HNSW
HNSW(Malkov & Yashunin, 2016)由于在工程实践中能以较小的资源达到高召回和低延迟的查询表现,已成为在线高性能向量检索的事实标准。Apache Doris 自 4.x 版本起支持基于 HNSW 的 Ann Index,本文将从 HNSW 算法原理出发,结合参数与工程实践,讲如何在 Apache Doris 生产集群中使用与调优基于 HNSW 算法的 ANN 索引。
在 HNSW 之前
HNSW (Hierarchical Navigable Small World) 算法是在 Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs 这篇论文中被提出的。在 HNSW 之前,业界其实已经有了很多对于近似 KNN 搜索的算法研究,但是这些算法各有各的问题。
Proximate Graph
这类算法的基本原理是从图的某个入口出发(入口可以是随机顶点或者某种策略算出的顶点),迭代式地遍历图。在每个迭代步骤上,算法计算查询向量与当前基节点所有邻居的距离,然后选择其中距离最小的邻居作为下一次迭代的基节点,同时持续维护迄今为止找到的最佳候选邻居集合。当某些条件——比如一轮迭代后找不到新的更近节点——被满足之后,算法停止迭代,然后从当前的候选节点中选出 K 个最近的节点作为最终的结果。
近邻图算法其实都是对 Delaunay Graph 一种近似,因为 Delaunay Graph 有一个重要的性质:贪心搜索总是能找到最近邻。
然而这类算法有两种缺陷:
- 随着数据量的增加,查询路由阶段的迭代次数会有幂律级别的增加。
- 构建一个高质量的 proximity graph 很难,很容易出现局部聚集导致图不具备全局联通的问题。
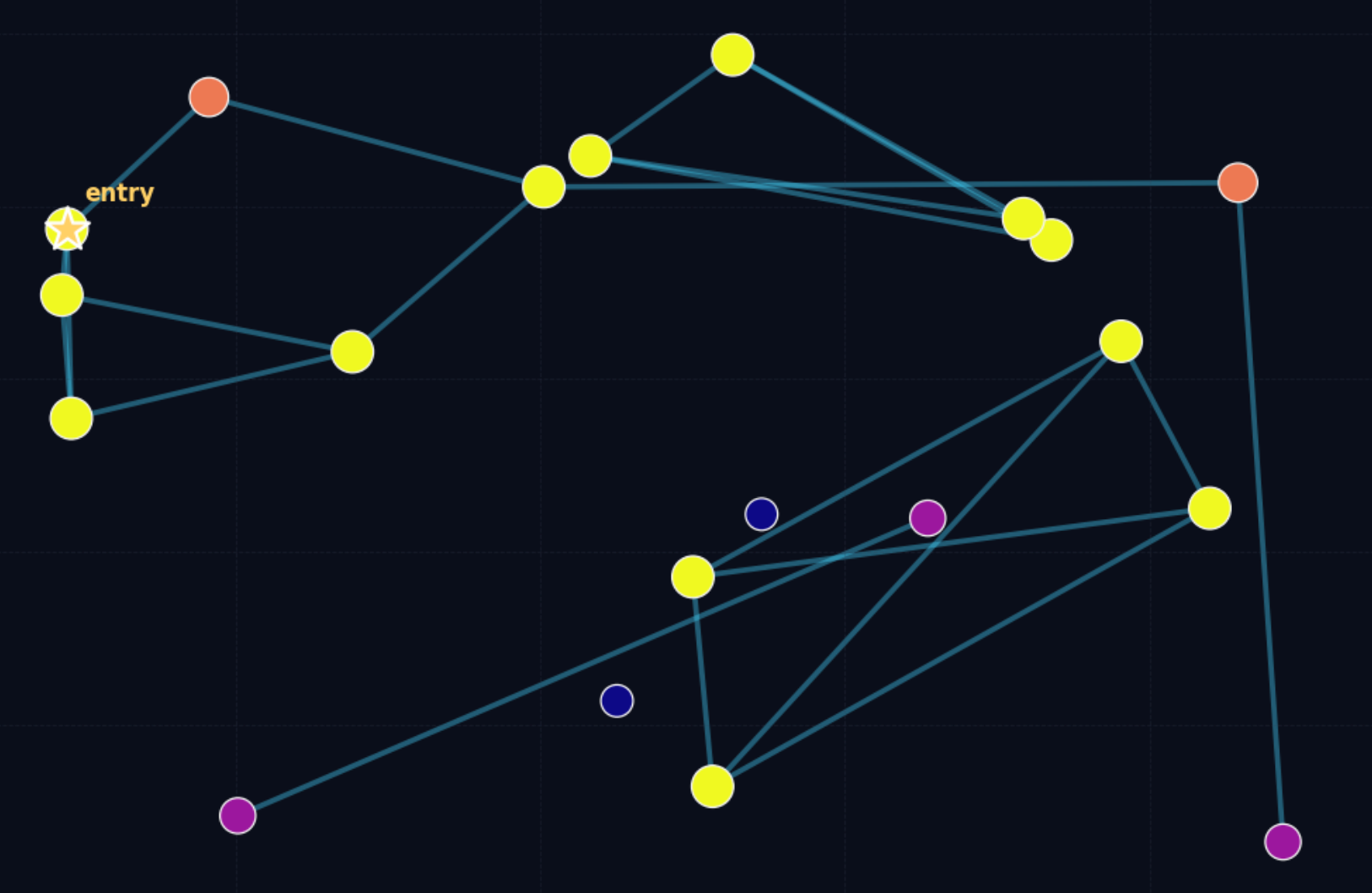
这里有一张示意图可以直观展示一个不理想的 proximity graph 的形状。图中颜色越深的点表示该点的连通性越差,可以看到有个别点几乎没有找到自己的邻居,那么在搜索阶段这些点就很难被路由到。
Navigable Small World
为了解决前面提到的问题,有两种思路:
- 混合算法,在搜索临接图之前,先进行一次粗排,找到更合适的入口点,再进行贪婪搜索
- 通过可导航的小世界结构保持良好连通性,同时限制每个节点的最大邻居数量来控制搜索复杂度。
NSW(Navigable Small World)就是采用上述第二种思路设计的。
NSW 模型最早是在J. Kleinberg 的这个社会实验中被提出,被用来研究社会中人与人之间的联系,也许你听说过六度分割理论? 具体到 K-NN 图算法,所有在搜索时具有对数复杂度或者多重对数复杂度的小世界网络均被称为可导航小世界网络(Navigable Small Workd Network)。实际的实现有很多,这里不赘述。 在一些数据集上,NSW 代表了当时最先进的搜索性能,然而由于 NSW 算法并不是严格的对数复杂度,因此在某些测试上,尤其是在低维度的向量空间测试集上,NSW 算法的性能表现不佳。
Hierarchical Navigable Small World
NSW 算法在搜索时分为两个阶段:zoom-out 和 zoom-in。
zoom-out 指的是首先随机选择一个低度数的顶点作为入口,然后从该点开始进行搜索,搜索时偏好一个更高度数的点,直到某个点距离自己邻居的平均长度超过该节点到查询向量的距离。
zoom-in 指的是当我们找到一定条件下的高度节点之后,开始执行贪婪搜索,直到找到最佳的 TopN。
NSW 算法具有多重对数复杂度的原因是总的距离计算次数大致与搜索过程中跳跃的次数和这些经过顶点的平均度的乘积成正比,而平均的跳跃次数和顶点度的平均值均与数据规模成对数复杂度的关系,因此最终的总体复杂度就是多重对数复杂度。
HNSW 算法则是通过加速 zoom-out 过程来将查询时间复杂度降低到对数时间复杂度。
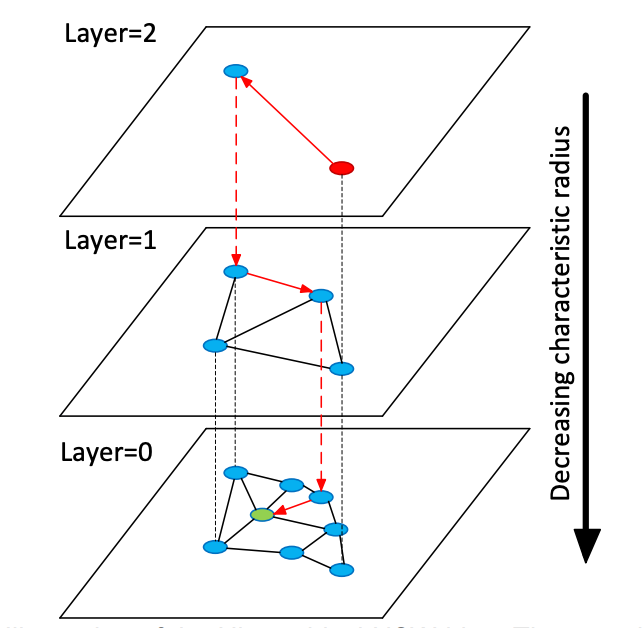
具体来说,HNSW 中所谓的分层指的是按照顶点边的典型长度范围(characteristic radius),来对 NSW 图中的顶点分层。 搜索时,选取高度最高的点作为入口,逐层进行贪心搜索,找到当前层的最近点后,向下移动,重复该过程,直到最底层。每一层中顶点的最大连接数有一个上限,因此保证了总体的对数时间复杂度。
