聚合模型
Doris 的聚合模型(Aggregate Key Model)专为高效处理大规模数据查询中的聚合操作而设计。通过在数据导入与后台合并阶段进行预聚合,减少重复计算,仅存储聚合后的结果,从而节省存储空间并加速查询。
适用场景
聚合模型适用于以下两类业务场景:
- 明细数据汇总:电商平台的月度销售业绩、金融风控的客户交易总额、广告投放的点击量等多维度汇总分析;
- 不依赖原始明细的查询:如驾驶舱报表、用户交易行为分析。原始明细数据保留在数据湖中,仓库内仅需存储汇总后的结果。
工作原理
每次数据导入会在聚合模型中形成一个新版本,后台 Compaction 阶段进行版本合并,查询时按主键再次聚合。整体流程分为三个阶段:
- 数据导入阶段:数据按批次导入,每批次生成一个版本,并对相同聚合键的数据进行初步聚合(如求和、计数);
- 后台合并阶段(Compaction):多个版本文件定期合并,减少冗余并优化存储;
- 查询阶段:系统按聚合键对数据进行最终聚合,确保查询结果准确。
建表语法
使用 AGGREGATE KEY 关键字指定聚合模型,并声明 Key 列用于聚合 Value 列。
CREATE TABLE IF NOT EXISTS example_tbl_agg
(
user_id LARGEINT NOT NULL,
load_date DATE NOT NULL,
city VARCHAR(20),
last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",
cost BIGINT SUM DEFAULT "0",
max_dwell INT MAX DEFAULT "0"
)
AGGREGATE KEY(user_id, load_date, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
上例定义了用户信息与访问行为表,将 user_id、load_date 与 city 作为 Key 列进行聚合。数据导入时,相同 Key 列的行会被聚合为一行,Value 列按声明的聚合类型进行维度聚合。
支持的聚合方式
聚合表的 Value 列支持以下聚合方式:
| 聚合方式 | 描述 |
|---|---|
| SUM | 求和,多行 Value 累加。 |
| REPLACE | 替代,下一批数据中的 Value 替换之前导入行中的 Value。 |
| MAX | 保留最大值。 |
| MIN | 保留最小值。 |
| REPLACE_IF_NOT_NULL | 非空值替换。与 REPLACE 的区别在于不替换 null 值。 |
| HLL_UNION | 用于 HLL 类型列,通过 HyperLogLog 算法聚合。 |
| BITMAP_UNION | 用于 BITMAP 类型列,进行位图的并集聚合。 |
若以上聚合方式无法满足业务需求,可使用 AGG_STATE 类型。
数据写入与聚合示例
聚合表中的数据基于 Key 列进行聚合,写入完成后即完成聚合操作。
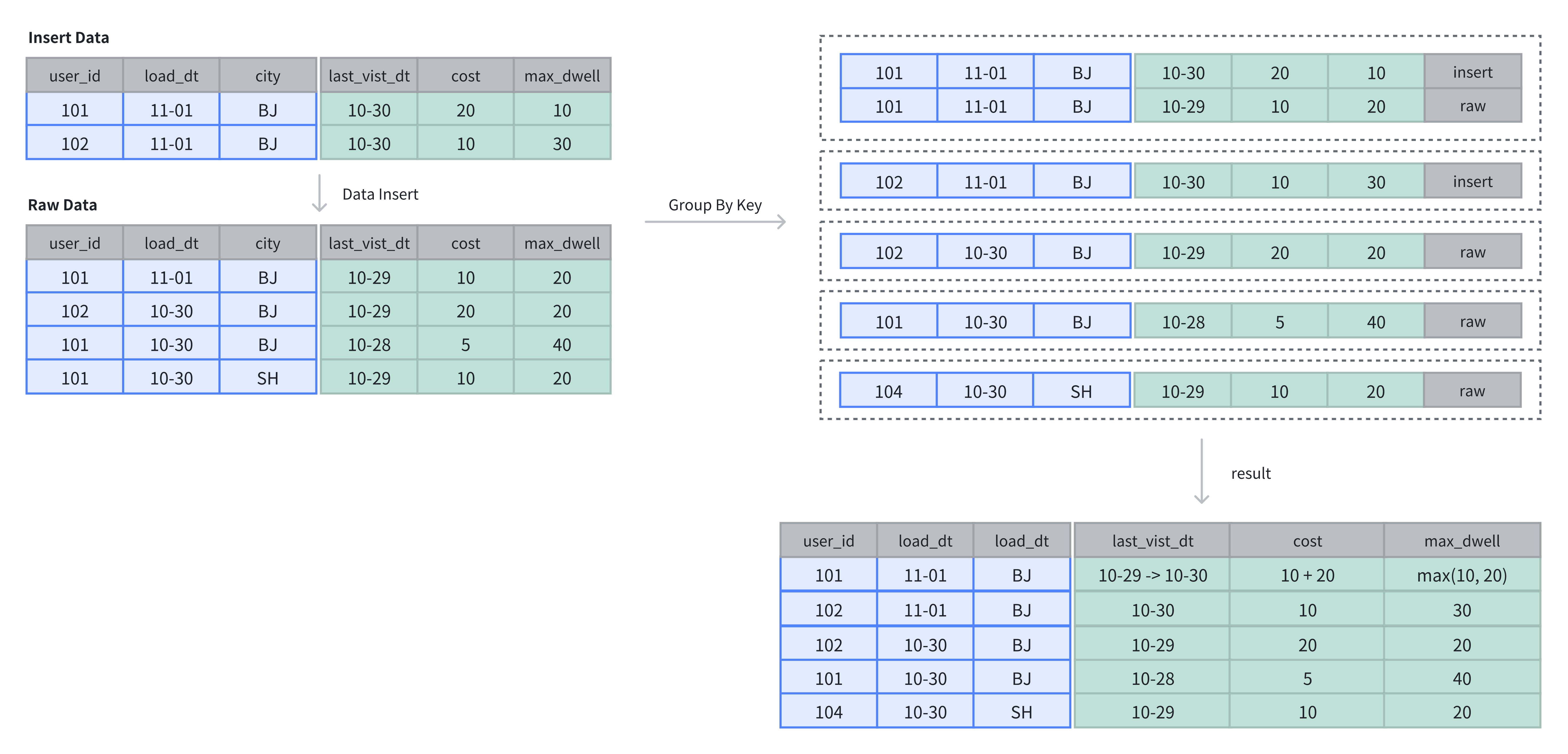
如下示例:表中原有 4 行数据,再插入 2 行数据后,基于 Key 列进行 Value 列的聚合。
-- 4 rows raw data
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-29', 10, 20),
(102, '2024-10-30', 'BJ', '2024-10-29', 20, 20),
(101, '2024-10-30', 'BJ', '2024-10-28', 5, 40),
(101, '2024-10-30', 'SH', '2024-10-29', 10, 20);
-- insert into 2 rows
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-30', 20, 10),
(102, '2024-11-01', 'BJ', '2024-10-30', 10, 30);
-- check the rows of table
SELECT * FROM example_tbl_agg;
+---------+------------+------+---------------------+------+----------------+
| user_id | load_date | city | last_visit_dt | cost | max_dwell |
+---------+------------+------+---------------------+------+----------------+
| 102 | 2024-10-30 | BJ | 2024-10-29 00:00:00 | 20 | 20 |
