日志存储与分析
日志是系统运行的详细记录,包含事件主体、时间、位置、内容等关键信息。出于运维可观测、网络安全监控及业务分析等多重需求,企业通常需要将分散的日志集中采集、存储与分析,以从海量日志中挖掘价值。
针对此场景,Apache Doris 在通用 OLAP 能力之外,新增了倒排索引和极速全文检索能力,并对写入性能与存储空间进行了极致优化。基于 Apache Doris,用户可以构建开放、高性能、低成本、统一的日志存储与分析平台。
本文围绕该解决方案介绍以下内容:
- 整体架构:基于 Apache Doris 的日志平台核心组成与基础架构。
- 特点与优势:相对于 Elasticsearch 的差异化能力。
- 操作指南:从资源评估到日志查询的端到端落地步骤。
1. 整体架构
基于 Apache Doris 构建的日志存储与分析平台架构如下图所示:

整个架构由 3 大部分组成:
| 层级 | 组成 | 说明 |
|---|---|---|
| 日志采集与预处理 | Logstash、Filebeat、Fluentbit、Kafka 等 | 通过 HTTP API 将日志数据写入 Apache Doris |
| 日志存储与分析 | Apache Doris | 提供高性能、低成本的统一存储,并通过 SQL 接口提供丰富检索分析能力 |
| 日志分析与告警 | Grafana、Superset、Doris WebUI 等 | 通过标准 MySQL 协议查询 Doris,提供易用的可视化界面 |
2. 特点与优势
基于 Apache Doris 构建的日志平台具备以下核心能力:
| 能力维度 | 说明 |
|---|---|
| 高吞吐、低延迟写入 | 支持每天百 TB 级、GB/s 级日志数据持续稳定写入,延迟控制在 1 秒以内 |
| 海量数据低成本存储 | 支持 PB 级存储,相对 Elasticsearch 节省 60%–80% 存储成本,冷数据存储到 S3/HDFS 后再降 50% |
| 高性能全文检索分析 | 支持倒排索引和全文检索,关键词检索明细、趋势分析等查询秒级响应 |
| 开放、易用的生态 | 上游对接 Logstash、Filebeat、Fluentbit、Kafka 等;下游通过标准 MySQL 协议对接 Grafana、Superset、Doris WebUI |
2.1 高性能、低成本
经过 Benchmark 测试与生产验证,基于 Apache Doris 构建的日志平台性价比相对于 Elasticsearch 有 5~10 倍的提升。优势主要源自高性能存储与查询引擎,以及针对日志场景的专门优化:
- 写入吞吐提升:Elasticsearch 写入瓶颈在于解析数据和构建倒排索引的 CPU 消耗。Apache Doris 利用 SIMD 等 CPU 向量化指令提升 JSON 解析与索引构建性能,并简化了倒排索引结构,去掉日志场景不需要的正排等数据结构。同样资源下,Doris 写入性能是 Elasticsearch 的 3~5 倍。
- 存储成本降低:Elasticsearch 存在正排、倒排、Docvalue 列存多份存储和通用压缩率较低的瓶颈。Doris 去掉正排,缩减 30% 索引数据量;采用列式存储和 Zstandard 压缩算法,压缩比 5~10 倍,远高于 Elasticsearch 的 1.5 倍;冷热分层功能可将历史日志自动转存到对象存储,冷数据存储成本降低 70% 以上。整体存储成本仅为 Elasticsearch 的 20% 左右。
- 查询性能提升:Doris 简化了全文检索流程,跳过相关性打分等日志场景不需要的算法;针对“查询包含某关键字的最新 100 条日志”等典型查询,在查询规划与执行上做了 TopN 动态剪枝等专门优化。
2.2 强大的分析能力
Apache Doris 支持标准 SQL,兼容 MySQL 协议与语法,因此基于 Doris 构建的日志系统具备以下优势:
- 简单易用:工程师与数据分析师对 SQL 非常熟悉,无需学习新技术栈即可快速上手。
- 生态丰富:可与 MySQL 命令行、各类 GUI/BI 工具及大数据生态无缝集成,满足复杂、多样化的数据处理分析需求。
- 分析能力强:SQL 是数据分析的事实标准,支持检索、聚合、多表 JOIN、子查询、UDF、逻辑视图、物化视图等多种分析能力。
2.3 灵活的 Schema
下面是一个典型的 JSON 格式半结构化日志样例。顶层字段相对固定(timestamp、source、node、component、level、clientRequestId、message、properties),而扩展属性 properties 内部嵌套字段(如 properties.size、properties.format)较为动态,每条日志的字段可能不同。
{
"timestamp": "2014-03-08T00:50:03.8432810Z",
