Using Doris and Paimon
As a new open data management architecture, the Data Lakehouse integrates the high performance and real-time capabilities of data warehouses with the low cost and flexibility of data lakes, helping users more conveniently meet various data processing and analysis needs. It has been increasingly applied in enterprise big data systems.
In recent versions, Apache Doris has deepened its integration with data lakes and has evolved a mature Data Lakehouse solution.
- Since version 0.15, Apache Doris has introduced Hive and Iceberg external tables, exploring the capabilities of combining with Apache Iceberg for data lakes.
- Starting from version 1.2, Apache Doris officially introduced the Multi-Catalog feature, achieving automatic metadata mapping and data access for various data sources, along with many performance optimizations for external data reading and query execution. It now fully possesses the ability to build a high-speed and user-friendly Lakehouse architecture.
- In version 2.1, Apache Doris' Data Lakehouse architecture was significantly enhanced, strengthening the reading and writing capabilities of mainstream data lake formats (Hudi, Iceberg, Paimon, etc.), introducing compatibility with multiple SQL dialects, and seamless migration from existing systems to Apache Doris. For data science and large-scale data reading scenarios, Doris integrated the Arrow Flight high-speed reading interface, achieving a 100-fold improvement in data transfer efficiency.
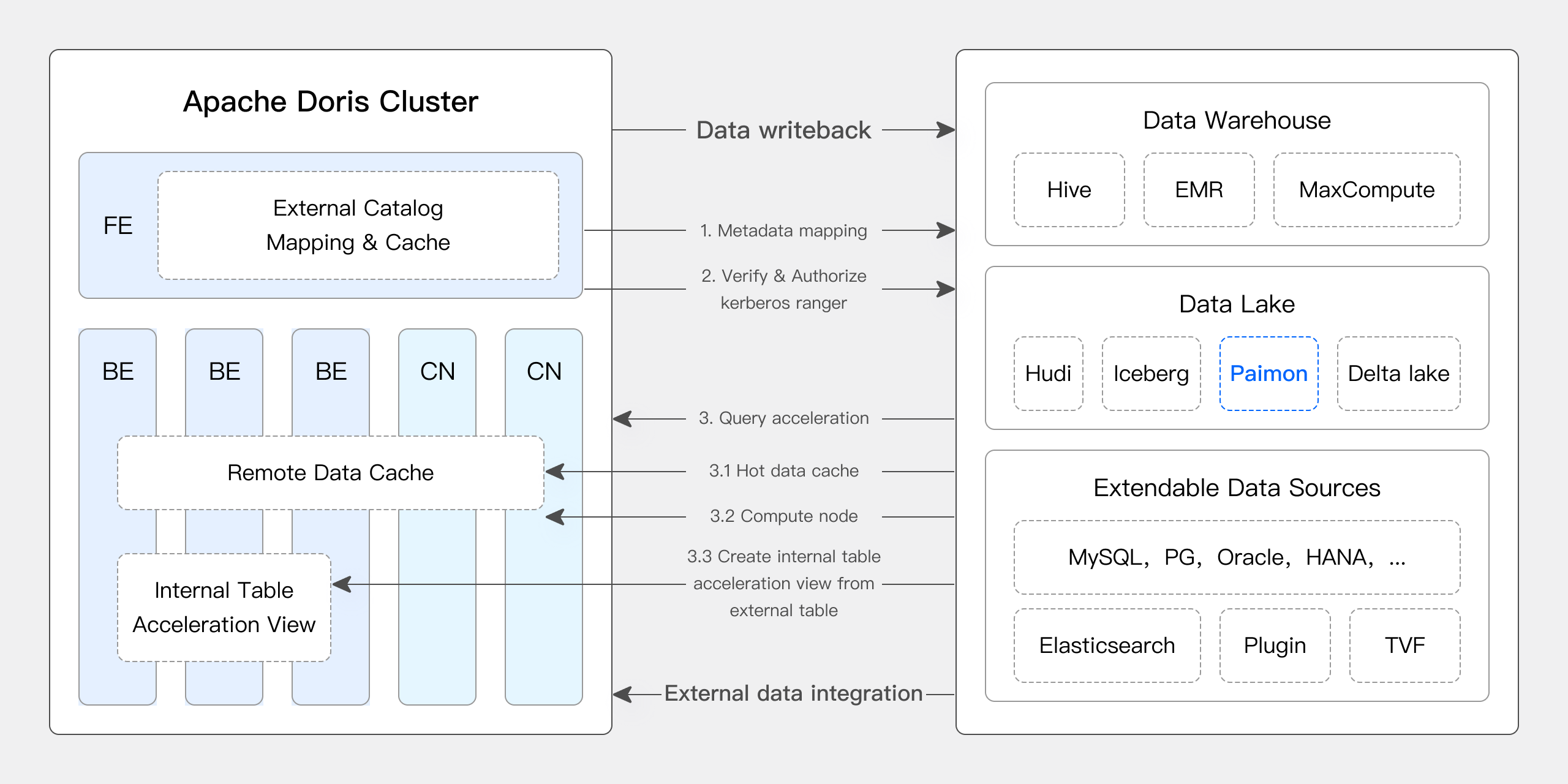
Apache Doris & Paimon
Apache Paimon is a data lake format that innovatively combines the advantages of data lake formats and LSM structures, successfully introducing efficient real-time streaming update capabilities into data lake architecture. This enables Paimon to efficiently manage data and perform real-time analysis, providing strong support for building real-time Data Lakehouse architecture.
To fully leverage Paimon's capabilities and improve query efficiency for Paimon data, Apache Doris provides native support for several of Paimon's latest features:
- Supports various types of Paimon Catalogs such as Hive Metastore and FileSystem.
- Native support for Paimon 0.6's Primary Key Table Read Optimized feature.
