Colocation Join
Colocation Join 是 Doris 提供的一种 Join 优化能力:通过将多张表按相同规则共置(Colocate)到相同的 BE 节点上,使分桶列上的 Join 操作可在本地完成,避免跨节点数据传输,从而加速查询。
本文档主要介绍 Colocation Join 的原理、实现、使用方式和注意事项。
该属性不会被 CCR 同步。如果该表是被 CCR 复制而来的(即 PROPERTIES 中包含 is_being_synced = true),那么该属性会在该表中被擦除。
适用前提 Checklist
在使用 Colocation Join 前,请先确认:
- 两张及以上参与 Join 的表已加入同一个 Colocation Group。
- Join Key 与分桶列(Distribution Key)一致。
- 表的副本数与分桶数相同,且数据分布稳定(
IsStable = true)。 - 查询中存在明显的大表 Join 大表导致的 Shuffle 性能瓶颈。
名词解释
| 术语 | 缩写 | 说明 |
|---|---|---|
| Colocation Group | CG | 一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布。 |
| Colocation Group Schema | CGS | 用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息,包括分桶列类型、分桶数以及副本数等。 |
原理
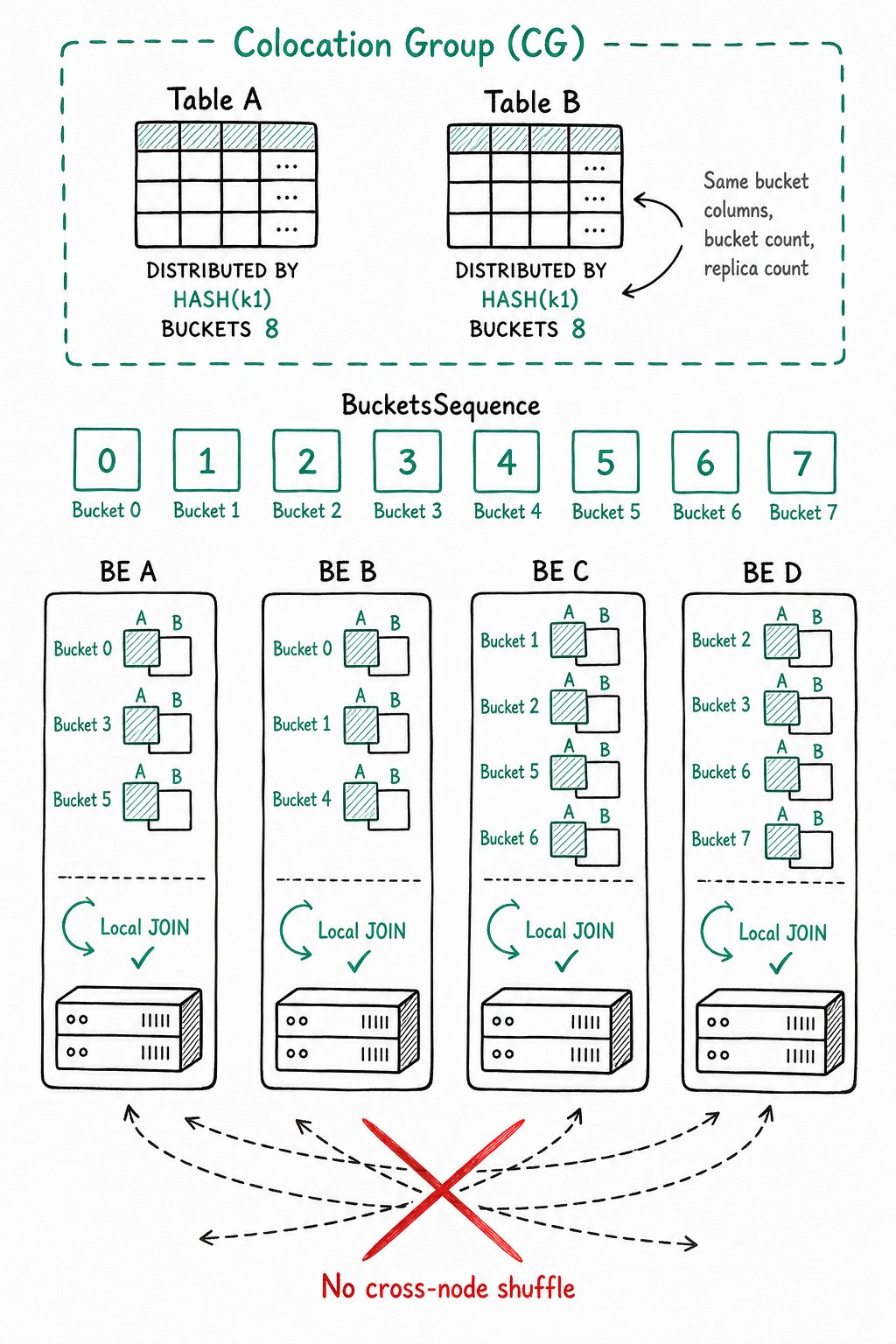
Colocation Join 功能将一组拥有相同 CGS 的 Table 组成一个 CG,并保证这些 Table 对应的数据分片会落在同一个 BE 节点上。这样,当 CG 内的表进行分桶列上的 Join 操作时,可直接进行本地数据 Join,减少数据在节点间的传输耗时。
分桶与 BucketsSequence
一个表的数据,最终会根据分桶列值 Hash、对桶数取模后落在某一个分桶内。假设一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket),我们称这样一个序列为一个 BucketsSequence。每个 Bucket 内会有一个或多个数据分片(Tablet):
- 当表为单分区表时,一个 Bucket 内仅有一个 Tablet。
- 如果是多分区表,则一个 Bucket 内会有多个 Tablet。
同一 CG 的约束条件
为了使得 Table 能够有相同的数据分布,同一 CG 内的 Table 必须保证以下属性相同:
-
分桶列和分桶数
分桶列即在建表语句中
DISTRIBUTED BY HASH(col1, col2, ...)中指定的列。分桶列决定了一张表的数据通过哪些列的值进行 Hash 划分到不同的 Tablet 中。同一 CG 内的 Table 必须保证分桶列的类型和数量完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应地进行分布控制。 -
副本数
同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
数据分布示意
在固定了分桶列和分桶数后,同一个 CG 内的表会拥有相同的 BucketsSequence。而副本数决定了每个分桶内的 Tablet 的多个副本,存放在哪些 BE 上。
假设 BucketsSequence 为 [0, 1, 2, 3, 4, 5, 6, 7],BE 节点有 [A, B, C, D] 4 个,则一个可能的数据分布如下:
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
| 0 | | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 |
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
| A | | B | | C | | D | | A | | B | | C | | D |
| | | | | | | | | | | | | | | |
| B | | C | | D | | A | | B | | C | | D | | A |
| | | | | | | | | | | | | | | |
| C | | D | | A | | B | | C | | D | | A | | B |
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
CG 内所有表的数据都会按照上面的规则进行统一分布,这样就保证了分桶列值相同的数据都在同一个 BE 节点上,可以进行本地数据 Join。
使用方式
建表时指定 Colocation Group
目的:将新建的表加入一个指定的 Colocation Group。
