跨集群数据同步概述
概览
CCR (Cross Cluster Replication) 是一种跨集群数据同步机制,能够在库或表级别将源集群的数据变更同步到目标集群。
适用场景
CCR 适用于以下几种常见场景:
-
容灾备份:将企业数据备份到另一集群和机房,确保在业务中断或数据丢失时能够恢复数据。
-
读写分离:通过将数据的查询操作与写入操作分离,减小读写之间的相互影响,提升服务稳定性。对于高并发或写入压力大的场景,采用读写分离可以有效分散负载,提升数据库性能和稳定性。
-
数据集中:集团总部需统一管理和分析分布在不同地域的分公司数据,避免因数据不一致导致的管理混乱和决策错误,从而提升集团管理效率和决策质量。
-
隔离升级:在进行系统集群升级时,使用 CCR 可以在新集群中进行验证和测试,避免因版本兼容问题导致的回滚困难。用户可以逐步升级各个集群,同时保证数据一致性。
-
集群迁移:在进行 Doris 集群的机房搬迁或设备更换时,使用 CCR 可以将老集群的数据同步到新集群,确保迁移过程中的数据一致性。
任务类别
CCR 支持两种任务类型:
- 库级任务:同步整个数据库的数据。
- 表级任务:仅同步指定表的数据。注意,表级同步不支持重命名表或替换表操作。Doris 每个数据库只能同时运行一个快照任务,因此表级同步的全量同步任务需要排队执行。
原理与架构
名词解释
- 源集群:数据源所在的集群,通常为业务数据写入的集群。
- 目标集群:跨集群同步的目标集群。
- binlog:源集群的变更日志,包含了 schema 和数据变更。
- Syncer:一个轻量级的进程,负责同步数据。
- 上游:在库级任务中指上游库,在表级任务中指上游表。
- 下游:在库级任务中指下游库,在表级任务中指下游表。
架构说明
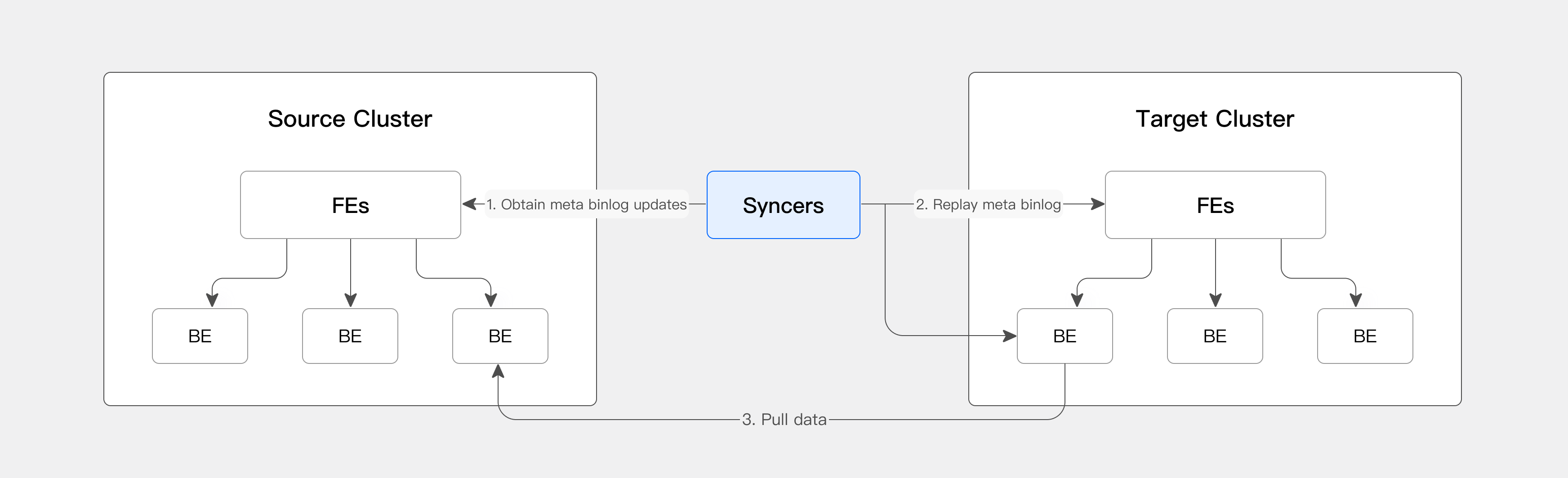
CCR 主要依赖一个轻量级进程:Syncer。Syncer 负责从源集群获取 binlog,并将元数据应用到目标集群,通知目标集群从源集群拉取数据,从而实现全量同步和增量同步。
原理
-
全量同步:
- CCR 任务会首先进行全量同步,将上游数据一次性完整地复制到下游。
-
增量同步:
- 在全量同步完成后,CCR 任务会继续进行增量同步,保持上游和下游数据的一致性。
-
重新开始全量同步的情况:
- 遇到当前不支持增量同步的 DDL 操作时,CCR 任务会重新启动全量同步。具体哪些 DDL 操作不支持增量同步,请参见功能详情。
- 如果上游的 binlog 因为过期或其他原因中断,增量同步会停止,并重新开始全量同步。
-
重新全量同步:
- 在全量同步进行期间,增量同步会暂停。
- 全量同步完成后,下游的数据表会进行原子替换,以确保数据一致性。
- 全量同步完成后,会恢复增量同步。
同步方式
CCR 支持四种同步方式:
| 同步方式 | 原理 | 触发时机 |
|---|---|---|
| Full Sync | 上游进行全量备份,下游进行恢复。DB 级任务触发 DB 备份,表级任务触发表备份。 | 首次同步或特定操作触发。触发条件请参见功能详情。 |
| Partial Sync | 上游表或分区级别备份,下游表或分区级别恢复。 | 特定操作触发,触发条件请参见功能详情。 |
| TXN | 增量数据同步,上游提交后,下游开始同步。 | 特定操作触发,触发条件请参见功能详情。 |
| SQL | 在下游回放上游操作的 SQL。 | 特定操作触发,触发条件请参见功能详情。 |
下载
要求:glibc >= 2.28
| 版本 | 架构 | 包地址 | SHA256 |
|---|---|---|---|
| 2.1 | ARM64 | ccr-syncer-2.1.10-rc08-arm64.tar.xz | 060093e90150ee24f8a784066436a0a4a1116876ebd6f33d5a844e2dc67f10b0 |
| 2.1 | X64 | ccr-syncer-2.1.10-rc08-x64.tar.xz | 656c0a46e3f0e12b9ff2fb76116ad8362e344a8d1ac31f1b26834aaaa1987a7b |
| 3.0 | ARM64 | ccr-syncer-3.0.6-rc07-arm64.tar.xz | bb136f5c9db60f18c174d32304557065e1581e96ce14009f8e8f9aa4d58628f1 |
| 3.0 | X64 | ccr-syncer-3.0.6-rc07-x64.tar.xz | 31e514b4d55fb4f11204cd023369ef5988ffda3cb3728e974899623ea81dc1ad |
| 4.0 | ARM64 | ccr-syncer-4.0.1-rc03-arm64.tar.xz | 5ea016773c0589b437311a40fe5c2397e01ab4dd5d04a62ba9d6c1d4975522ac |
| 4.0 | X64 | ccr-syncer-4.0.1-rc03-x64.tar.xz | bb26d5cc31403e6d6c9d2feccf82347ff7fde81f174b53907ffec067c5a87b54 |