- Native support for Paimon 0.8's Primary Key Table Deletion Vector feature.
With Apache Doris' high-performance query engine and Apache Paimon's efficient real-time streaming update capabilities, users can achieve:
- Real-time data ingestion into the lake: Leveraging Paimon's LSM-Tree model, data ingestion into the lake can be reduced to a minute-level timeliness. Additionally, Paimon supports various data update capabilities including aggregation, deduplication, and partial column updates, making data flow more flexible and efficient.
- High-performance data processing and analysis: Paimon's technologies such as Append Only Table, Read Optimized, and Deletion Vector can be seamlessly integrated with Doris' powerful query engine, enabling fast querying and analysis responses for lake data.
In the future, Apache Doris will gradually support more advanced features of Apache Paimon, including Time Travel and incremental data reading, to jointly build a unified, high-performance, real-time lakehouse platform.
This article will explain how to quickly set up an Apache Doris + Apache Paimon testing & demonstration environment in a Docker environment and demonstrate the usage of various features.
For more information, please refer to Paimon Catalog
User Guide
All scripts and code mentioned in this article can be obtained from the following address: https://github.com/apache/doris/tree/master/samples/datalake/iceberg_and_paimon
01 Environment Preparation
This article uses Docker Compose for deployment, with the following components and versions:
| Component | Version |
|---|---|
| Apache Doris | Default 2.1.5, can be modified |
| Apache Paimon | 0.8 |
| Apache Flink | 1.18 |
| MinIO | RELEASE.2024-04-29T09-56-05Z |
02 Environment Deployment
Start all components
bash ./start_all.shAfter starting, you can use the following scripts to log in to the Flink command line or Doris command line:
-- login flink
bash ./start_flink_client.sh
-- login doris
bash ./start_doris_client.sh
03 Data Preparation
After logging into the Flink command line, you can see a pre-built table. The table already contains some data that can be viewed using Flink SQL.
Flink SQL> use paimon.db_paimon;
[INFO] Execute statement succeed.