命令:在 PROPERTIES 中指定 "colocate_with" = "group_name"。
示例:
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
说明:
- 如果指定的 Group 不存在,则 Doris 会自动创建一个只包含当前这张表的 Group。
- 如果 Group 已存在,则 Doris 会检查当前表是否满足 Colocation Group Schema。如果满足,则会创建该表,并将该表加入 Group。同时,表会根据已存在的 Group 中的数据分布规则创建分片和副本。
- Group 归属于一个 Database,Group 的名字在一个 Database 内唯一。在内部存储时,Group 的全名为
dbId_groupName,但用户只感知groupName。
创建跨 Database 的 Global Group
2.0 版本中,Doris 支持了跨 Database 的 Group。
目的:实现跨 Database 的 Colocate Join。
命令:建表时使用关键词 __global__ 作为 Group 名称的前缀。
示例:
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "__global__group1"
);
说明:__global__ 前缀的 Group 不再归属于一个 Database,其名称也是全局唯一的。通过创建 Global Group,可以实现跨 Database 的 Colocate Join。
删表
当 Group 中最后一张表彻底删除后,该 Group 也会被自动删除。
彻底删除是指从回收站中删除。通常,一张表通过 DROP TABLE 命令删除后,会在回收站默认停留一天的时间后,再删除。
查看 Group
目的:查看集群内已存在的 Colocation Group 信息及数据分布。
1. 查看集群内全部 Group
SHOW PROC '/colocation_group';
+-------------+--------------+--------------+------------+----------------+----------+----------+
| GroupId | GroupName | TableIds | BucketsNum | ReplicationNum | DistCols | IsStable |
+-------------+--------------+--------------+------------+----------------+----------+----------+
| 10005.10008 | 10005_group1 | 10007, 10040 | 10 | 3 | int(11) | true |
+-------------+--------------+--------------+------------+----------------+----------+----------+
字段说明:
| 字段 | 说明 |
|---|---|
| GroupId | Group 的全集群唯一标识,前半部分为 db id,后半部分为 group id |
| GroupName | Group 的全名 |
| TableIds | 该 Group 包含的 Table 的 id 列表 |
| BucketsNum | 分桶数 |
| ReplicationNum | 副本数 |
| DistCols | Distribution columns,即分桶列类型 |
| IsStable | 该 Group 是否稳定(稳定的定义,见 Colocation 副本均衡和修复 一节) |
2. 查看某个 Group 的数据分布
SHOW PROC '/colocation_group/10005.10008';
+-------------+---------------------+
| BucketIndex | BackendIds |
+-------------+---------------------+
| 0 | 10004, 10002, 10001 |
| 1 | 10003, 10002, 10004 |
| 2 | 10002, 10004, 10001 |
| 3 | 10003, 10002, 10004 |
| 4 | 10002, 10004, 10003 |
| 5 | 10003, 10002, 10001 |
| 6 | 10003, 10004, 10001 |
| 7 | 10003, 10004, 10002 |
+-------------+---------------------+
字段说明:
| 字段 | 说明 |
|---|---|
| BucketIndex | 分桶序列的下标 |
| BackendIds | 分桶中数据分片所在的 BE 节点 id 列表 |
以上命令需要 ADMIN 权限,暂不支持普通用户查看。
修改表的 Colocate Group 属性
