向量量化算法调研与选型
本文从科普与工程实践的角度介绍常见向量量化算法,并结合 Apache Doris 的 ANN 使用场景给出选型建议。Apache Doris 当前以优化过的 Faiss 作为 ANN 向量索引与检索的核心实现,因此下文关于 SQ/PQ 的机制说明可以直接映射到 Doris 的实际行为。
快速导航
适用读者与对应章节:
| 我想解决的问题 | 直接跳到 |
|---|---|
| 不知道为什么需要量化 | 为什么需要向量量化 |
| 想快速选一个 quantizer | Doris 选型建议 |
| 想了解 SQ8/SQ4 的原理 | 标量量化(SQ) |
| 想了解 PQ 的原理与优势 | 乘积量化(PQ) |
| 想公平地做压测对比 | 压测注意事项 |
| 常见疑问 | FAQ |
一句话定义
- 向量量化:将高精度向量(如 float32)编码为低精度表示,以可接受的召回损失换取更低内存占用与更快检索。
- SQ(Scalar Quantization):标量量化,对每一维数值独立降低精度。
- PQ(Product Quantization):乘积量化,将向量切分为多个子向量并在子空间分别做聚类编码。
为什么需要向量量化
在 ANN 场景下(尤其是 HNSW),索引常常受内存约束。量化的核心是把 float32 等高精度向量编码成低精度表示,在可接受的召回损失下换取更低内存占用。
在 Doris 中,ANN 索引通过 quantizer 控制量化方式:
| quantizer | 含义 | 相对 float32 的压缩比 |
