Doris Operator 状态与排障
Doris Operator 会把组件状态写入 Doris 自定义资源的 status 字段。排查 Doris on Kubernetes 问题时,建议先查看 CR 状态,再继续查看 Operator 日志、Kubernetes 资源和 Doris 组件日志。
查看资源状态
存算一体集群使用 DorisCluster,通常简写为 dcr:
kubectl get dcr -n ${namespace}
kubectl describe dcr ${cluster_name} -n ${namespace}
存算分离集群使用 DorisDisaggregatedCluster,通常简写为 ddc:
kubectl get ddc -n ${namespace}
kubectl describe ddc ${cluster_name} -n ${namespace}
如果 CR 显示组件未就绪,再继续查看底层资源:
kubectl get pod,sts,svc,pvc -n ${namespace}
kubectl get event -n ${namespace} --sort-by=.lastTimestamp
DorisCluster 状态
DorisCluster.status 按组件汇总:
| 字段 | 说明 |
|---|---|
feStatus | FE 状态 |
beStatus | BE 状态 |
cnStatus | CN 状态 |
brokerStatus | Broker 状态 |
每个组件状态通常包含:
| 字段 | 说明 |
|---|---|
accessService | 组件对外访问 Service |
runningInstances | 正在运行的实例 |
creatingInstances | 正在创建的实例 |
failedInstances | 失败实例 |
componentCondition.phase | 当前组件阶段 |
componentCondition.reason | 当前阶段原因 |
componentCondition.message | 可读状态说明 |
常见 phase 包括:
| Phase | 含义 |
|---|---|
available | 组件可用 |
reconciling | Operator 正在收敛资源 |
waitScheduling | 正在等待调度或依赖资源就绪 |
haveMemberFailed | 至少存在一个失败实例 |
initializing | 组件初始化中 |
upgrading | 组件升级中 |
scaling | 组件扩缩容中 |
restarting | 组件重启中 |
DorisDisaggregatedCluster 状态
DorisDisaggregatedCluster.status 包含组件状态和整体健康度。
| 字段 | 说明 |
|---|---|
metaServiceStatus | MetaService 状态 |
feStatus | FE 状态 |
computeGroupStatuses | ComputeGroup 状态列表 |
clusterHealth | 集群整体健康度 |
observedGeneration | Operator 已观察到的资源版本 |
clusterHealth 反映整体可用性:
| 字段 | 说明 |
|---|---|
health | 整体健康度,例如 green、yellow、red |
feAvailable | FE 是否可用 |
cgCount | ComputeGroup 数量 |
cgAvailableCount | 可用 ComputeGroup 数量 |
cgFullAvailableCount | 所有 Pod 都可用的 ComputeGroup 数量 |
| Health | 含义 |
|---|---|
green | 核心组件可用,ComputeGroup 可用情况符合预期 |
yellow | 集群部分可用,但尚未完全就绪 |
red | 核心组件不可用,或可用 ComputeGroup 数量不足 |
ComputeGroup 的 phase 可能包括 Ready、Reconciling、Scaling、Decommissioning、ScaleDownFailed、Suspended。
推荐排障路径
建议按下面的顺序推进:
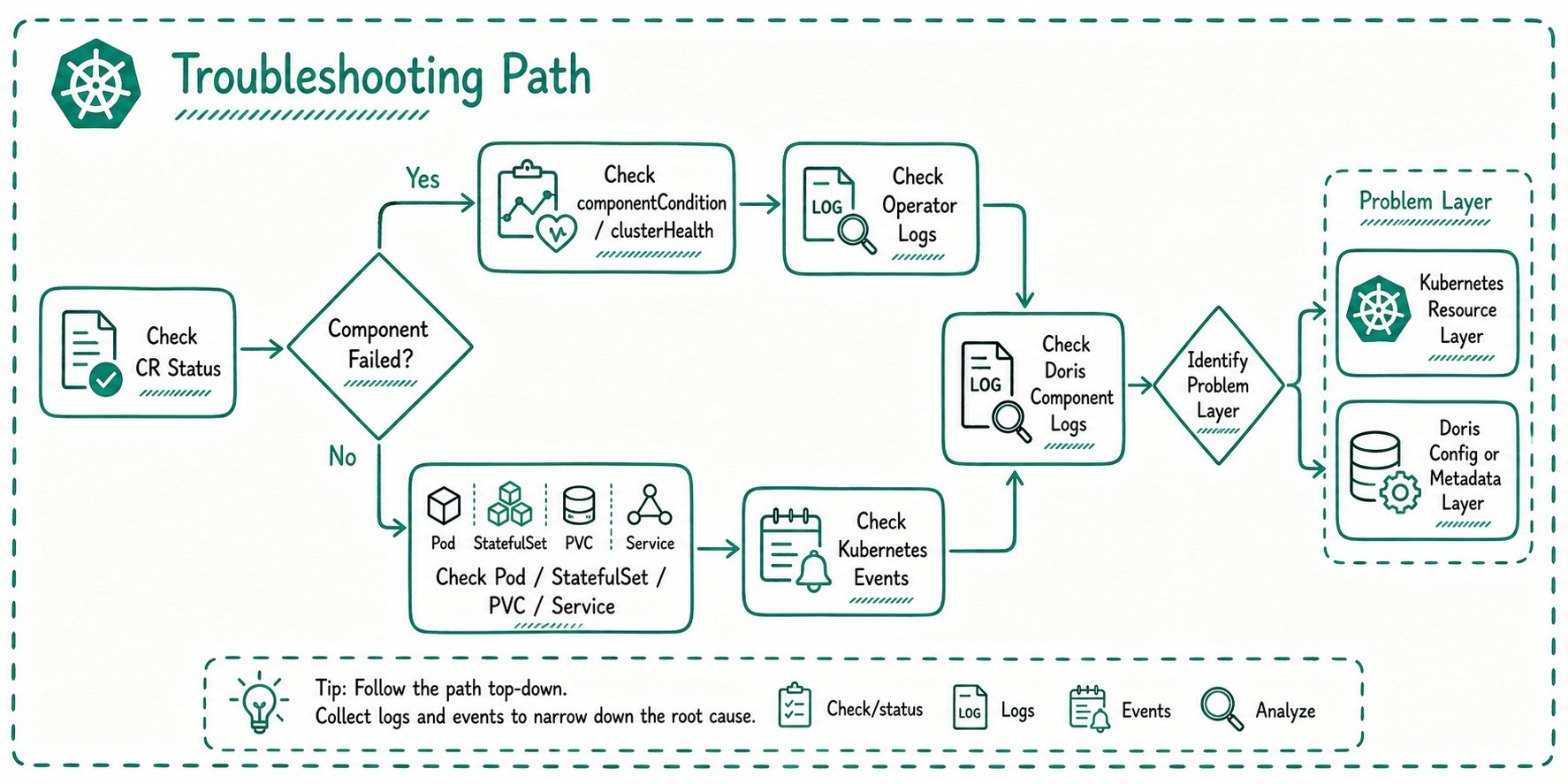
常见入口
Pod 长时间 Pending
常见原因:
- 节点 CPU 或内存不足。
- 节点选择器、亲和性或容忍配置不匹配。
- PVC 绑定失败。