"source": "ADOPTIONCUSTOMERS81",
"node": "Engine000000000405",
"level": "Information",
"component": "DOWNLOADER",
"clientRequestId": "671db15d-abad-94f6-dd93-b3a2e6000672",
"message": "Downloading file path: benchmark/2014/ADOPTIONCUSTOMERS81_94_0.parquet.gz",
"properties": {
"size": 1495636750,
"format": "parquet",
"rowCount": 855138,
"downloadDuration": "00:01:58.3520561"
}
}
Apache Doris 通过以下两种机制支持 Flexible Schema:
- Light Schema Change:顶层字段少量变化时,可通过
ADD/DROP COLUMN、ADD/DROP INDEX在秒级完成 Schema 变更。规划阶段只需考虑当前需要为哪些字段创建索引。 - VARIANT 半结构化类型:对于类似
properties的扩展字段,可写入任意 JSON 数据,自动识别字段名和类型,并将频繁出现的字段拆分为列式存储;还可对VARIANT创建倒排索引,加快内部字段的查询和检索。
相对于 Elasticsearch 的 Dynamic Mapping,Apache Doris 的 Flexible Schema 优势如下:
- 允许同一字段拥有多种类型,
VARIANT自动做冲突处理与类型提升,更好适应日志数据的迭代变化。 VARIANT自动将不频繁出现的字段合并为一个列存储,避免字段、元数据、列过多导致性能问题。- 支持动态加列、动态删列、动态增加索引、动态删除索引,无需在一开始就为所有字段建索引,减少不必要的成本。
3. 操作指南
下表是基于 Apache Doris 构建日志平台的端到端 6 步流程:
| 步骤 | 目的 |
|---|---|
| 第 1 步:评估资源 | 估算 FE/BE 节点数量、磁盘容量与对象存储规模 |
| 第 2 步:部署集群 | 在物理机或虚拟机环境部署 Apache Doris |
| 第 3 步:优化 FE 和 BE 配置 | 针对日志场景调整关键参数 |
| 第 4 步:建表 | 设计分区分桶、压缩、Compaction、索引与冷热分层策略 |
| 第 5 步:采集日志 | 对接 Logstash、Filebeat、Kafka 或自定义程序 |
| 第 6 步:查询和分析日志 | 通过 SQL 与可视化工具进行检索与分析 |
3.1 评估资源
在部署集群之前,需评估服务器硬件资源,关键步骤如下:
-
评估写入资源,计算公式如下:
平均写入吞吐 = 日增数据量 / 86400 s峰值写入吞吐 = 平均写入吞吐 * 写入吞吐峰值 / 均值比峰值写入所需 CPU 核数 = 峰值写入吞吐 / 单核写入吞吐
-
评估存储资源,计算公式如下:
所需存储空间 = 日增数据量 / 压缩率 * 副本数 * 数据存储周期
-
评估查询资源:查询资源消耗随查询量与复杂度而异。建议初始预留 50% 的 CPU 资源用于查询,再根据实际测试情况调整。
-
汇总整合资源:由步骤 1、3 估算所需 CPU 核数,除以单机 CPU 核数得到 BE 服务器数量;再结合步骤 2 估算每台 BE 所需存储空间,分摊到 4~12 块数据盘,计算单盘容量。
示例:每天新增 100 TB 日志的资源估算
以以下条件为例:每天新增 100 TB 数据量(压缩前)、5 倍压缩率、1 副本、热数据存储 3 天、冷数据存储 30 天、写入吞吐峰值/均值比 200%、单核写入吞吐 10 MB/s、查询预留 50% CPU 资源。可估算得:
- FE:3 台服务器,每台 16 核 CPU、64 GB 内存、1 块 100 GB SSD 盘
- BE:15 台服务器,每台 32 核 CPU、256 GB 内存、10 块 600 GB SSD 盘
- S3 对象存储空间:即冷数据存储空间,600 TB
各关键指标的取值与计算方式如下表:
| 关键指标(单位) | 值 | 说明 |
|---|---|---|
| 日增数据量(TB) | 100 | 根据实际需求填写 |
| 压缩率 | 5 | 一般为 3~10 倍(含索引),根据实际需求填写 |
| 副本数 | 1 | 根据实际需求填写,默认 1 副本,可选值:1、2、3 |
| 热数据存储周期(天) | 3 | 根据实际需求填写 |
| 冷数据存储周期(天) | 30 | 根据实际需求填写 |
| 总存储周期(天) | 33 | 算法:热数据存储周期 + 冷数据存储周期 |
| 预估热数据存储空间(TB) | 60 | 算法:日增数据量 / 压缩率 * 副本数 * 热数据存储周期 |