而为了构建这种分层结构,对于每一个节点,都会以计算每个节点应该位于的层数 l(通常满足几何分布),这样确保整个结构不会具有过多的分层。并且 HNSW 不需要在导入数据之前对数据进行 shuffle(NSW 中必须 shuffle,否则影响图的质量),因为在索引期间引入的随机层级计算本身就是一种随机化的行为,这使得 HNSW 可以进行真正的增量更新。
HNSW In Apache Doris
Doris 从 4.0 版本开始支持用户建立基于 HNSW 算法的索引。
索引构建
这类索引的具体类型是 ANN。创建 ANN 索引的方式有两种。一种是建表时指定,还有一种是通过 CREATE/BUILD INDEX 语法。我们会说明这两种创建索引的区别以及应用场景。
方式一,建表时指定在某个向量列上创建索引。建表后导入数据时会随着每个 segment 的创建,构造作用范围为该 segment 的 ANN 索引。这种方式的好处是随着数据导入完成,索引同步完成构造,因此后续的查询立刻就可以使用 ANN 索引进行加速。这种方式的缺点是索引的同步构造过程会导致导入过程变得比较慢,并且在 compaction 过程中会引入索引的重复构建,有一定程度的资源浪费。
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO sift_1M
SELECT *
FROM S3(
"uri" = "https://selectdb-customers-tools-bj.oss-cn-beijing.aliyuncs.com/sift_database.tsv",
"format" = "csv");
CREATE/BUILD INDEX
方式二,CREATE/BUILD INDEX
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO sift_1M
SELECT *
FROM S3(
"uri" = "https://selectdb-customers-tools-bj.oss-cn-beijing.aliyuncs.com/sift_database.tsv",
"format" = "csv");
导入数据后 CREATE INDEX,此时 table 上已经有了 index 的定义,但是没有真正在存量数据上构建索引。
CREATE INDEX idx_test_ann ON sift_1M (`embedding`) USING ANN PROPERTIES (
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128"
);
SHOW DATA ALL FROM sift_1M
+-----------+-----------+--------------+----------+----------------+---------------+----------------+-----------------+----------------+-----------------+
| TableName | IndexName | ReplicaCount | RowCount | LocalTotalSize | LocalDataSize | LocalIndexSize | RemoteTotalSize | RemoteDataSize | RemoteIndexSize |
+-----------+-----------+--------------+----------+----------------+---------------+----------------+-----------------+----------------+-----------------+
| sift_1M | sift_1M | 1 | 1000000 | 170.001 MB | 170.001 MB | 0.000 | 0.000 | 0.000 | 0.000 |
| | Total | 1 | | 170.001 MB | 170.001 MB | 0.000 | 0.000 | 0.000 | 0.000 |
