2_distance_approximate、inner_product_approximate实现 ANN TopN,也支持基于距离阈值的范围搜索,以及在同一 SQL 中组合 TopN 与 Range 条件。 - 与标量过滤混合检索:可与倒排索引等二级索引联动,先用结构化条件(如
MATCH_ANY 'music')过滤候选集,再在候选集上做 ANN TopN,实现“带过滤条件的向量检索”。 - 向量量化:支持
flat、sq8、sq4、pq等量化方式,在召回率与内存 / 磁盘占用之间灵活权衡。
索引管理方式
根据是否需要用户手动管理,Apache Doris 的索引可分为两类:
| 管理方式 | 索引类型 | 说明 |
|---|---|---|
| 自动维护 | 前缀索引、ZoneMap 索引 | Apache Doris 内建智能索引,无需用户管理 |
| 手动创建 | 倒排索引、BloomFilter 索引、NGram BloomFilter 索引、向量索引 | 用户根据查询场景自行选择,并手动创建、删除 |
索引特点对比
下表汇总了各类索引的优势与局限,便于快速选型:
| 类型 | 索引 | 优点 | 局限 |
|---|---|---|---|
| 点查索引 | 前缀索引 | 内置索引,性能最好 | 一个表只有一组前缀索引 |
| 点查索引 / 全文检索 | 倒排索引 | 支持分词和关键词匹配,任意列可建索引,多条件组合,持续增加函数加速 | 索引存储空间较大,与原始数据相当 |
| 跳数索引 | ZoneMap 索引 | 内置索引,索引存储空间小 | 支持的查询类型少,只支持等于、范围 |
| 跳数索引 | BloomFilter 索引 | 比 ZoneMap 更精细,索引空间中等 | 支持的查询类型少,只支持等于 |
| 跳数索引 | NGram BloomFilter 索引 | 支持 LIKE 加速,索引空间中等 | 支持的查询类型少,只支持 LIKE 加速 |
| 向量索引 | ANN 索引 | 支持向量相似度 TopN / 范围 / 组合检索,可与标量过滤联动;支持多种量化方式平衡召回与资源 | 仅适用于 Array<Float> 列且要求 NOT NULL,仅支持 DUPLICATE KEY 表模型 |
索引对运算符与函数的支持
下表列出各类索引对常用运算符和函数的加速支持情况:
| 运算符 / 函数 | 前缀索引 | 倒排索引 | ZoneMap 索引 | BloomFilter 索引 | NGram BloomFilter 索引 |
|---|---|---|---|---|---|
= | YES | YES | YES | YES | NO |
!= | YES | YES | NO | NO | NO |
IN | YES | YES | YES | YES | NO |
NOT IN | YES | YES | NO | NO | NO |
>, >=, <, <=, BETWEEN | YES | YES | YES | NO | NO |
IS NULL | YES | YES | YES | NO | NO |
IS NOT NULL | YES | YES | NO | NO | NO |
LIKE | NO | NO | NO | NO | YES |
MATCH, MATCH_* | NO | YES | NO | NO | NO |
array_contains | NO | YES | NO | NO | NO |
array_overlaps | NO | YES | NO | NO | NO |
is_ip_address_in_range | NO | YES | NO | NO | NO |
索引设计原则
数据库表的索引设计与优化跟数据特点和查询模式密切相关,需根据实际场景测试和调优。虽然没有“银弹”,Apache Doris 仍持续降低用户使用索引的难度。在实际设计时,可参考前文“从这里开始”中的决策表进行索引选择和测试。