| 预估冷数据存储空间(TB) | 600 | 算法:日增数据量 / 压缩率 * 副本数 * 冷数据存储周期 |
| 写入吞吐峰值 / 均值比 | 200% | 根据实际需求填写,默认 200% |
| 单机 CPU 核数 | 32 | 根据实际需求填写,默认 32 核 |
| 平均写入吞吐(MB/s) | 1214 | 算法:日增数据量 / 86400 s |
| 峰值写入吞吐(MB/s) | 2427 | 算法:平均写入吞吐 * 写入吞吐峰值 / 均值比 |
| 峰值写入所需 CPU 核数 | 242.7 | 算法:峰值写入吞吐 / 单核写入吞吐 |
| 查询预留 CPU 百分比 | 50% | 根据实际需求填写,默认 50% |
| 预估 BE 服务器数 | 15.2 | 算法:峰值写入所需 CPU 核数 / 单机 CPU 核数 / (1 - 查询预留 CPU 百分比) |
| 预估 BE 服务器数取整 | 15 | 算法:MAX(副本数, 预估 BE 服务器数取整) |
| 预估每台 BE 服务器存储空间(TB) | 5.7 | 算法:预估热数据存储空间 / 预估 BE 服务器数 / (1 - 30%),其中 30% 为存储空间预留值。建议每台 BE 挂载 4~12 块数据盘,以提高 I/O 能力 |
3.2 部署集群
完成资源评估后,可以开始部署 Apache Doris 集群。推荐在物理机或虚拟机环境中部署,手动部署步骤可参考 手动部署。
3.3 优化 FE 和 BE 配置
完成集群部署后,需分别针对 FE 与 BE 调整参数,以更契合日志存储与分析场景。
3.3.1 优化 FE 配置
在 fe/conf/fe.conf 中按下表调整 FE 配置:
| 需调整参数 | 说明 |
|---|---|
max_running_txn_num_per_db = 10000 | 高并发导入运行事务数较多,需调高该参数 |
streaming_label_keep_max_second = 3600label_keep_max_second = 7200 | 高频导入事务标签内存占用多,保留时间调短 |
enable_round_robin_create_tablet = true | 创建 Tablet 时采用 Round Robin 策略,尽量均匀 |
tablet_rebalancer_type = partition | 均衡 Tablet 时采用每个分区内尽量均匀的策略 |
autobucket_min_buckets = 10 | 将自动分桶的最小分桶数从 1 调大到 10,避免日志量增加时分桶不够 |
max_backend_heartbeat_failure_tolerance_count = 10 | 日志场景下 BE 服务器压力较大,可能短时间心跳超时,将容忍次数从 1 调大到 10 |
更多参数信息可参考 FE 配置项。
3.3.2 优化 BE 配置
在 be/conf/be.conf 中按下表调整 BE 配置:
| 模块 | 需调整参数 | 说明 |
|---|---|---|
| 存储 | storage_root_path = /path/to/dir1;/path/to/dir2;...;/path/to/dir12 | 配置热数据在磁盘目录上的存储路径 |
| 存储 | enable_file_cache = true | 开启文件缓存 |
| 存储 | file_cache_path = [{"path": "/mnt/datadisk0/file_cache", "total_size":53687091200, "query_limit": "10737418240"},{"path": "/mnt/datadisk1/file_cache", "total_size":53687091200,"query_limit": "10737418240"}] | 配置冷数据的缓存路径与设置:path:缓存路径total_size:该缓存路径的总大小,单位字节,53687091200 字节 = 50 GBquery_limit:单次查询可从缓存路径查询的最大数据量,单位字节,10737418240 字节 = 10 GB |
| 写入 | write_buffer_size = 1073741824 | 增大写入缓冲区文件大小,减少小文件与随机 I/O,提升性能 |
| Compaction | max_cumu_compaction_threads = 8 | 设为 CPU 核数 / 4,意味着 1/4 CPU 用于写入、1/4 用于后台 Compaction,1/2 留给查询和其他操作 |
| Compaction | inverted_index_compaction_enable = true | 开启索引合并(Index Compaction),减少 Compaction 时的 CPU 消耗 |