| 102 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 10 | 30 |
| 101 | 2024-10-30 | BJ | 2024-10-28 00:00:00 | 5 | 40 |
| 101 | 2024-10-30 | SH | 2024-10-29 00:00:00 | 10 | 20 |
| 101 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 30 | 20 |
+---------+------------+------+---------------------+------+----------------+
AGG_STATE
AGG_STATE 为实验特性,建议在开发与测试环境中使用。
AGG_STATE 适用于内置聚合方式无法满足需求的场景,使用时需要注意以下约束:
- 不能作为 Key 列使用;
- 建表时必须声明聚合函数的签名;
- 无需指定长度和默认值,实际存储大小与函数实现有关。
建表示例
set enable_agg_state = true;
CREATE TABLE aggstate
(
k1 INT NULL,
v1 INT SUM,
v2 agg_state<group_concat(string)> generic
)
AGGREGATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 3;
上例中,agg_state 用于声明数据类型,sum / group_concat 为聚合函数签名。agg_state 是一种数据类型(类似 int、array、string),仅可与 state、merge、union 三个函数组合器配合使用,用于表示聚合函数的中间结果(例如 group_concat 的中间状态),而非最终结果。
写入:使用 state 生成中间结果
agg_state 类型的数据需要通过 state 函数生成,本表对应使用 group_concat_state:
INSERT INTO aggstate VALUES (1, 1, group_concat_state('a'));
INSERT INTO aggstate VALUES (1, 2, group_concat_state('b'));
INSERT INTO aggstate VALUES (1, 3, group_concat_state('c'));
INSERT INTO aggstate VALUES (2, 4, group_concat_state('d'));
此时表内计算方式如下图所示:

查询:使用 merge 返回最终结果
查询时,可使用 merge 操作合并多个 state,返回最终聚合结果。由于 group_concat 对顺序有要求,结果是不稳定的:
SELECT group_concat_merge(v2) FROM aggstate;
+------------------------+
| group_concat_merge(v2) |
+------------------------+
| d,c,b,a |
+------------------------+
中间结果保留:使用 union 操作
如果不需要最终聚合结果,而希望保留中间结果,可使用 union 操作:
INSERT INTO aggstate
SELECT 3, sum(v1), group_concat_union(v2) FROM aggstate;
此时表内计算方式如下图所示:

由于 group_concat 对顺序有要求,结果是不稳定的,结果可能为:
mysql> SELECT sum(v1), group_concat_merge(v2) FROM aggstate;
+---------+------------------------+
| sum(v1) | group_concat_merge(v2) |
+---------+------------------------+
| 20 | c,b,a,d,c,b,a,d |
+---------+------------------------+
mysql> SELECT sum(v1), group_concat_merge(v2) FROM aggstate WHERE k1 != 2;
+---------+------------------------+
| sum(v1) | group_concat_merge(v2) |
+---------+------------------------+
| 16 | c,b,a,d,c,b,a |
+---------+------------------------+