目的:将已创建的表加入、迁移或移出 Colocation Group。
1. 设置或迁移 Group
ALTER TABLE tbl SET ("colocate_with" = "group2");
行为说明:
- 如果该表之前没有指定过 Group,则该命令检查 Schema,并将该表加入到该 Group(Group 不存在则会创建)。
- 如果该表之前有指定其他 Group,则该命令会先将该表从原有 Group 中移除,并加入新 Group(Group 不存在则会创建)。
2. 删除 Colocation 属性
ALTER TABLE tbl SET ("colocate_with" = "");
其他相关操作
当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。
Colocation 副本均衡和修复
Colocation 表的副本分布需要遵循 Group 中指定的分布,所以在副本修复和均衡方面和普通分片有所区别。
Group 的 Stable 状态
Group 自身有一个 Stable 属性:
| 状态 | 含义 | 对查询的影响 |
|---|---|---|
| Stable(true) | 当前 Group 内的表的所有分片没有正在进行变动 | Colocation 特性可以正常使用 |
| Unstable(false) | 当前 Group 内有部分表的分片正在做修复或迁移 | 相关表的 Colocation Join 将退化为普通 Join |
副本修复
副本只能存储在指定的 BE 节点上。所以当某个 BE 不可用时(宕机、Decommission 等),需要寻找一个新的 BE 进行替换。Doris 会优先寻找负载最低的 BE 进行替换。替换后,该 Bucket 内的所有在旧 BE 上的数据分片都要做修复。迁移过程中,Group 被标记为 Unstable。
副本均衡
Doris 会尽力将 Colocation 表的分片均匀分布在所有 BE 节点上。两类均衡方式的区别如下:
| 类型 | 均衡粒度 | 说明 |
|---|---|---|
| 普通表 | 单副本 | 单独为每一个副本寻找负载较低的 BE 节点 |
| Colocation 表 | Bucket | 一个 Bucket 内的所有副本都会一起迁移 |
我们采用一个简单的均衡算法,即在不考虑副本实际大小,而只根据副本数量,将 BucketsSequence 均匀地分布在所有 BE 上。具体算法可以参阅 ColocateTableBalancer.java 中的代码注释。
- 注 1:当前的 Colocation 副本均衡和修复算法,对于异构部署的 Doris 集群效果可能不佳。所谓异构部署,即 BE 节点的磁盘容量、数量、磁盘类型(SSD 和 HDD)不一致。在异构部署情况下,可能出现小容量的 BE 节点和大容量的 BE 节点存储了相同的副本数量。
- 注 2:当一个 Group 处于 Unstable 状态时,其中的表的 Join 将退化为普通 Join。此时可能会极大降低集群的查询性能。如果不希望系统自动均衡,可以设置 FE 的配置项
disable_colocate_balance来禁止自动均衡,然后在合适的时间打开即可(具体参阅 高级操作 一节)。
查询
对 Colocation 表的查询方式和普通表一样,用户无需感知 Colocation 属性。如果 Colocation 表所在的 Group 处于 Unstable 状态,将自动退化为普通 Join。
下面通过一个示例说明如何确认 Colocation Join 是否生效。
示例建表
表 1:
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
表 2:
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
查看查询计划
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);
+----------------------------------------------------+
| Explain String |
+----------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:`tbl1`.`k1` | |
| PARTITION: RANDOM |
| |
| RESULT SINK |
| |
| 2:HASH JOIN |
| | join op: INNER JOIN |
| | hash predicates: |
| | colocate: true |
| | `tbl1`.`k2` = `tbl2`.`k2` |
| | tuple ids: 0 1 |
| | |
| |----1:OlapScanNode |
| | TABLE: tbl2 |
| | PREAGGREGATION: OFF. Reason: null |
| | partitions=0/1 |