+-----------+-----------+--------------+----------+----------------+---------------+----------------+-----------------+----------------+-----------------+
2 rows in set (0.01 sec)
通过 BUILD INDEX 语句来完成索引的构建工作:
BUILD INDEX idx_test_ann ON sift_1M;
BUILD INDEX 是异步执行的,需要通过 SHOW ALTER 来查看任务的执行状态。
SHOW BUILD INDEX WHERE TableName = "sift_1M"
--------------
+---------------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+---------------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 1763603913428 | sift_1M | sift_1M | [ADD INDEX idx_test_ann (`embedding`) USING ANN PROPERTIES("dim" = "128", "index_type" = "hnsw", "metric_type" = "l2_distance")], | 2025-11-20 11:14:55.253 | 2025-11-20 11:15:10.622 | 126128 | FINISHED | | NULL |
+---------------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
DROP INDEX
同样可以通过 ALTER TABLE sift_1M DROP INDEX idx_test_ann 来删除不合适的 Ann 索引。DROP INDEX 通常发生在索引的超参数调优阶段,为了确保足够的召回率需要测试不同的参数组合,需要灵活的索引管理。
进行查询
ANN 索引支持对 topn search 还有 range search 进行加速。
当向量列是高维向量时,用于描述查询向量的字符串本身会引入额外的解析开销,因此不建议在生产环境中,尤其是高并发场景里,直接使用原始 SQL 执行向量搜索查询。使用 prepare statement 来提前对 sql 进行解析是一个能够提高查询性能的做法,所以建议使用 doris 的向量搜索 python library,在这个 python library 里面封装了基于 prepare statement 对 doris 进行向量搜索的必要的操作,并且集成了相关的数据转化流程,可以直接将 doris 的查询结果转为 pandas 的 DataFrame,方便用户基于 doris 开发 AI 应用。
from doris_vector_search import DorisVectorClient, AuthOptions
auth = AuthOptions(
host="localhost",
query_port=9030,
user="root",
password="",
)
client = DorisVectorClient(database="demo", auth_options=auth)
tbl = client.open_table("sift_1M")
query = [0.1] * 128 # Example 128-dimensional vector
# SELECT id FROM sift_1M ORDER BY l2_distance_approximate(embedding, query) LIMIT 10;
result = tbl.search(query, metric_type="l2_distance").limit(10).select(["id"]).to_pandas()
print(result)
上面的 python 脚本执行结果为:
id
0 123911
