数据更新概述
本文介绍 Apache Doris 的数据更新与删除能力,帮助你回答以下问题:
- 业务场景应选择哪种表模型?
- 何时使用导入更新(UPSERT、部分列更新),何时使用 DML 更新(
UPDATE、INSERT INTO SELECT)? - 主键模型背后的实现机制是什么?(Merge-on-Write、Sequence 列、删除标记、部分列更新)
- CDC 同步、实时宽表等典型场景如何落地?
阅读建议:
- 只想快速选型,请直接看 1. 选择合适的更新方式。
- 想理解原理或排查性能问题,请看 2. 主键模型实现机制。
- 想参考典型业务实践,请看 3. 典型业务场景。
- 想了解最佳实践与限制,请看 4. 使用建议。
1. 选择合适的更新方式
1.1 表模型与更新能力对比
Doris 提供三种表模型,对更新和删除的支持差异较大。选型时建议先确认业务是否需要行级更新或部分列更新。
| 表模型 | 数据组织 | 支持的更新/删除方式 | 典型用途 |
|---|---|---|---|
| 主键模型(Unique Key) | 每行由唯一主键标识,写入时去重 | UPSERT、部分列更新、UPDATE、标记删除、DELETE | 订单状态变更、用户标签更新、CDC 同步 |
| 聚合模型(Aggregate Key) | 相同 Key 的 Value 列按聚合函数(SUM/MAX/MIN/REPLACE)合并 | 通过导入按聚合语义更新;DELETE 仅支持 Key 列条件 | 实时报表、点击量等汇总场景 |
| 明细模型(Duplicate Key) | 仅追加写入,不去重也不聚合 | 仅支持 DELETE | 日志、行为埋点等只追加场景 |
选型结论:需要行级更新或部分列更新时,应选择主键模型。
1.2 更新路径选择
主键模型支持两条更新路径,可按数据规模与业务频率选择:
| 路径 | 适用场景 | 推荐写入方式 |
|---|---|---|