Flink SQL> show tables;
+------------+
| table name |
+------------+
| customer |
+------------+
1 row in set
Flink SQL> show create table customer;
+------------------------------------------------------------------------+
| result |
+------------------------------------------------------------------------+
| CREATE TABLE `paimon`.`db_paimon`.`customer` (
`c_custkey` INT NOT NULL,
`c_name` VARCHAR(25),
`c_address` VARCHAR(40),
`c_nationkey` INT NOT NULL,
`c_phone` CHAR(15),
`c_acctbal` DECIMAL(12, 2),
`c_mktsegment` CHAR(10),
`c_comment` VARCHAR(117),
CONSTRAINT `PK_c_custkey_c_nationkey` PRIMARY KEY (`c_custkey`, `c_nationkey`) NOT ENFORCED
) PARTITIONED BY (`c_nationkey`)
WITH (
'bucket' = '1',
'path' = 's3://warehouse/wh/db_paimon.db/customer',
'deletion-vectors.enabled' = 'true'
)
|
+-------------------------------------------------------------------------+
1 row in set
Flink SQL> desc customer;
+--------------+----------------+-------+-----------------------------+--------+-----------+
| name | type | null | key | extras | watermark |
+--------------+----------------+-------+-----------------------------+--------+-----------+
| c_custkey | INT | FALSE | PRI(c_custkey, c_nationkey) | | |
| c_name | VARCHAR(25) | TRUE | | | |
| c_address | VARCHAR(40) | TRUE | | | |
| c_nationkey | INT | FALSE | PRI(c_custkey, c_nationkey) | | |
| c_phone | CHAR(15) | TRUE | | | |
| c_acctbal | DECIMAL(12, 2) | TRUE | | | |
| c_mktsegment | CHAR(10) | TRUE | | | |
| c_comment | VARCHAR(117) | TRUE | | | |
+--------------+----------------+-------+-----------------------------+--------+-----------+
8 rows in set
Flink SQL> select * from customer order by c_custkey limit 4;
+-----------+--------------------+--------------------------------+-------------+-----------------+-----------+--------------+--------------------------------+
| c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment |
+-----------+--------------------+--------------------------------+-------------+-----------------+-----------+--------------+--------------------------------+
| 1 | Customer#000000001 | IVhzIApeRb ot,c,E | 15 | 25-989-741-2988 | 711.56 | BUILDING | to the even, regular platel... |
| 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tEgvwfmRchLXak | 13 | 23-768-687-3665 | 121.65 | AUTOMOBILE | l accounts. blithely ironic... |
| 3 | Customer#000000003 | MG9kdTD2WBHm | 1 | 11-719-748-3364 | 7498.12 | AUTOMOBILE | deposits eat slyly ironic,... |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tl... | 15 | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious ... |
+-----------+--------------------+--------------------------------+-------------+-----------------+-----------+--------------+--------------------------------+
4 rows in set
04 Data Query
As shown below, a Catalog named paimon has been created in the Doris cluster (can be viewed using SHOW CATALOGS). The following is the statement for creating this Catalog:
-- 已创建,无需执行
CREATE CATALOG `paimon` PROPERTIES (
"type" = "paimon",
"warehouse" = "s3://warehouse/wh/",
"s3.endpoint"="http://minio:9000",
"s3.access_key"="admin",
"s3.secret_key"="password",
"s3.region"="us-east-1"
);
You can query Paimon's data in Doris:
mysql> use paimon.db_paimon;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------+
| Tables_in_db_paimon |
+---------------------+
| customer |
+---------------------+
1 row in set (0.00 sec)
mysql> select * from customer order by c_custkey limit 4;
+-----------+--------------------+---------------------------------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment |
+-----------+--------------------+---------------------------------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| 1 | Customer#000000001 | IVhzIApeRb ot,c,E | 15 | 25-989-741-2988 | 711.56 | BUILDING | to the even, regular platelets. regular, ironic epitaphs nag e |
| 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tEgvwfmRchLXak | 13 | 23-768-687-3665 | 121.65 | AUTOMOBILE | l accounts. blithely ironic theodolites integrate boldly: caref |
| 3 | Customer#000000003 | MG9kdTD2WBHm | 1 | 11-719-748-3364 | 7498.12 | AUTOMOBILE | deposits eat slyly ironic, even instructions. express foxes detect slyly. blithely even accounts abov |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 15 | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e |
+-----------+--------------------+---------------------------------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
4 rows in set (1.89 sec)
05 Read Incremental Data
You can update the data in the Paimon table using Flink SQL:
Flink SQL> update customer set c_address='c_address_update' where c_nationkey = 1;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: ff838b7b778a94396b332b0d93c8f7ac
After the Flink SQL execution is complete, you can directly view the latest data in Doris:
mysql> select * from customer where c_nationkey=1 limit 2;
+-----------+--------------------+-----------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment |
+-----------+--------------------+-----------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| 3 | Customer#000000003 | c_address_update | 1 | 11-719-748-3364 | 7498.12 | AUTOMOBILE | deposits eat slyly ironic, even instructions. express foxes detect slyly. blithely even accounts abov |
| 513 | Customer#000000513 | c_address_update | 1 | 11-861-303-6887 | 955.37 | HOUSEHOLD | press along the quickly regular instructions. regular requests against the carefully ironic s |
+-----------+--------------------+-----------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
2 rows in set (0.19 sec)
Benchmark
We conducted a simple test on the TPCDS 1000 dataset in Paimon (0.8) version, using Apache Doris 2.1.5 version and Trino 422 version, both with the Primary Key Table Read Optimized feature enabled.