1 11743
2 108584
3 123739
4 73311
5 124746
6 620941
7 124493
8 177392
9 153178
召回率优化
向量搜索场景里面最重要的指标是召回率,一切性能数据只有在满足一定的召回率的前提下才有意义。影响召回率的因素主要包括:
- HNSW 索引阶段的参数(max_degree, ef_construction)以及查询阶段的参数(ef_search)
- 索引向量量化
- segment 的大小与数量
这篇文章里我们将会讨论 1,3 对于召回率的影响,关于向量量化会在其他的文章里进行介绍。
索引超参数
HNSW 索引以分层图的形式组织向量。在构建阶段,向量逐个插入索引中,并在多层结构中寻找邻居节点。构建流程包括:
- 多层随机赋级(Layer assignment):每个向量被随机分配到多个层中,较高层节点更稀疏,用于快速导航。
- 使用 ef_construction 搜索候选邻居: 在每一层,HNSW 使用一个最大长度为 ef_construction 的候选队列来执行广度优先的局部搜索。 更大的 ef_construction 能找到更准确的邻居,使图结构更合理、搜索质量更高,但构建时间会更长。
- 使用 max_degree 限制连接数: 每个节点的邻居数受到 max_degree 的限制,保证图结构不会过于稠密。
在查询阶段:
- 高层贪心搜索(Coarse search): 从入口点开始,自顶向下在高层执行贪心搜索,快速找到接近目标区域的节点。
- 底层使用 ef_search 执行广度搜索(Fine search): 在第 0 层,HNSW 使用最大长度为 ef_search 的候选队列进行更全面的邻域扩展。
总之:
max_degree定义了图中每个节点保存的双向边的个数,该参数会影响召回率,内存使用率以及查询性能。更大的max_degree会提高召回率,但是会降低查询性能。ef_construction定义了索引阶段用来保存候选节点的队列的最大长度,增大ef_construction可以提高图的质量,获得更高的召回率,但是也会导致索引构建时间变长。- 对应
ef_search定义了查询阶段候选节点队列的最大长度,更大的ef_search也会提高召回率,但是会导致搜索时距离计算次数变多,查询延迟变高,并且 CPU 开销变大。
doris 默认的 max_degree 为 32,默认的 ef_construction 和 ef_search 分别为 40 和 32。
上述测试都是对这三个超参数定性的分析,通过实际实验,在 SIFT_1M 数据集上有如下的测试结果
| max_degree | ef_construction | ef_search | recall_at_1 | recall_at_100 |
|---|---|---|---|---|
| 32 | 80 | 32 | 0.955 | 0.75335 |
| 32 | 80 | 64 | 0.98 | 0.88015 |
| 32 | 80 | 96 | 0.995 | 0.9328 |
| 32 | 120 | 32 | 0.96 | 0.7736 |
| 32 | 120 | 64 | 0.975 | 0.89865 |
| 32 | 120 | 96 | 0.99 | 0.94575 |
| 32 | 160 | 32 | 0.955 | 0.78745 |
| 32 | 160 | 64 | 0.98 | 0.9097 |
| 32 | 160 | 96 | 0.995 | 0.95485 |
| 48 | 80 | 32 | 0.985 | 0.85895 |
| 48 | 80 | 64 | 0.99 | 0.9453 |
| 48 | 80 | 96 | 1 | 0.97325 |
| 48 | 120 | 32 | 0.97 | 0.78335 |
| 48 | 120 | 64 | 1 | 0.9089 |
| 48 | 120 | 96 | 1 | 0.95325 |
| 48 | 160 | 32 | 0.975 | 0.79745 |
| 48 | 160 | 64 | 0.995 | 0.9192 |
| 48 | 160 | 96 | 0.995 | 0.9601 |