| Compaction | enable_segcompaction = falseenable_ordered_data_compaction = false | 关闭日志场景不需要的两个 Compaction 功能 |
| Compaction | enable_compaction_priority_scheduling = false | 低优先级 Compaction 在一块盘上限制 2 个任务,会影响 Compaction 速度 |
| Compaction | total_permits_for_compaction_score = 200000 | 用于控制内存,Time Series 策略下本身可控制内存 |
| 缓存 | disable_storage_page_cache = trueinverted_index_searcher_cache_limit = 30% | 日志数据量较大,数据缓存作用有限,关闭数据缓存改用索引缓存 |
| 缓存 | inverted_index_cache_stale_sweep_time_sec = 3600index_cache_entry_stay_time_after_lookup_s = 3600 | 让索引缓存在内存中尽量保留 1 小时 |
| 缓存 | enable_inverted_index_cache_on_cooldown = trueenable_write_index_searcher_cache = false | 开启索引上传冷数据存储时自动缓存的功能 |
| 缓存 | tablet_schema_cache_recycle_interval = 3600segment_cache_capacity = 20000 | 减少其他缓存对内存的占用 |
| 缓存 | inverted_index_ram_dir_enable = true | 减少写入时索引临时文件带来的 I/O 开销 |
| 线程 | pipeline_executor_size = 24doris_scanner_thread_pool_thread_num = 48 | 32 核 CPU 的计算线程与 I/O 线程配置,根据核数等比扩缩 |
| 线程 | scan_thread_nice_value = 5 | 降低查询 I/O 线程优先级,保证写入性能与时效性 |
| 其他 | string_type_length_soft_limit_bytes = 10485760 | 将 String 类型数据的长度限制调高至 10 MB |
| 其他 | trash_file_expire_time_sec = 300path_gc_check_interval_second = 900path_scan_interval_second = 900 | 调快垃圾文件的回收时间 |
更多参数信息可参考 BE 配置项。
3.4 建表
由于日志数据的写入与查询都具备明显特征,因此建表时按以下章节进行针对性配置,以提升性能。
3.4.1 配置分区分桶参数
分区:
- 使用时间字段上的 Range 分区(
PARTITION BY RANGE(ts)),并开启 动态分区("dynamic_partition.enable" = "true"),按天自动管理分区。 - 使用 Datetime 类型的时间字段作为 Key(
DUPLICATE KEY(ts)),在查询最新 N 条日志时有数倍加速。
分桶:
- 分桶数量大致为集群磁盘总数的 3 倍,每个桶压缩后数据量 5 GB 左右。
- 使用 Random 策略(
DISTRIBUTED BY RANDOM BUCKETS 60),配合写入时的 Single Tablet 导入,可提升批量(Batch)写入效率。
更多分区分桶信息可参考 数据划分。
3.4.2 配置压缩参数
- 使用 Zstd 压缩算法(
"compression" = "zstd"),提高数据压缩率。
3.4.3 配置 Compaction 参数
- 使用 Time Series 策略(
"compaction_policy" = "time_series"),减轻写放大效应,对高吞吐日志写入的资源消耗很重要。
3.4.4 建立和配置索引
- 对经常查询的字段建立索引(
USING INVERTED)。 - 对需要全文检索的字段,将分词器(
parser)参数设置为unicode,一般可满足大部分需求。如需支持短语查询,将support_phrase参数设为true;不需要时设为false,以降低存储空间。
3.4.5 配置存储策略
- 热数据存储:使用云盘可配置 1 副本;使用物理盘则至少配置 2 副本(
"replication_num" = "2")。 - 冷热分层:配置
log_s3存储位置(CREATE RESOURCE "log_s3"),并设置log_policy_3day冷热分层策略(CREATE STORAGE POLICY log_policy_3day),即超过 3 天的数据自动冷却至log_s3指定的存储位置。