|---|---|---|
flat | 不量化(质量最高,内存最高) | 1x |
sq8 | 8bit 标量量化 | 约 4x |
sq4 | 4bit 标量量化 | 约 8x |
pq | 乘积量化 | 取决于 pq_m、pq_nbits |
最小示例(HNSW + quantizer):
CREATE TABLE vector_tbl (
id BIGINT,
embedding ARRAY<FLOAT>,
INDEX ann_idx (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768",
"quantizer" = "sq8"
)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "3");
算法概览
| 方法 | 核心思想 | 典型收益 | 主要代价 |
|---|---|---|---|
| SQ(标量量化) | 每个维度独立量化 | 内存显著下降,实现简单 | 构建开销高于 FLAT;压缩越强召回越容易下降 |
| PQ(乘积量化) | 切分子向量并分组量化 | 常见场景下压缩与查询速度更平衡 | 训练/编码成本高,参数需要调优 |
标量量化(SQ)
原理
SQ 不改变向量维度,只降低每维数值精度。
常见的 min-max 量化映射:
max_code = (1 << b) - 1scale = (max_val - min_val) / max_codecode = round((x - min_val) / scale)
Faiss 中 SQ 主要有两种:
| 类型 | 范围统计方式 | 适用场景 |
|---|---|---|
| Uniform | 所有维度共享一组 min/max | 各维度数值尺度接近 |
| Non-uniform | 每个维度单独统计 min/max | 各维度数值尺度差异明显,重建误差更小 |
特点
优点:
- 实现直接,行为稳定。
- 压缩比可预期(相对 float32 值,
sq8约 4x,sq4约 8x)。
局限:
- 本质仍是固定步长分桶。
- 若单维分布明显非均匀(例如长尾分布),误差会上升。
Faiss 源码要点(SQ)
在 Doris 使用的优化版 Faiss 实现路径中,SQ 训练会先统计最小值/最大值,再按需要对范围做轻微扩展,降低后续 add 阶段越界风险。简化后形态如下:
void train_Uniform(..., const float* x, std::vector<float>& trained) {
trained.resize(2);
float& vmin = trained[0];
float& vmax = trained[1];
// 扫描样本得到 min/max
// 再根据 rs_arg 做范围扩展
}
对于 non-uniform SQ,Faiss 会按维度分别统计(而不是全局一组范围),因此在“各维度数值尺度差异明显”的数据上通常效果更好。
实践观察
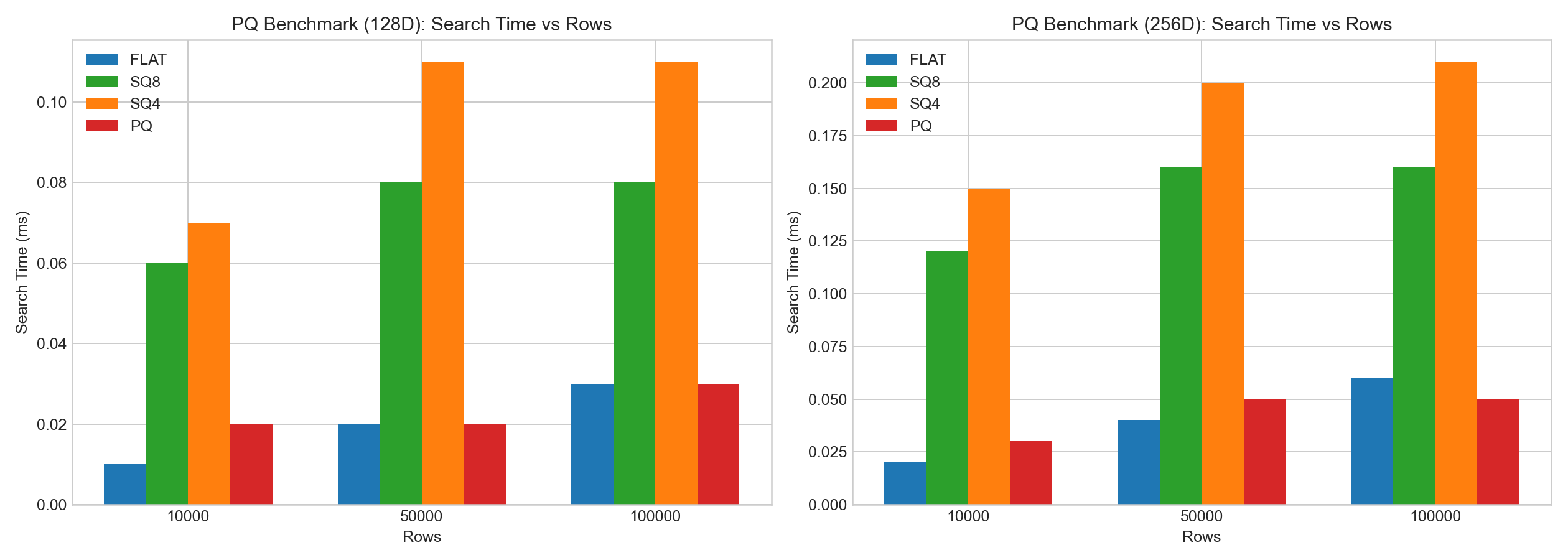
在内部 128D/256D 的 HNSW 测试中:
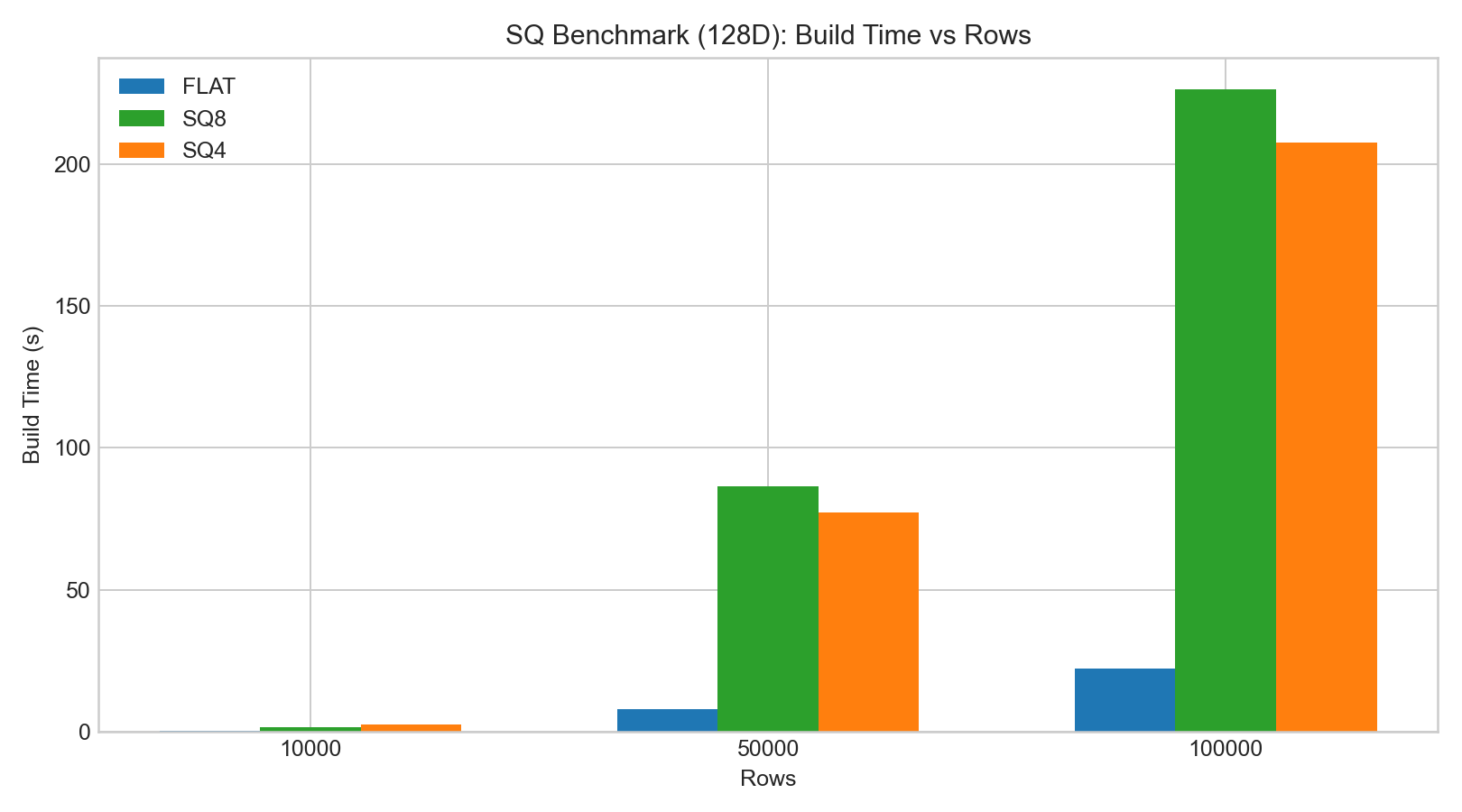
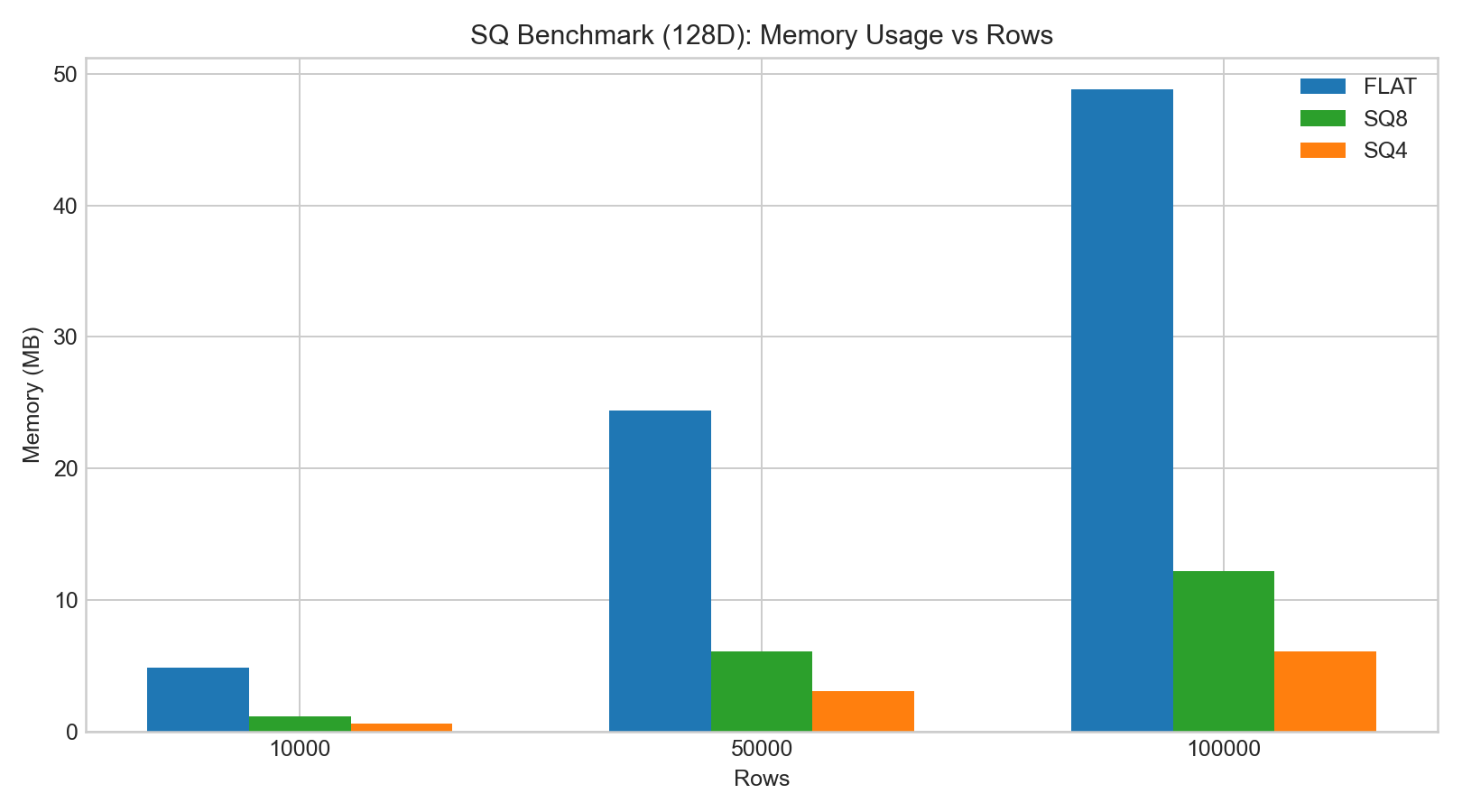
sq8的召回通常明显好于sq4。- SQ 的构建/编码时间显著高于 FLAT。
sq8查询延迟变化通常不大,sq4的召回下滑更明显。
以下柱状图基于示例 benchmark 数据绘制:
乘积量化(PQ)
原理
PQ 将 D 维向量切分成 M 个子向量(每个子向量 D/M 维),在每个子空间做 k-means 量化。
关键参数:
| 参数 | 含义 | 调优方向 |
|---|---|---|
pq_m | 子量化器个数 | 越大精度越好,但训练和编码代价越高 |
pq_nbits | 每个子向量编码位数 | 决定每个子空间的码本大小(2^pq_nbits) |
为什么 PQ 查询可能更快
PQ 可使用 LUT(查找表)做距离近似:
- 预先计算查询子向量到各子空间质心的距离。
- 查询时通过查表并累加估算整体距离。
这可以避免完整重建,在很多场景下降低搜索阶段 CPU 开销。
Faiss 源码要点(PQ)
在同一实现路径下,Faiss 的 ProductQuantizer 会在子空间上训练码本,并把质心存储在连续内存中。简化后形态如下:
void ProductQuantizer::train(size_t n, const float* x) {
Clustering clus(dsub, ksub, cp);
IndexFlatL2 index(dsub);