| | rollup: null |
| | buckets=0/0 |
| | cardinality=-1 |
| | avgRowSize=0.0 |
| | numNodes=0 |
| | tuple ids: 1 |
| | |
| 0:OlapScanNode |
| TABLE: tbl1 |
| PREAGGREGATION: OFF. Reason: No AggregateInfo |
| partitions=0/2 |
| rollup: null |
| buckets=0/0 |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
+----------------------------------------------------+
如果 Colocation Join 生效,则 Hash Join 节点会显示 colocate: true。
如果没有生效,则查询计划如下:
+----------------------------------------------------+
| Explain String |
+----------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:`tbl1`.`k1` | |
| PARTITION: RANDOM |
| |
| RESULT SINK |
| |
| 2:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: group is not stable |
| | `tbl1`.`k2` = `tbl2`.`k2` |
| | tuple ids: 0 1 |
| | |
| |----3:EXCHANGE |
| | tuple ids: 1 |
| | |
| 0:OlapScanNode |
| TABLE: tbl1 |
| PREAGGREGATION: OFF. Reason: No AggregateInfo |
| partitions=0/2 |
| rollup: null |
| buckets=0/0 |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 03 |
| UNPARTITIONED |
| |
| 1:OlapScanNode |
| TABLE: tbl2 |
| PREAGGREGATION: OFF. Reason: null |
| partitions=0/1 |
| rollup: null |
| buckets=0/0 |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 1 |
+----------------------------------------------------+
HASH JOIN 节点会显示对应原因:colocate: false, reason: group is not stable,同时会有一个 EXCHANGE 节点生成。
Join 类型对比
为帮助判断当前查询是否走到 Colocation Join,下表对比了 Doris 中常见的几种 Join 类型:
| Join 类型 | 是否 Shuffle 数据 | 触发条件 |
|---|---|---|
| Colocate Join | 否 | 表加入同一 Colocate Group 且 IsStable=true |
| Bucket Shuffle Join | 部分(一侧) | Join Key 与左表分桶列一致 |
| Shuffle Join | 是(双侧) | 不满足上述条件时的默认行为 |
| Broadcast Join | 是(小表广播) | 右表数据量较小 |
高级操作
FE 配置项
| 配置项 | 默认值 | 说明 |
|---|---|---|
disable_colocate_relocate | false | 是否关闭 Doris 的自动 Colocation 副本修复。默认为 false,即不关闭。该参数只影响 Colocation 表的副本修复,不影响普通表。 |
disable_colocate_balance | false | 是否关闭 Doris 的自动 Colocation 副本均衡。默认为 false,即不关闭。该参数只影响 Colocation 表的副本均衡,不影响普通表。 |
disable_colocate_join | 见说明 | 是否关闭 Colocation Join 功能。在 0.10 及之前的版本,默认为 true,即关闭。在之后的某个版本中将默认为 false,即开启。 |
use_new_tablet_scheduler | 见说明 | 在 0.10 及之前的版本中,新的副本调度逻辑与 Colocation Join 功能不兼容,所以在 0.10 及之前版本,如果 disable_colocate_join = false,则需设置 use_new_tablet_scheduler = false,即关闭新的副本调度器。之后的版本中,use_new_tablet_scheduler 将恒为 true。 |