| 导入更新(UPSERT) | 高频、大批量更新;CDC 同步;多源宽表拼接 | Stream Load、Routine Load、Broker Load、INSERT INTO |
DML 更新(UPDATE) | 低频、批量更新;按条件刷数;跨表关联更新 | UPDATE、INSERT INTO ... SELECT ... |
1.2.1 通过导入更新(UPSERT)
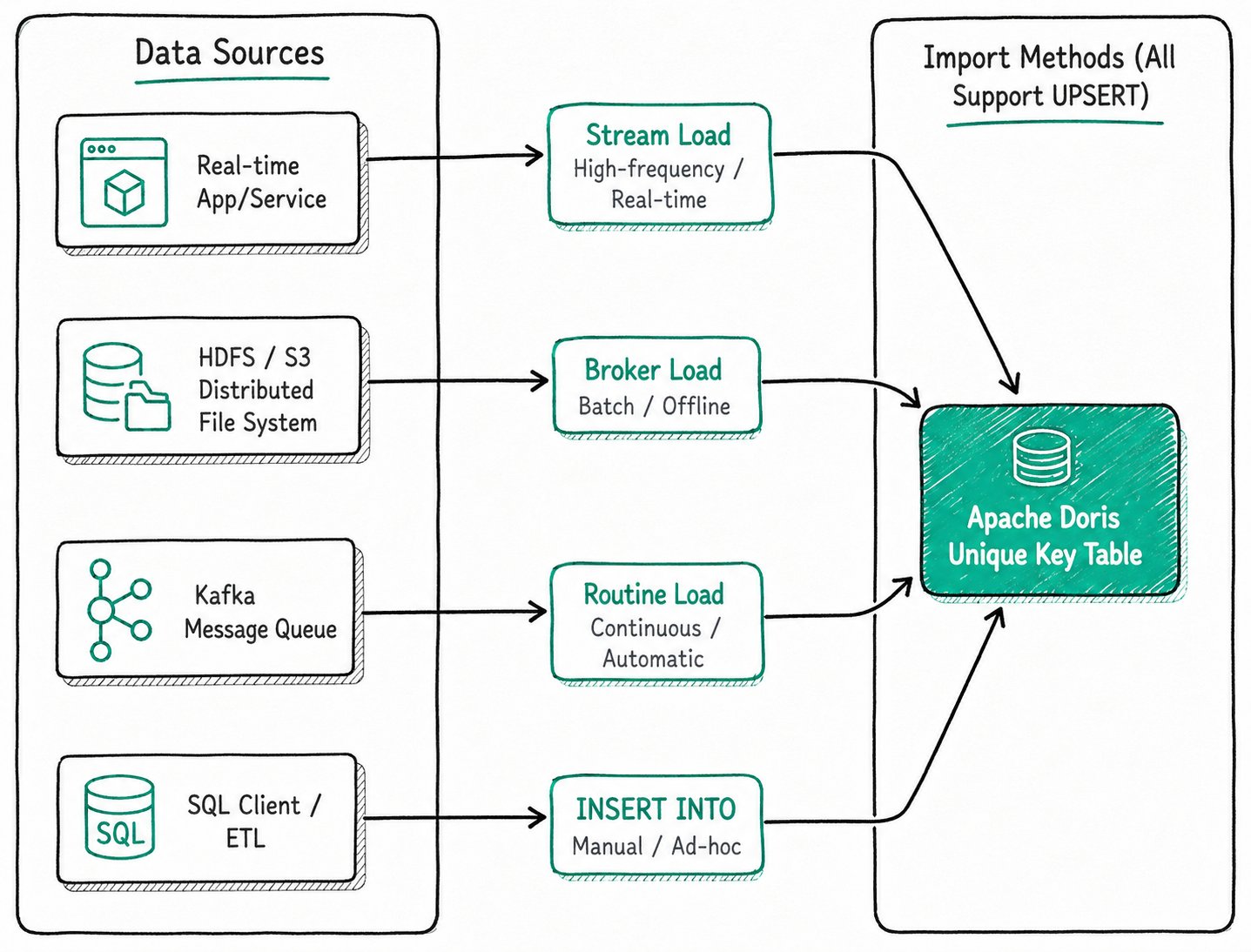
所有导入方式(Stream Load、Broker Load、Routine Load、INSERT INTO)默认按 UPSERT 语义处理主键模型的数据:
- 主键已存在:用新行覆盖旧行;
- 主键不存在:插入新行。
不同表模型的导入更新行为存在差异,详见:
1.2.2 通过 UPDATE 语句更新
Doris 支持标准 SQL UPDATE,可按 WHERE 条件更新主键模型表的数据,并支持跨表关联更新。
-- 简单更新
UPDATE user_profiles SET age = age + 1 WHERE user_id = 1;
-- 跨表关联更新
UPDATE sales_records t1
SET t1.user_name = t2.name
FROM user_profiles t2
WHERE t1.user_id = t2.user_id;
UPDATE 的执行过程为:先扫描满足条件的数据,再将更新后的行写回。适合低频、批量更新场景。
不建议对相同主键的数据进行高并发 UPDATE,并发 UPDATE 在涉及相同主键时无法保证数据隔离性。
UPDATE 语句的语法、典型用法与限制详见:使用 UPDATE 命令更新数据。
1.2.3 通过 INSERT INTO SELECT 更新
由于主键模型默认 UPSERT 语义,使用 INSERT INTO ... SELECT ... 也可达到 UPDATE 的效果,适合从其他表批量回写。
1.3 数据删除路径
Doris 提供两条数据删除路径,不同表模型的实现机制存在差异:
| 删除路径 | 支持的表模型 | 说明 |
|---|---|---|
| 通过导入标记删除 | 主键模型 | 写入 __DORIS_DELETE_SIGN__ = 1 标记,后台 Compaction 物理清理 |
通过 DML 删除(DELETE / TRUNCATE) | 全部模型 | 按条件删除数据或清空表/分区 |
完整说明见 数据删除。
2. 主键模型实现机制
2.1 Merge-on-Write 与 Merge-on-Read
主键模型有两种数据合并策略。自 Doris 2.1 起,Merge-on-Write 为默认实现。
| 维度 | Merge-on-Write(MoW) | Merge-on-Read(MoR,旧版) |
|---|---|---|
| 写入时行为 | 写入时去重合并,存储中每个主键只保留一条最新记录 | 写入时保留多版本 |
| 查询性能 | 接近无更新的明细表 | 查询时实时合并,耗时约为 MoW 的 3-10 倍 |
| 写入性能 | 有合并开销,相比 MoR 略低(小批量约 10-20%,大批量约 30-50%) | 接近明细表 |
| 资源消耗 | 写入与后台 Compaction 消耗较多 CPU/内存 | 查询时消耗较多 CPU/内存 |
| 适用场景 | 读多写少(推荐) | 写多读少(不再推荐) |
新建表默认使用 MoW,无需额外配置。
2.2 Sequence 列与乱序数据
分布式系统中数据可能乱序到达。例如订单状态先后变更为"已支付"和"已发货",但因网络延迟,"已发货"消息可能先于"已支付"到达 Doris。
通过 Sequence 列机制可解决此问题:建表时指定一列(通常是时间戳或版本号)作为 Sequence 列,写入相同主键的数据时,Doris 始终保留 Sequence 值最大的那一行。
CREATE TABLE order_status (
order_id BIGINT,
status_name STRING,
update_time DATETIME