clus.train(n * M, x, index);
for (int m = 0; m < M; m++) {
set_params(clus.centroids.data(), m);
}
}
其质心布局可理解为 (M, ksub, dsub):
M:子量化器个数。ksub:每个子空间的码本大小(2^pq_nbits)。dsub:子向量维度(D / M)。
实践观察
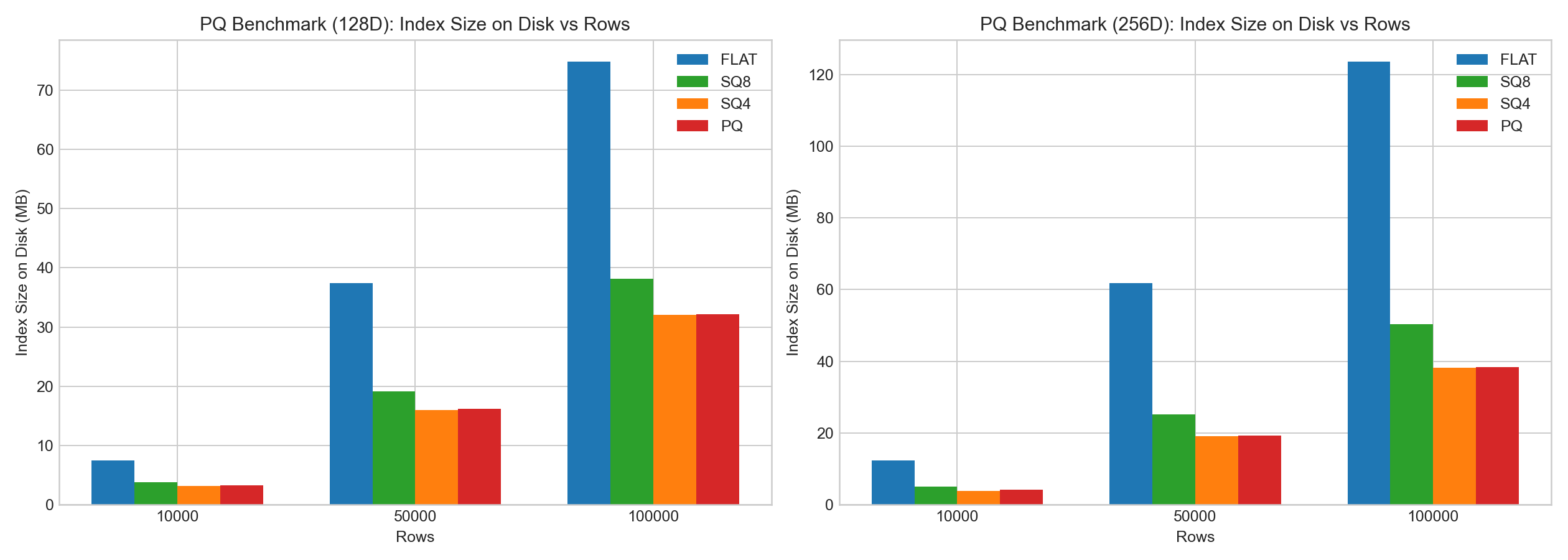
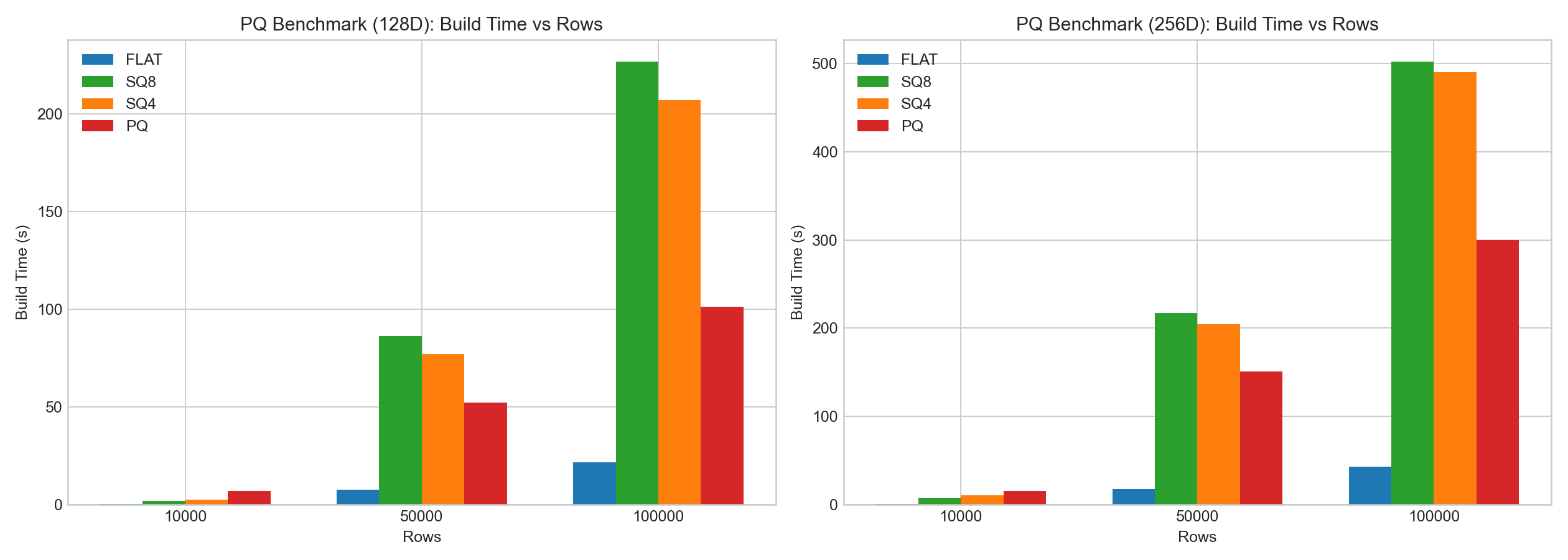
在相同内部测试中:
- PQ 对压缩的正向收益明显。
- PQ 的训练/编码开销较高。
- 相比 SQ,PQ 往往能借助 LUT 在查询阶段获得更好的速度表现,但召回与构建成本仍依赖数据分布与参数组合。
以下柱状图基于示例 benchmark 数据绘制:
Doris 选型建议
按场景对照选型
| 场景 | 推荐 quantizer | 理由 |
|---|---|---|
| 内存充足且召回优先 | flat | 不损失精度,质量上限最高 |
| 希望低风险降内存且质量更稳 | sq8 | 压缩约 4x,召回下降可控 |
| 内存压力极大且可接受更低召回 | sq4 | 压缩约 8x,但召回下滑更明显 |
| 追求压缩与性能平衡并接受调参 | pq | LUT 加速查询,需要参数调优 |
推荐验证流程
- 先以
flat建基线,记录 Recall@K 与查询延迟。 - 优先测试
sq8,对比 Recall 与 P95/P99 延迟。 - 内存仍不够时测试