3.4.6 完整建表示例
CREATE DATABASE log_db;
USE log_db;
CREATE RESOURCE "log_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "your_endpoint_url",
"s3.region" = "your_region",
"s3.bucket" = "your_bucket",
"s3.root.path" = "your_path",
"s3.access_key" = "your_ak",
"s3.secret_key" = "your_sk"
);
CREATE STORAGE POLICY log_policy_3day
PROPERTIES(
"storage_resource" = "log_s3",
"cooldown_ttl" = "259200"
);
CREATE TABLE log_table
(
`ts` DATETIME,
`host` TEXT,
`path` TEXT,
`message` TEXT,
INDEX idx_host (`host`) USING INVERTED,
INDEX idx_path (`path`) USING INVERTED,
INDEX idx_message (`message`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true")
)
ENGINE = OLAP
DUPLICATE KEY(`ts`)
PARTITION BY RANGE(`ts`) ()
DISTRIBUTED BY RANDOM BUCKETS 60
PROPERTIES (
"compression" = "zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "60",
"dynamic_partition.replication_num" = "2", -- 存算分离不需要
"replication_num" = "2", -- 存算分离不需要
"storage_policy" = "log_policy_3day" -- 存算分离不需要
);
3.5 采集日志
完成建表后即可进行日志采集。Apache Doris 提供开放、通用的 Stream HTTP API,可与常用日志采集器(Logstash、Filebeat、Kafka 等)打通。下表概括了不同采集方式的适用场景:
| 采集方式 | 适用场景 |
|---|---|
| Logstash | 已有 Logstash 管道、需要丰富的过滤器与插件生态 |
| Filebeat | 轻量级文件采集,资源占用敏感场景 |
| Kafka Routine Load | 日志已落 Kafka,需要由 Doris 主动拉取 |
| 自定义程序(Stream Load) | 自研采集程序、特殊数据源对接 |
3.5.1 对接 Logstash
按以下步骤操作:
-
下载并安装 Logstash Doris Output 插件,可任选一种方式:
-
直接下载:点此下载。
-
从源码编译,并运行下方命令安装:
./bin/logstash-plugin install logstash-output-doris-1.2.0.gem
-
-
配置 Logstash,需配置以下两个文件:
-
logstash.yml:配置 Logstash 批处理日志的条数与时间,用于提升写入性能。pipeline.batch.size: 1000000
pipeline.batch.delay: 10000 -
logstash_demo.conf:配置所采集日志的输入路径与输出到 Apache Doris 的设置。input {
file {
path => "/path/to/your/log"
}
}
output {
doris {
http_hosts => [ "<http://fehost1:http_port>", "<http://fehost2:http_port>", "<http://fehost3:http_port>" ]
user => "your_username"
password => "your_password"
db => "your_db"
table => "your_table"
# doris stream load http headers
headers => {
"format" => "json"
"read_json_by_line" => "true"
"load_to_single_tablet" => "true"
}