| 64 | 80 | 32 | 1 | 0.9026 |
| 64 | 80 | 64 | 1 | 0.97025 |
| 64 | 80 | 96 | 1 | 0.9862 |
| 64 | 120 | 32 | 0.985 | 0.8548 |
| 64 | 120 | 64 | 0.99 | 0.94755 |
| 64 | 120 | 96 | 0.995 | 0.97645 |
| 64 | 160 | 32 | 0.97 | 0.80585 |
| 64 | 160 | 64 | 0.99 | 0.91925 |
| 64 | 160 | 96 | 0.995 | 0.96165 |
从实际测试结果来看,为了达到同一水平的召回率,可以有不同的超参数组合方案。比如假设目标是 top 100 的召回率大于 95%,满足条件的组合有:
| max_degree | ef_construction | ef_search | recall_at_1 | recall_at_100 |
|---|---|---|---|---|
| 32 | 160 | 96 | 0.995 | 0.95485 |
| 48 | 80 | 96 | 1 | 0.97325 |
| 48 | 120 | 96 | 1 | 0.95325 |
| 48 | 160 | 96 | 0.995 | 0.9601 |
| 64 | 80 | 64 | 1 | 0.97025 |
| 64 | 80 | 96 | 1 | 0.9862 |
| 64 | 120 | 96 | 0.995 | 0.97645 |
| 64 | 160 | 96 | 0.995 | 0.96165 |
虽然很难事先给出超参数的具体取值,但是我们可以给出一个关于如何选取超参数的实践方法:
- 建立一张无索引的表 table_multi_index,table_multi_index 可以有 2 或者 3 个向量列
- 通过 stream load 等方式将数据导入到无索引的 table_multi_index
- 通过
CREATE INDEX和BUILD INDEX在所有的向量列上构建索引 - 不同的列选择不同的索引参数,等索引构建完成后在不同的列上计算召回率,找到最合适的超参数组合
索引覆盖的行数
Doris 内表的数据是分层组织的。最高层级的概念是 Table,Table 按照分桶键把原始数据尽可能均匀地分布到 N 个 tablets 里面,tablet 是用来进行数据迁移与rebalance的基本单位。每次导入或者compaction会在tablet下新增一个rowset,rowset是进行版本管理的单位,其本身只是代表一组具有版本号的数据,这组数据真正存储在 segment 文件里。
与倒排索引一样,向量索引也作用在 segment 粒度上。segment 本身的大小取决于 be conf 中的 write_buffer_size 和 vertical_compaction_max_segment_size,在导入和 compaction 过程中,当内存中 memtable 的积累到一定大小后就会下刷生成一个 segment 文件,并且为该 segment 构造一个向量索引(如果有多个索引列那么就有多个索引),该索引能够覆盖的范围就是这个 segment 中对应列的行数。根据前面对 HNSW 算法搜索与构建过程的介绍,对于某组索引参数,其能够有效覆盖的数据范围是有限的,当数据量超过某个阈值后,召回率就无法满足要求。
这里我们给出一些索引超参数和其能够覆盖的 segment 行数的经验值
| max_degree | ef_construction | ef_search | num_segment | recall_at_100 |
|---|---|---|---|---|
| 32 | 160 | 96 | 1M | 0.95485 |
| 48 | 80 | 96 | 1M | 0.97325 |
| 32 | 160 | 32 | 3M | 0.66983 |
| 128 | 512 | 128 | 3M | 0.9931 |
通过 SHOW TABLETS FROM table 可以看到某张表的 Compaction 状态,点开对应的 URL 可以看到这张表有多少个 segment。