以上 disable_colocate_relocate 和 disable_colocate_balance 参数可以动态修改,设置方式请参阅 HELP SHOW CONFIG; 和 HELP SET CONFIG;。
HTTP Restful API
Doris 提供了几个和 Colocation Join 有关的 HTTP Restful API,用于查看和修改 Colocation Group。
该 API 实现在 FE 端,使用 fe_host:fe_http_port 进行访问,需要 ADMIN 权限。
1. 查看集群的全部 Colocation 信息
GET /api/colocate
返回以 Json 格式表示内部 Colocation 信息。
{
"msg": "success",
"code": 0,
"data": {
"infos": [
["10003.12002", "10003_group1", "10037, 10043", "1", "1", "int(11)", "true"]
],
"unstableGroupIds": [],
"allGroupIds": [{
"dbId": 10003,
"grpId": 12002
}]
},
"count": 0
}
2. 将 Group 标记为 Stable 或 Unstable
-
标记为 Stable
DELETE /api/colocate/group_stable?db_id=10005&group_id=10008
返回:200 -
标记为 Unstable
POST /api/colocate/group_stable?db_id=10005&group_id=10008
返回:200
3. 设置 Group 的数据分布
该接口可以强制设置某一 Group 的数据分布。
POST /api/colocate/bucketseq?db_id=10005&group_id=10008
Body:
[[10004,10002],[10003,10002],[10002,10004],[10003,10002],[10002,10004],[10003,10002],[10003,10004],[10003,10004],[10003,10004],[10002,10004]]
返回 200
其中 Body 是以嵌套数组表示的 BucketsSequence 以及每个 Bucket 中分片分布所在 BE 的 id。
使用该命令,可能需要将 FE 的配置 disable_colocate_relocate 和 disable_colocate_balance 设为 true,即关闭系统自动的 Colocation 副本修复和均衡,否则可能在修改后被系统自动重置。
常见问题
查询计划中出现 colocate: false, reason: group is not stable
说明 Group 当前处于 Unstable 状态,可能正在进行副本修复或均衡。此时 Join 会退化为普通 Join,待 Group 恢复 Stable 后即可重新使用 Colocation Join。可通过 SHOW PROC '/colocation_group'; 查看 IsStable 字段。
如何确认 Colocation Group 当前是否可用
执行 SHOW PROC "/colocation_group";,查看 IsStable 字段:true 表示可用,Join 可走 Colocate 计划;false 表示暂不可用,Doris 正在均衡数据。
IsStable=false 会持续多久
取决于数据迁移规模和集群负载,等待 Doris 完成 tablet 均衡后会自动恢复。如长期处于 false,可参考下文条目排查。
建表时报错:表无法加入指定 Group
请检查以下条件是否完全满足:
- 分桶列的类型与数量是否与 Group 中已有表完全一致;
- 分桶数(Buckets)是否一致;
- 所有分区的副本数是否一致。
任意一项不一致都会导致表无法加入 Group。
Group 长期处于 Unstable 状态
可能原因包括:
- 集群中存在 BE 宕机或 Decommission,仍在进行副本修复;
- 集群异构部署导致均衡难以收敛;
- 自动均衡未关闭,正在持续触发迁移。
可通过设置 disable_colocate_balance = true 暂时禁止自动均衡,待集群稳定后再恢复。
跨 Database 的两张表能否做 Colocation Join
可以。需要在 2.0 及以后版本,使用以 __global__ 为前缀的 Global Group 名称建表。
CCR 复制后 Colocation 属性是否保留
不保留。该属性不会被 CCR 同步,目标集群中表的 Colocation 属性会被擦除(当 PROPERTIES 中包含 is_being_synced = true 时)。