# field mapping: doris fileld name => logstash field name
# %{} to get a logstash field, [] for nested field such as [host][name] for host.name
mapping => {
"ts" => "%{@timestamp}"
"host" => "%{[host][name]}"
"path" => "%{[log][file][path]}"
"message" => "%{message}"
}
log_request => true
log_speed_interval => 10
}
}
-
-
运行 Logstash,采集日志并输出至 Apache Doris:
./bin/logstash -f logstash_demo.conf
更多配置说明可参考 Logstash Doris Output Plugin。
3.5.2 对接 Filebeat
按以下步骤操作:
-
获取支持输出至 Apache Doris 的 Filebeat 二进制文件。可 点此下载 或从 Apache Doris 源码编译。
-
配置 Filebeat,主要文件
filebeat_demo.yml,配置所采集日志的输入路径与输出到 Apache Doris 的设置:# input
filebeat.inputs:
- type: log
enabled: true
paths:
- /path/to/your/log
# multiline 可以将跨行的日志(比如 Java stacktrace)拼接起来
multiline:
type: pattern
# 效果:以 yyyy-mm-dd HH:MM:SS 开头的行认为是一条新的日志,其他都拼接到上一条日志
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}'
negate: true
match: after
skip_newline: true
processors:
# 用 js script 插件将日志中的 \t 替换成空格,避免 JSON 解析报错
- script:
lang: javascript
source: >
function process(event) {
var msg = event.Get("message");
msg = msg.replace(/\t/g, " ");
event.Put("message", msg);
}
# 用 dissect 插件做简单的日志解析
- dissect:
# 2024-06-08 18:26:25,481 INFO (report-thread|199) [ReportHandler.cpuReport():617] begin to handle
tokenizer: "%{day} %{time} %{log_level} (%{thread}) [%{position}] %{content}"
target_prefix: ""
ignore_failure: true
overwrite_keys: true
# queue and batch
queue.mem:
events: 1000000
flush.min_events: 100000
flush.timeout: 10s
# output
output.doris:
fenodes: [ "http://fehost1:http_port", "http://fehost2:http_port", "http://fehost3:http_port" ]
user: "your_username"
password: "your_password"
database: "your_db"
table: "your_table"
# output string format
## %{[agent][hostname]} %{[log][file][path]} 是filebeat自带的metadata
## 常用的 filebeat metadata 还是有采集时间戳 %{[@timestamp]}
## %{[day]} %{[time]} 是上面 dissect 解析得到字段
codec_format_string: '{"ts": "%{[day]} %{[time]}", "host": "%{[agent][hostname]}", "path": "%{[log][file][path]}", "message": "%{[message]}"}'
headers:
format: "json"
read_json_by_line: "true"
load_to_single_tablet: "true" -
运行 Filebeat,采集日志并输出至 Apache Doris:
chmod +x filebeat-doris-2.1.1
