链路追踪与分析
本文介绍如何在 Apache Doris 中完成 Trace 数据的存储与分析实践,覆盖建表、采集与查询全链路。
快速导航
整体接入流程包含三个步骤,可按顺序完成:
| 步骤 | 内容 | 目标 |
|---|---|---|
| 1. 建表 | 在 Doris 中创建 Trace 存储表 | 针对 Trace 写入与查询模式优化性能 |
| 2. 采集 | 通过 OpenTelemetry 将 Trace 写入 Doris | 打通应用 → Collector → Doris 链路 |
| 3. 查询 | 在 Grafana 中可视化分析 Trace | 检索、查看延迟分布与链路详情 |
1. 建表
Trace 数据的写入和查询模式有明显特征,建表时进行针对性配置可获得更好的性能表现。
1.1 关键配置项说明
下表汇总了建表时的关键配置维度与推荐做法:
| 配置维度 | 推荐做法 | 说明 |
|---|---|---|
| 分区 | 时间字段上的 RANGE 分区,开启动态 Partition 按天自动管理 | 自动滚动分区,便于冷热分离与过期清理 |
| 排序键 | 使用 service_name 与 DATETIME 类型的时间字段作为 Key | 查询指定 service 一段时间的 Trace 时有数倍加速 |
| 分桶数 | 大致为集群磁盘总数的 3 倍 | 兼顾并行度与小文件控制 |
| 分桶策略 | 使用 RANDOM,配合写入时的 single tablet 导入 | 提升写入 batch 效果 |
| Compaction | 使用 time_series compaction 策略 | 减少写放大,对高吞吐 Trace 写入资源优化非常关键 |
| 半结构化字段 | span_attributes、resource_attributes 使用 VARIANT 类型 | 自动将 JSON 拆分为子列存储,提升压缩率与子列过滤分析性能 |
| 索引 | 对常用查询字段建倒排索引 | 加速等值过滤与范围查询 |
| 全文检索 | 指定分词器 parser 参数(一般 unicode 即可),按需开启 support_phrase | support_phrase 支持短语查询;不需要可关闭以降低存储空间 |
| 副本 | 云盘可配置 1 副本;物理盘至少配置 2 副本 | 平衡可靠性与成本 |
| 冷热分离 | 配置 log_s3 对象存储与 log_policy_3day 策略 | 超过 3 天的数据自动转存 S3,降低热存成本 |
1.2 建表 SQL 示例
下面的示例覆盖资源、存储策略与表的完整创建过程:
CREATE DATABASE log_db;
USE log_db;
-- 存算分离模式不需要
CREATE RESOURCE "log_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "your_endpoint_url",
"s3.region" = "your_region",
"s3.bucket" = "your_bucket",
"s3.root.path" = "your_path",
"s3.access_key" = "your_ak",
"s3.secret_key" = "your_sk"
);
-- 存算分离模式不需要
CREATE STORAGE POLICY log_policy_3day
PROPERTIES(
"storage_resource" = "log_s3",
"cooldown_ttl" = "259200"
);
CREATE TABLE trace_table
(
service_name VARCHAR(200),
timestamp DATETIME(6),
service_instance_id VARCHAR(200),
trace_id VARCHAR(200),
span_id STRING,
trace_state STRING,
parent_span_id STRING,
span_name STRING,
span_kind STRING,
end_time DATETIME(6),
duration BIGINT,
span_attributes VARIANT,
events ARRAY<STRUCT<timestamp:DATETIME(6), name:STRING, attributes:MAP<STRING, STRING>>>,
links ARRAY<STRUCT<trace_id:STRING, span_id:STRING, trace_state:STRING, attributes:MAP<STRING, STRING>>>,
status_message STRING,
status_code STRING,
resource_attributes VARIANT,
scope_name STRING,
scope_version STRING,
INDEX idx_timestamp(timestamp) USING INVERTED,
INDEX idx_service_instance_id(service_instance_id) USING INVERTED,
INDEX idx_trace_id(trace_id) USING INVERTED,
INDEX idx_span_id(span_id) USING INVERTED,
INDEX idx_trace_state(trace_state) USING INVERTED,
INDEX idx_parent_span_id(parent_span_id) USING INVERTED,
INDEX idx_span_name(span_name) USING INVERTED,
INDEX idx_span_kind(span_kind) USING INVERTED,
INDEX idx_end_time(end_time) USING INVERTED,
INDEX idx_duration(duration) USING INVERTED,
INDEX idx_span_attributes(span_attributes) USING INVERTED,
INDEX idx_status_message(status_message) USING INVERTED,
INDEX idx_status_code(status_code) USING INVERTED,