Compaction 对召回率的影响
Compaction 之所以会影响召回率是因为 compaction 有时会生成更大的 segment,导致原先的索引超参数无法在新的更大的 segment 上保障覆盖率。因此建议在 BUILD INDEX 之前触发一次 FULL COMPACTION,在充分合并过的 segment 上构建索引不光可以保持召回率稳定,还可以减少索引构建引入的写放大。
查询性能
索引文件的冷加载
Doris 的 ANN 索引是基于 Meta 开源的 faiss 实现的。HNSW 索引需要在完整的图结构全部被加载进内存后才能进行查询加速,因此建议在高并发查询之前,先进行一次冷查询,确保涉及到的 segment 的索引文件全部加载进了内存,否则对于查询性能会有较大影响。
内存空间与性能
HNSW 索引(无量化压缩)占用的内存空间近似等于其所能检索的向量的内存大小的 1.2 倍。比如对于 128 维,1M 的数据集,HNSW FLAT 索引需要的内存空间大约为 128 * 4 * 1000000 * 1.3 约等于 650 MB。
| dim | rows | 预估内存 |
|---|---|---|
| 128 | 1M | 650MB |
| 768 | 10M | 48GB |
| 768 | 100M | 110GB |
为了保证查询性能,需要 BE 有足够的内存空间,否则索引的频繁 IO 会导致查询性能大幅衰减。
Benchmark
我们在 16C 64GB 的机器上测试了 Doris HNSW 索引的查询性能。Doris 生产集群的典型部署模式应该是 FE 与 BE 分开部署,此时需要两台 16C 64GB 的机器,因此我们把典型部署模式的测试结果与 FE BE 混合部署的测试结果都列了出来。
测试框架来自于 VectorDBBench。 压测 client 是另一台 16C 的机器。
Performance768D1M
测试命令
NUM_PER_BATCH=1000000 python3.11 -m vectordbbench doris --host 127.0.0.1 --port 9030 --case-type Performance768D1M --db-name Performance768D1M --search-concurrent --search-serial --num-concurrency 10,40,80 --stream-load-rows-per-batch 500000 --index-prop max_degree=128,ef_construction=512 --session-var hnsw_ef_search=128
| Doris(FE/BE 分离) | Doris(FE/BE 混合) | |
|---|---|---|
| Index prop | max_degree=128, ef_construction=512, hnsw_ef_search=128 | max_degree=128, ef_construction=512, hnsw_ef_search=156 |
| Recall@100 | 0.9931 | 0.9929 |
| Concurrency (Client) | 10, 40, 80 | 10, 40, 80 |
| Result QPS | 163.1567(10) 606.6832(40) 859.3842(80) | 162.3002(10) 542.3488(40) 607.7951(80) |
| Avg Latency (s) | 0.06123(10) 0.06579(40) 0.09281(80) | 0.06154(10) 0.07351(40) 0.13093(80) |
| P95 Latency (s) | 0.06560(10) 0.07747(40) 0.12967(80) | 0.06726(10) 0.08789(40) 0.18719(80) |
| P99 Latency (s) | 0.06889(10) 0.08618(40) 0.14605(80) | 0.06154(10) 0.07351(40) 0.13093(80) |