./filebeat-doris-2.1.1 -c filebeat_demo.yml
更多配置说明可参考 Beats Doris Output Plugin。
3.5.3 对接 Kafka
将 JSON 格式的日志写入 Kafka 消息队列,创建 Kafka Routine Load 即可让 Apache Doris 从 Kafka 主动拉取数据。
参考下方示例,其中 property.* 是 Librdkafka 客户端相关配置,根据实际 Kafka 集群情况调整:
-- 准备好 kafka 集群和 topic log__topic_
-- 创建 routine load,从 kafka log__topic_ 将数据导入 log_table 表
CREATE ROUTINE LOAD load_log_kafka ON log_db.log_table
COLUMNS(ts, host, path, message)
PROPERTIES (
"max_batch_interval" = "60",
"max_batch_rows" = "20000000",
"max_batch_size" = "1073741824",
"load_to_single_tablet" = "true",
"format" = "json"
)
FROM KAFKA (
"kafka_broker_list" = "host:port",
"kafka_topic" = "log__topic_",
"property.group.id" = "your_group_id",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="GSSAPI",
"property.sasl.kerberos.service.name"="kafka",
"property.sasl.kerberos.keytab"="/path/to/xxx.keytab",
"property.sasl.kerberos.principal"="<xxx@yyy.com>"
);
-- 查看 routine load 的状态
SHOW ROUTINE LOAD;
更多 Kafka 配置说明可参考 Routine Load。
3.5.4 使用自定义程序采集日志
除了对接常用日志采集器,也可以通过 HTTP API Stream Load 自定义程序导入日志:
curl
--location-trusted
-u username:password
-H "format:json"
-H "read_json_by_line:true"
-H "load_to_single_tablet:true"
-H "timeout:600"
-T logfile.json
http://fe_host:fe_http_port/api/log_db/log_table/_stream_load
使用自定义程序时需注意以下关键点:
- 使用 Basic Auth 进行 HTTP 鉴权,可用命令
echo -n 'username:password' | base64进行计算。 - 设置 HTTP Header
format:json,指定数据格式为 JSON。 - 设置 HTTP Header
read_json_by_line:true,指定每行一个 JSON。 - 设置 HTTP Header
load_to_single_tablet:true,指定一次导入写入一个分桶,减少导入小文件。 - 建议写入客户端单次 Batch 大小为 100 MB ~ 1 GB。如果使用 Apache Doris 2.1 及更高版本,可通过服务端 Group Commit 功能降低客户端 Batch 大小。
3.6 查询和分析日志
3.6.1 日志查询
Apache Doris 支持标准 SQL,可通过 MySQL 客户端或 JDBC 等方式连接到集群执行 SQL 查询:
mysql -h fe_host -P fe_mysql_port -u your_username -Dyour_db_name
下方列出常见的 5 条 SQL 查询命令以供参考:
-
查看最新的 10 条数据:
SELECT * FROM your_table_name ORDER BY ts DESC LIMIT 10; -
查询
host为8.8.8.8的最新 10 条数据:SELECT * FROM your_table_name WHERE host = '8.8.8.8' ORDER BY ts DESC LIMIT 10; -
检索
message字段中含error或404的最新 10 条数据。其中MATCH_ANY是 Apache Doris 全文检索的 SQL 语法,用于匹配参数中任一关键字:SELECT * FROM your_table_name WHERE message MATCH_ANY 'error 404'