)
UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"function_column.sequence_col" = "update_time" -- 指定 update_time 为 Sequence 列
);
-- 1. 写入"已发货"记录(update_time 较大)
-- {"order_id": 1001, "status_name": "Shipped", "update_time": "2023-10-26 12:00:00"}
-- 2. 写入"已支付"记录(update_time 较小,后到达)
-- {"order_id": 1001, "status_name": "Paid", "update_time": "2023-10-26 11:00:00"}
-- 最终结果:保留 update_time 最大的记录
-- order_id: 1001, status_name: "Shipped", update_time: "2023-10-26 12:00:00"
更多内容:
- Sequence 列、MVCC 版本管理、
UPDATE并发参数等并发控制能力详见:主键模型的更新并发控制。 - 多条数据流同时更新一张宽表的不同列时,可使用 Sequence Mapping 控制每列各自的版本顺序,详见:主键模型的多流更新。
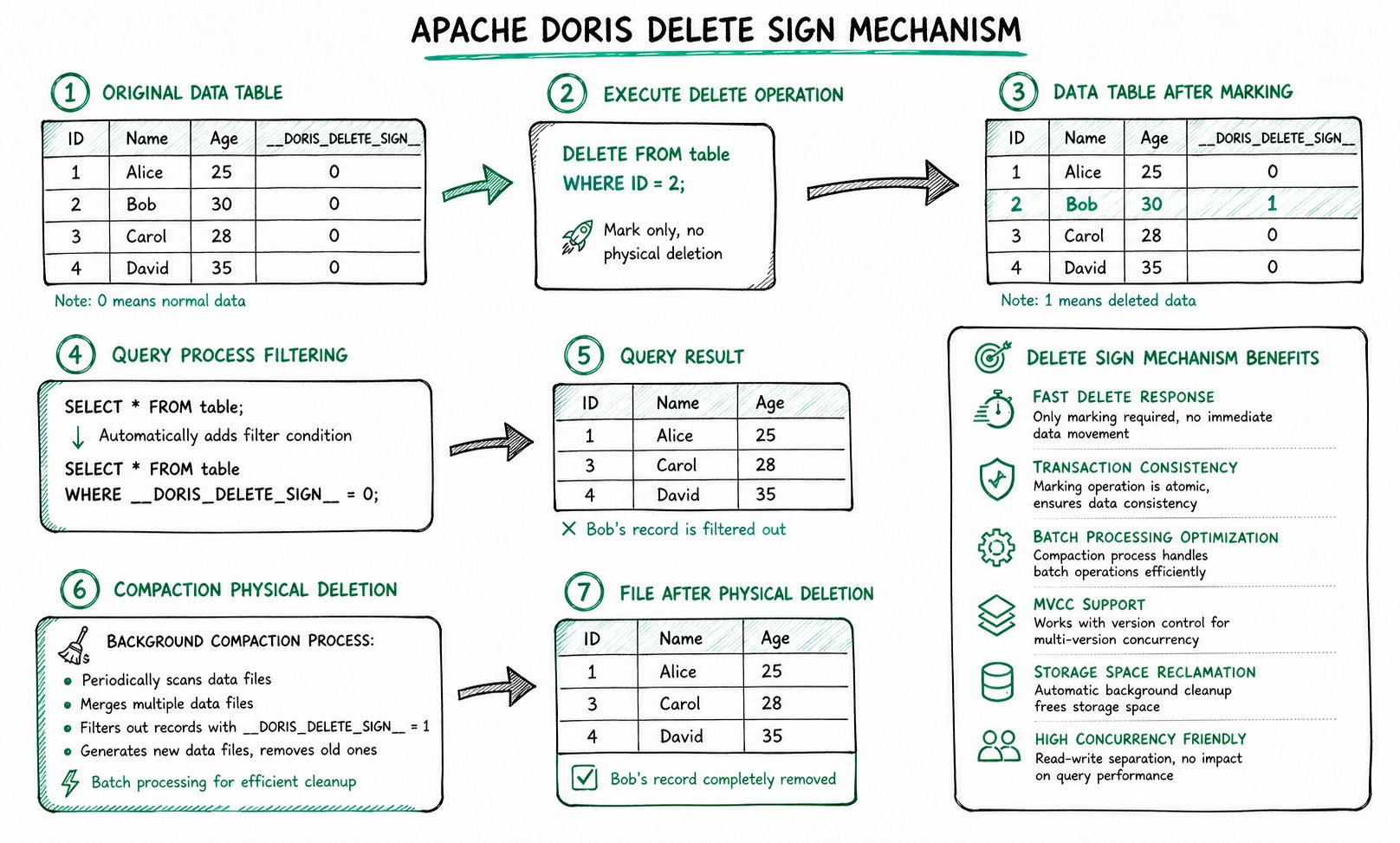
2.3 删除标记的工作流程
__DORIS_DELETE_SIGN__ 采用"逻辑标记,后台清理"的方式,分为三个阶段:
- 执行删除:通过导入或
DELETE语句删除数据时,Doris 不会立即从物理文件移除数据,而是写入一条新记录并将__DORIS_DELETE_SIGN__标记为1。 - 查询过滤:查询时 Doris 自动追加过滤条件