pq(可先从pq_m = D/2起步)。 - 仅在“内存优先于召回”时考虑
sq4。
压测注意事项
绝对耗时与硬件、线程数、数据集强相关。横向对比时应固定以下变量,确保结论可比:
| 类别 | 需固定的变量 |
|---|---|
| 数据 | 向量维度、数据集分布、行数 |
| 索引 | 索引参数、segment 规模 |
| 查询 | 查询集与真值集 |
评估指标建议同时覆盖:
- Recall@K
- 索引体积
- 构建耗时
- 查询延迟(P50/P95/P99)
FAQ
Q1:sq8 与 sq4 怎么选?
优先 sq8。sq8 压缩约 4x,召回下降可控;sq4 压缩约 8x 但召回下滑更明显,仅在内存极度紧张时使用。
Q2:什么时候选 PQ 而不是 SQ?
当需要更高压缩比或希望借助 LUT 在查询阶段获得更优速度时选 PQ。代价是训练/编码成本更高,且 pq_m、pq_nbits 需要根据数据分布调参。
Q3:量化会影响构建时间吗?
会。所有 quantizer 的构建/编码时间都显著高于 flat,PQ 的训练阶段开销最高。请在评估时单独记录构建耗时。
Q4:Non-uniform SQ 一定优于 Uniform SQ 吗?
不一定。当各维度数值尺度差异明显(例如某些维度天然量级更大)时,Non-uniform 重建误差更小;若各维度尺度接近,两者差距有限。
Q5:pq_m 怎么设置起步值?
可先从 pq_m = D/2 起步,再通过 Recall@K 与查询延迟在两侧调整。pq_m 越大精度越好,但训练和编码代价越高。