kubectl describe pod ${pod_name} -n ${namespace}
kubectl get event -n ${namespace} --sort-by=.lastTimestamp
kubectl get pvc -n ${namespace}
PVC 无法绑定
常见原因:
- StorageClass 不存在。
- 存储容量不足。
- 访问模式不匹配。
kubectl get storageclass
kubectl describe pvc ${pvc_name} -n ${namespace}
组件反复重启
常见原因:
- Doris 启动配置错误。
- 端口冲突或 FQDN 配置不正确。
- 存储权限或挂载路径异常。
- JVM 或系统参数不满足要求。
kubectl logs ${pod_name} -n ${namespace}
kubectl describe pod ${pod_name} -n ${namespace}
如果 Pod 处于 CrashLoopBackOff 且普通日志不足以定位问题,可以参考集群运维文档中的 Debug 流程进入容器排查。
Service 无法访问
常见原因:
- 把 internal Service 当作外部访问入口。
- Service 类型与访问环境不匹配。
- Pod 未 Ready,导致 Endpoints 为空。
- 云厂商 LoadBalancer 创建失败。
kubectl get svc -n ${namespace}
kubectl get endpoints -n ${namespace}
kubectl describe svc ${service_name} -n ${namespace}
配置变更未生效
常见原因:
- ConfigMap 已更新,但组件未重启。
- ConfigMap key 与组件要求不匹配。
- CR 未正确引用 ConfigMap。
- 挂载路径与配置文件路径不一致。
kubectl get configmap -n ${namespace}
kubectl describe dcr ${cluster_name} -n ${namespace}
kubectl describe ddc ${cluster_name} -n ${namespace}
对存算一体集群,如果预期核心 ConfigMap 变更后自动触发滚动重启,需要确认是否配置了 enableRestartWhenConfigChange。
authSecret 配置问题
Doris Operator 在执行节点注册、缩容、下线等管理动作时,可能需要使用 Doris 管理凭证。authSecret 配置错误会导致这些动作无法完成。
常见原因:
- 引用的 Secret 不存在或命名空间错误。
- Secret 类型或 key 不正确。
- 用户名或密码与 Doris 管理账号不一致。
- 管理账号缺少必要权限。
kubectl get secret ${auth_secret_name} -n ${namespace}
kubectl describe dcr ${cluster_name} -n ${namespace}
kubectl describe ddc ${cluster_name} -n ${namespace}
kubectl logs deployment/${operator_deployment_name} -n ${operator_namespace}
如果集群已设置 root 密码,或者使用了非默认管理账号,需要确认 authSecret 与实际 Doris 凭证一致。
ComputeGroup 缩容未完成
在存算分离集群中,ComputeGroup 缩容可能长时间停留在 Decommissioning 或 ScaleDownFailed。
常见原因:
- Doris 元数据层 decommission 尚未完成。
- FE 不可用。
- 管理凭证错误。
- 目标节点仍有数据迁移或清理任务。
kubectl describe ddc ${cluster_name} -n ${namespace}
kubectl logs deployment/${operator_deployment_name} -n ${operator_namespace}
必要时还需要进入 Doris 查看对应节点和 ComputeGroup 的状态。
Operator 日志
当 CR 状态不足以说明具体原因时,应查看 Doris Operator 日志:
kubectl get pod -n ${operator_namespace}
kubectl logs ${operator_pod_name} -n ${operator_namespace}