WHERE __DORIS_DELETE_SIGN__ = 0,从结果中隐藏被标记删除的行。 - 后台 Compaction:Compaction 进程发现某主键同时存在正常记录与删除标记记录时,在合并过程中物理移除两条记录,释放存储空间。
2.4 部分列更新
从 2.0 版本起,主键模型(MoW)支持部分列更新:导入时只需提供主键和待更新列,未提供的列保持原值不变。
启用方式:
| 导入方式 | 启用配置 |
|---|---|
INSERT INTO | 设置 session 变量 enable_unique_key_partial_update = true |
| Stream Load 等其他导入 | 配置 partial_columns 参数为 true |
建表时需开启 Merge-on-Write:
CREATE TABLE user_profiles (
user_id BIGINT,
name STRING,
age INT,
last_login DATETIME
)
UNIQUE KEY(user_id)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"enable_unique_key_merge_on_write" = "true"
);
-- 初始数据
-- user_id: 1, name: 'Alice', age: 30, last_login: '2023-10-01 10:00:00'
-- 通过 Stream Load 部分更新,只写入 age 和 last_login
-- {"user_id": 1, "age": 31, "last_login": "2023-10-26 18:00:00"}
-- 更新后数据
-- user_id: 1, name: 'Alice', age: 31, last_login: '2023-10-26 18:00:00'
实现上,主键模型的部分列更新并非原地更新,而是在导入时读取已有列、补齐缺失字段后整行重写。因此存在读放大与写放大:例如 100 列的宽表更新 10 个字段、字段大小相近时,1 MB 的有效更新会引发约 9 MB 数据读取与 10 MB 数据写入。