INDEX idx_resource_attributes(resource_attributes) USING INVERTED,
INDEX idx_scope_name(scope_name) USING INVERTED,
INDEX idx_scope_version(scope_version) USING INVERTED
)
ENGINE = OLAP
DUPLICATE KEY(service_name, timestamp)
PARTITION BY RANGE(timestamp) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"compression" = "zstd",
"compaction_policy" = "time_series",
"inverted_index_storage_format" = "V2",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250",
"dynamic_partition.replication_num" = "2", -- 存算分离不需要
"replication_num" = "2", -- 存算分离不需要
"storage_policy" = "log_policy_3day" -- 存算分离不需要
);
2. Trace 采集
Doris 提供开放通用的 Stream HTTP API,可与 OpenTelemetry 等 Trace 采集系统打通。
2.1 整体链路
应用 → OpenTelemetry SDK/Agent → OpenTelemetry Collector(含 Doris Exporter)→ Doris 表。
2.2 OpenTelemetry 对接步骤
步骤 1:应用侧接入 OpenTelemetry SDK
本示例使用 Spring Boot 官方 demo 接入 OpenTelemetry Java SDK,对路径 / 返回简单的 Hello World! 字符串。
下载 OpenTelemetry Java Agent,使用 Java Agent 的优势在于无需对现有应用做任何修改。
其他语言及接入方式参考:
步骤 2:部署并配置 OpenTelemetry Collector
下载 OpenTelemetry Collector 并解压。
需要下载以
otelcol-contrib为前缀的发行包,其中包含可将 Trace 数据导入 Doris 的 Doris Exporter 组件。
创建 otel_demo.yaml 配置文件如下,更多配置参考 Doris Exporter 文档:
receivers:
otlp: # otlp 协议,接收 OpenTelemetry Java Agent 发送的数据
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
send_batch_size: 100000 # 每个批次的数据条数,建议 batch 数据量在 100M-1G 之间
timeout: 10s
exporters:
doris:
endpoint: http://localhost:8030 # FE HTTP 地址
database: doris_db_name
username: doris_username
password: doris_password
table:
traces: doris_table_name
create_schema: true # 是否自动创建 schema,设置为 false 时需要手动建表
mysql_endpoint: localhost:9030 # FE MySQL 地址
history_days: 10
create_history_days: 10
timezone: Asia/Shanghai
timeout: 60s # http stream load 客户端超时时间
log_response: true
sending_queue:
enabled: true
num_consumers: 20
queue_size: 1000
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
headers:
load_to_single_tablet: "true"
步骤 3:运行 OpenTelemetry Collector
./otelcol-contrib --config otel_demo.yaml
步骤 4:启动 Spring Boot 示例应用
启动应用前只需添加几个环境变量,无需修改任何代码:
export JAVA_TOOL_OPTIONS="${JAVA_TOOL_OPTIONS} -javaagent:/your/path/to/opentelemetry-javaagent.jar" # OpenTelemetry Java Agent 的路径
export OTEL_JAVAAGENT_LOGGING="none" # 禁用 otel log,防止干扰服务本身的日志
export OTEL_SERVICE_NAME="myproject"
export OTEL_TRACES_EXPORTER="otlp" # 使用 otlp 协议发送 trace 数据
export OTEL_EXPORTER_OTLP_ENDPOINT="http://localhost:4317" # OpenTelemetry Collector 的地址
java -jar myproject-0.0.1-SNAPSHOT.jar
步骤 5:访问示例应用并产生 Trace 数据
执行 curl localhost:8080 触发 hello 服务调用,OpenTelemetry Java Agent 会自动生成 Trace 数据并发送给 OpenTelemetry Collector,Collector 再通过配置的 Doris Exporter 将 Trace 数据写入 Doris 的表中(默认表名为 otel.otel_traces)。
3. Trace 查询
Trace 查询通常通过可视化界面(如 Grafana)完成,常见场景包括:
-
通过时间段和服务名筛选,展示 Trace 概览,包括延迟分布图与最新的若干条 Trace。
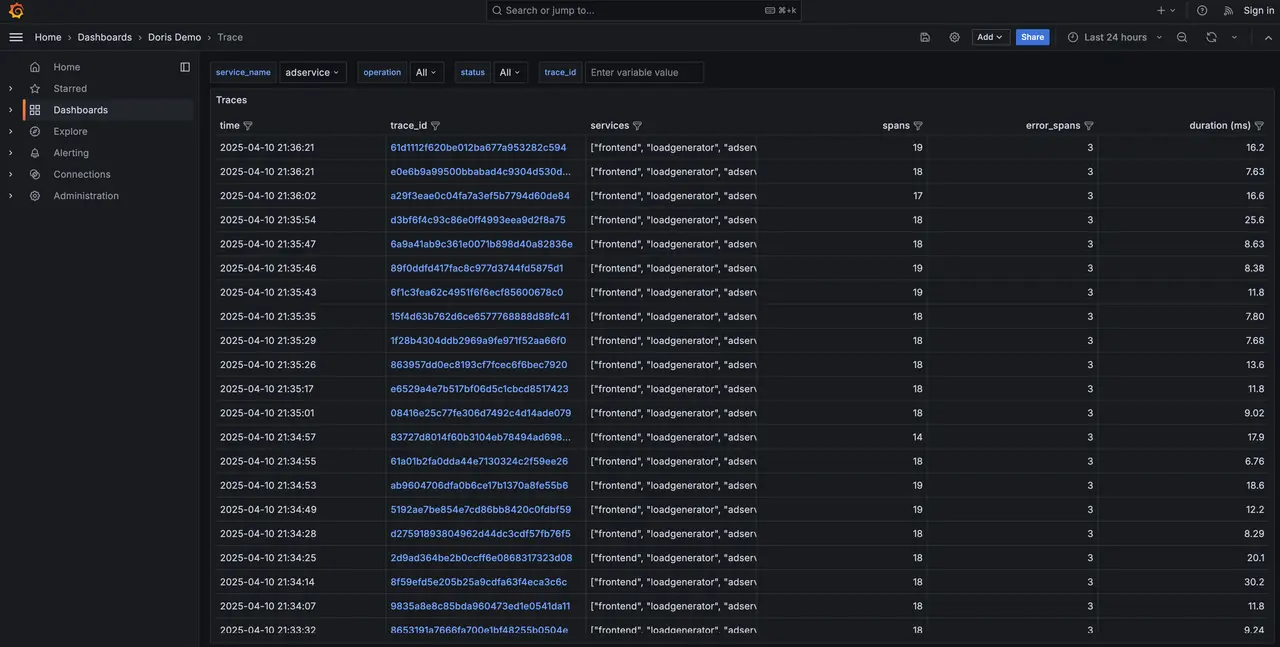
-
点击链接可查看 Trace 详情。