Apache Doris vs Trino / Presto
Apache Doris 和 Trino/Presto 均为主流数据湖仓查询引擎,但 Doris 在性能上表现更具优势。Trino/Presto 主要专注于查询加速,而 Doris 不仅能够加速查询,还具备作为独立数据仓库的能力。企业可以利用 Doris 实现数据仓库和湖仓查询引擎的统一,从而简化其数据架构。
-
统一: Apache Doris 实现数据仓库与湖仓查询引擎统一,有效简化企业技术栈
-
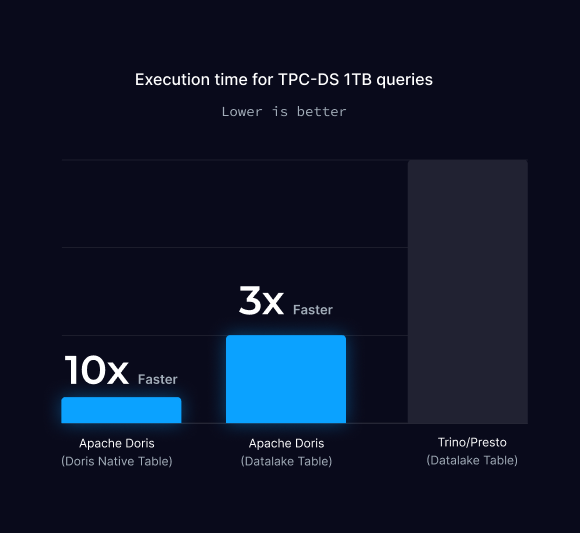
10 倍性能提升: 相较于 Presto/Trino,Doris 内表查询性能最高提升达 10 倍。
-
2~3 倍 执行效率: 作为湖仓引擎,Doris 执行效率较 Presto/Trino快 2-3 倍。
精选案例
“早期我们使用多个系统(如 Trino、Pinot、Iceberg 和 Kyuubi)构建数据平台,导致架构复杂、数据重复存储、运维困难、资源利用率低和数据时效性差。通过引入 Apache Doris 替换多个技术栈,实现湖仓一体化,显著提高了查询性能和系统稳定性,并降低了 30% 的资源成本。”
“迁移到 Doris 后,整体查询性能得到大幅提升。之前使用 Presto 进行多维分析时,查询时间长达 20-40 秒,而 Doris 将这一时间缩短至 1-2 秒。此外,Doris 的一大优势在于能够自动识别并匹配最优物化视图进行查询,这进一步增强了系统复杂分析的性能。”
使用 Trino 和 SparkSQL 时,系统查询延迟普遍维持在分钟级别,存在明显的性能瓶颈。迁移至 Apache Doris 后,整体查询性能提升 2 倍以上。通过 Doris 统一架构,有效解决了混合架构下的数据孤岛与资源冗余问题,更加速了实时分析与交互式即席查询响应。
Apache Doris vs. Trino / Presto
| Apache Doris | Trino / Presto | |
|---|---|---|
| 系统架构 |
|
|
| 执行引擎 |
|
|
| 查询优化 |
|
|
| 缓存机制 |
|
|
| 物化视图 |
|
|
| 应用场景 |
|
|
性能对比
TPC-DS 1TB 性能测试
TPC-DS 1TB Benchmark 包含 24 张表、63.5 亿条记录的 1TB 数据集,通过 99 条复杂查询(涵盖关联查询、聚合运算及嵌套子查询)评估数据仓库的性能。该测试基于雪花模型构建,模拟真实电商销售场景,由于查询的复杂性,在处理 1TB 规模数据时是一项挑战。
测试环境配置包括:
- 1 个 FE/Coordinator 节点 and 5 个 BE/Worker 节点
- 单节点 64 核 CPU、1.5TB 内存以及 SSD 存储
- HDFS 部署在计算节点上,并创建 Hive 表
在测试过程中,使用相同的数据集和相等的计算服务,结果显示:
- 当数据导入 Doris 内表并使用 Doris 执行查询时,整体查询耗时最短
- 当 Doris 与 Trino 分别对外部 Hive 表查询时,Doris 在数据湖场景展现更优的查询加速性能