ORDER BY ts DESC LIMIT 10; -
检索
message字段中含image和faq的最新 10 条数据。其中MATCH_ALL是 Apache Doris 全文检索的 SQL 语法,用于匹配参数中所有关键字:SELECT * FROM your_table_name WHERE message MATCH_ALL 'image faq'
ORDER BY ts DESC LIMIT 10; -
检索
message字段中含image和faq的最新 10 条数据。其中MATCH_PHRASE是 Apache Doris 全文检索的 SQL 语法,用于匹配参数中所有关键字且要求顺序一致。例如a image faq b能匹配,但a faq image b不能匹配:SELECT * FROM your_table_name WHERE message MATCH_PHRASE 'image faq'
ORDER BY ts DESC LIMIT 10;
3.6.2 可视化日志分析
一些第三方厂商提供了基于 Apache Doris 的可视化日志分析平台,包含类 Kibana Discover 的日志检索分析界面,提供直观、易用的探索式日志分析交互:
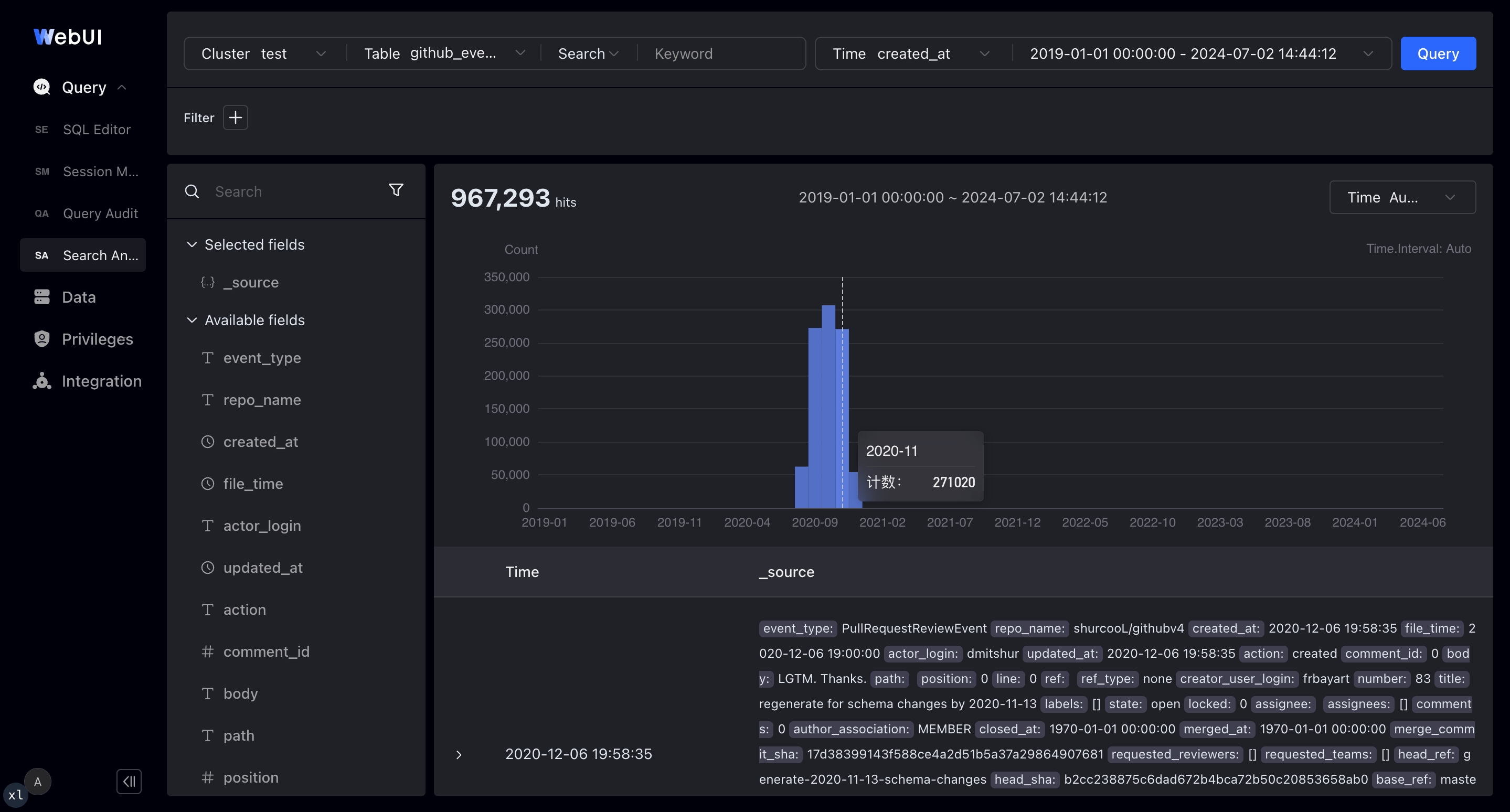
- 支持全文检索和 SQL 两种模式
- 支持时间框和直方图上选择查询日志的时间段
- 支持信息丰富的日志明细展示,可展开成 JSON 或表格
- 在日志数据上下文交互式点击增加和删除筛选条件
- 搜索结果的字段 Top 值展示,便于发现异常值并进一步下钻分析
如需更多帮助,可联系 dev@doris.apache.org。
4. 常见问题
Q1:Apache Doris 与 Elasticsearch 在日志场景下的核心差异是什么?
A:Doris 在写入吞吐上是 Elasticsearch 的 3~5 倍,存储成本只需 Elasticsearch 的 20% 左右;同时支持标准 SQL 与 MySQL 协议,分析能力更强;通过冷热分层可将冷数据下沉至 S3/HDFS,进一步降低存储成本。
Q2:日志字段经常变化,如何应对?
A:使用 Light Schema Change 在秒级完成顶层字段的 ADD/DROP COLUMN 与 ADD/DROP INDEX;对于动态嵌套字段使用 VARIANT 类型,自动识别字段名与类型,并可对 VARIANT 创建倒排索引。
Q3:分桶数应该如何选择?
A:建议分桶数大致为集群磁盘总数的 3 倍,每个桶压缩后数据量约 5 GB,并使用 DISTRIBUTED BY RANDOM 配合 Single Tablet 写入提升 Batch 写入效率。
Q4:冷热分层策略中的 cooldown_ttl 单位是什么?
A:单位为秒。例如 259200 表示 3 天,超过 3 天的数据将自动冷却至存储策略指定的对象存储位置。
Q5:写入端 Batch 大小如何选择?
A:建议单次 Batch 100 MB ~ 1 GB。Apache Doris 2.1 及更高版本可启用服务端 Group Commit 功能,从而在客户端使用更小的 Batch 大小。
5. 故障排查
| 现象 | 可能原因 | 处理建议 |
|---|---|---|
| 高并发导入报事务数超限 | max_running_txn_num_per_db 默认值偏小 | 调高 max_running_txn_num_per_db = 10000 |
| BE 频繁心跳超时 | 日志写入压力大,BE 短时间无响应 | 调大 max_backend_heartbeat_failure_tolerance_count = 10 |
| 写入产生大量小文件 / 随机 I/O | 写入缓冲区过小、未使用 Single Tablet 导入 | 调大 write_buffer_size = 1073741824,设置 load_to_single_tablet:true |
| Compaction 速度慢、影响写入 | Compaction 线程不足或低优先级调度限制 | 调整 max_cumu_compaction_threads 为 CPU 核数 / 4,关闭 enable_compaction_priority_scheduling |
| 索引内存占用过高 | 数据缓存与索引缓存竞争内存 | 关闭 disable_storage_page_cache,限制 inverted_index_searcher_cache_limit = 30% |
| 全文检索短语查询不生效 | 索引未开启 support_phrase | 创建索引时设置 "support_phrase" = "true" |
| 自动分桶数量过少导致热点 | autobucket_min_buckets 过小 | 调大 autobucket_min_buckets = 10 |