性能建议:
| 建议项 | 说明 |
|---|---|
| 使用 SSD | 部分列更新会产生大量随机 IO,机械磁盘瓶颈明显,建议使用 SSD(NVMe 优先) |
| 宽表开启行存 | 表很宽时建议开启行存,单次 IO 即可读取整行;列存模式下每个缺失字段都需一次 IO |
完整使用方式(Stream Load、INSERT INTO、Flink Connector 等)详见:列更新。
3. 典型业务场景
3.1 CDC 实时同步
通过 Flink CDC 等工具捕获上游数据库(MySQL、PostgreSQL、Oracle 等)的 Binlog,写入 Doris 主键模型表。
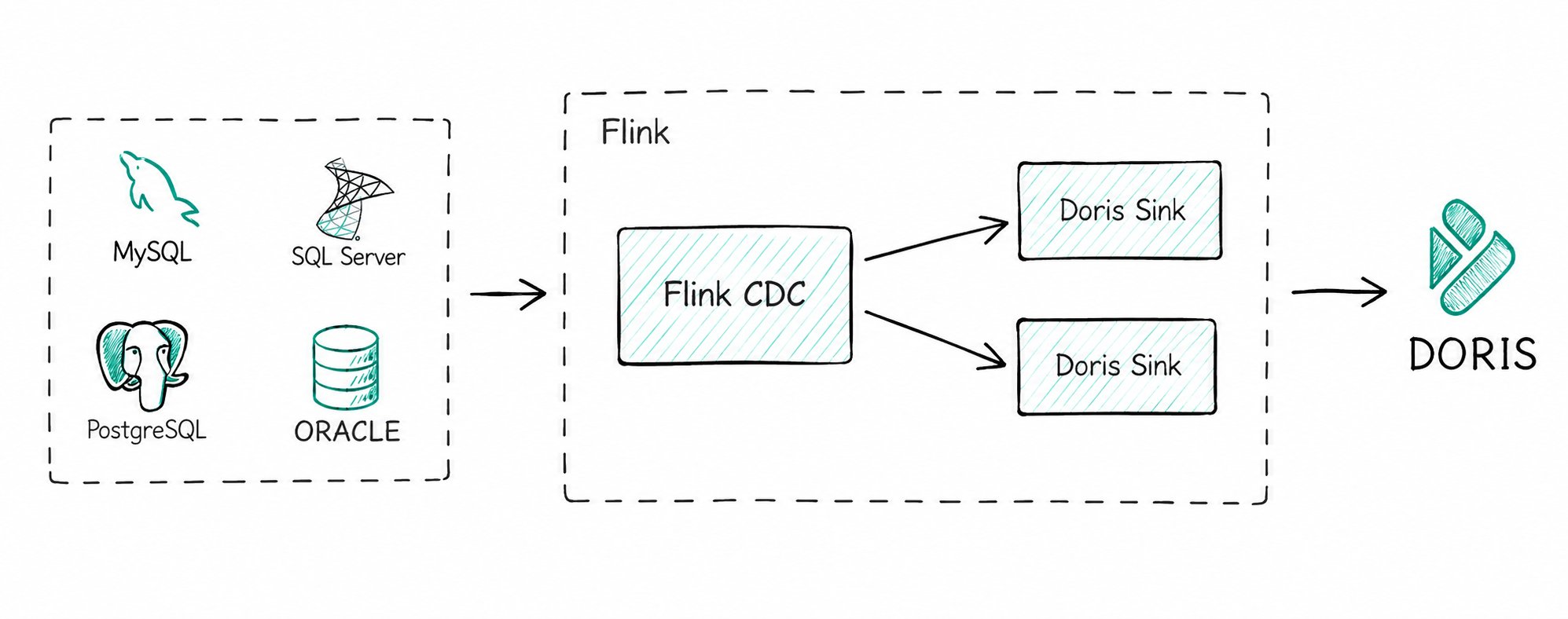
关键能力:
- 整库同步:Flink Doris Connector 内部集成 Flink CDC,可实现端到端整库同步,无需手动建表与字段映射。
- 一致性保证:组合使用以下能力对齐上游数据库状态:
- 主键模型 UPSERT 处理
INSERT/UPDATE; __DORIS_DELETE_SIGN__处理DELETE;- Sequence 列(如 Binlog 时间戳)处理乱序数据。
- 主键模型 UPSERT 处理
3.2 实时宽表拼接
利用部分列更新,可在 Doris 内直接完成多源宽表拼接,无需在 Flink 中做实时 Join:
- 建一张主键模型宽表;
- 不同数据源(基础信息、行为日志、交易数据等)通过 Stream Load / Routine Load 实时写入;
- 每个数据流只写入自己负责的列,例如:
- 用户行为流更新
page_view_count、last_login_time; - 交易流更新
total_orders、total_amount。
- 用户行为流更新
每个流仅写入变化列,可降低 IO 开销并避免实时 Join 的资源消耗。多流并发场景下的版本控制见:主键模型的多流更新。
4. 使用建议
4.1 通用建议
| 序号 | 建议 | 说明 |
|---|---|---|
| 1 | 优先使用导入更新 | 高频、大量更新优先选 Stream Load、Routine Load,而非 UPDATE DML |
| 2 | 攒批写入 | 避免逐条高频 INSERT(> 100 TPS),每条 INSERT 都有事务开销;可开启 Group Commit 合并小批量提交 |
| 3 | 谨慎在明细/聚合模型上高频 DELETE | 谓词累积会影响后续查询性能 |
| 4 | 删除整个分区使用 TRUNCATE PARTITION | 删除整分区时 TRUNCATE PARTITION 比 DELETE 高效得多 |
| 5 | 串行执行 UPDATE | 避免并发执行可能作用于相同主键的 UPDATE 任务 |
4.2 存算分离架构下的主键模型
Doris 3.0 引入存算分离架构。该架构下 BE 无状态,Merge-on-Write 需通过 Meta Service 维护全局状态以解决导入、Compaction、Schema Change 之间的写写冲突,主键模型 MoW 依赖基于 Meta Service 的分布式表锁保证写一致性。
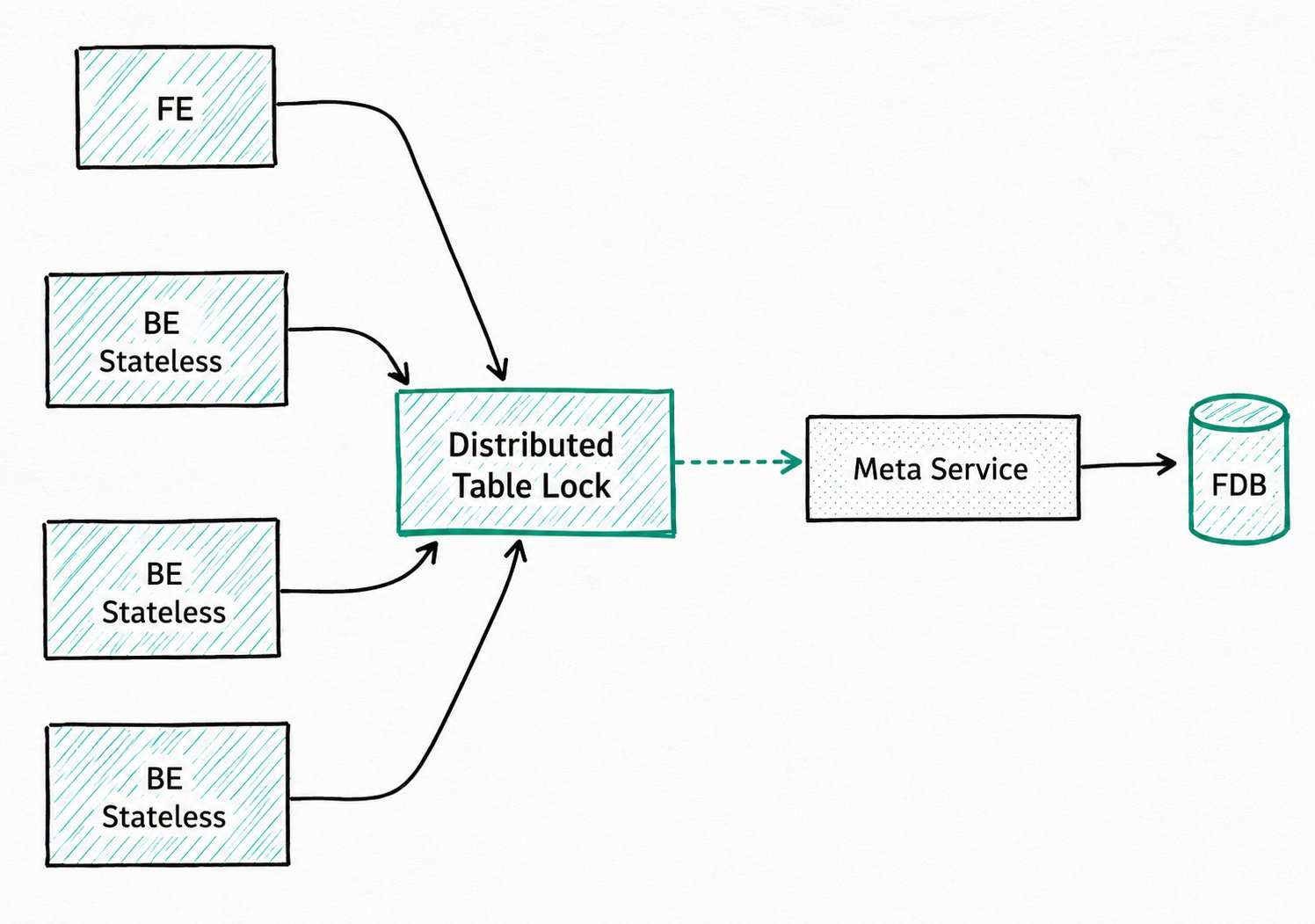
高频导入与 Compaction 会引发表锁竞争,使用时建议:
- 控制单表导入频率:建议单张主键表导入频率不超过 60 次/秒,可通过攒批或调整并发降低;
- 合理设计分区分桶:
- 分区:使用时间分区(按天或按小时),让单次导入只更新少量分区;
- 分桶:分桶数(Tablet 数量)应匹配数据量,通常在 8-64 之间;过多 Tablet 会加剧锁竞争;
- 调整 Compaction 策略:写入压力较大时降低 Compaction 频率,减少与导入任务的锁冲突;
- 使用较新版本:3.1 对分布式表锁实现做了较大优化,建议使用最新稳定版本。