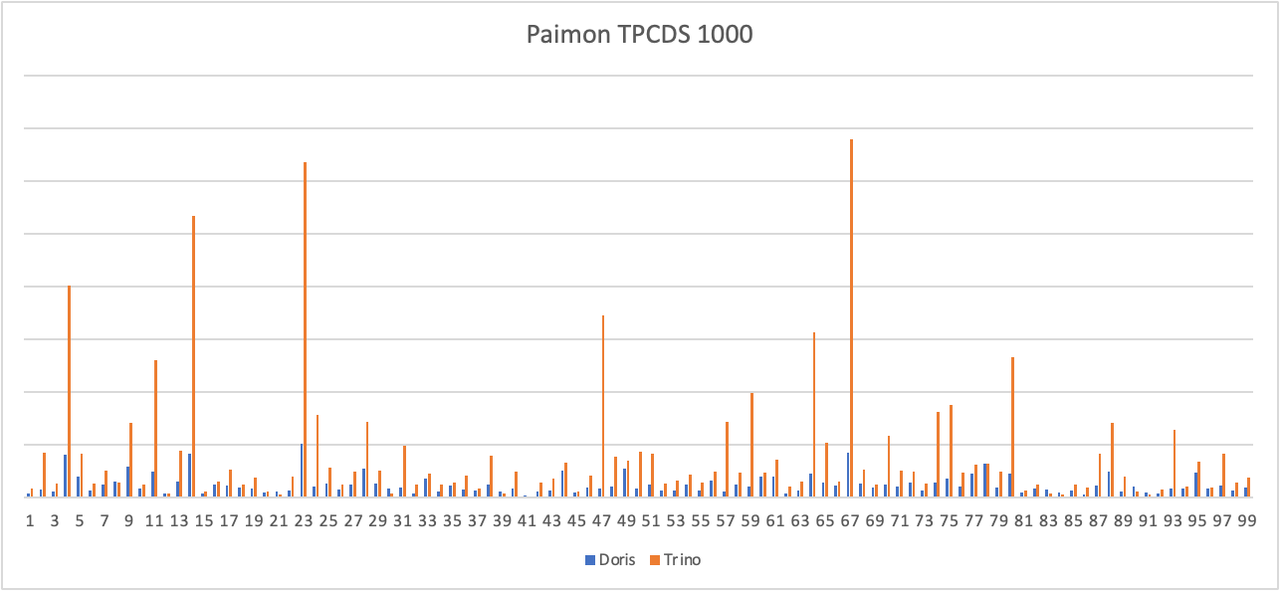
From the test results, it can be seen that Doris' average query performance on the standard static test set is 3-5 times that of Trino. In the future, we will optimize the Deletion Vector to further improve query efficiency in real business scenarios.
Query Optimization
For baseline data, after introducing the Primary Key Table Read Optimized feature in Apache Paimon version 0.6, the query engine can directly access the underlying Parquet/ORC files, significantly improving the reading efficiency of baseline data. For unmerged incremental data (data increments generated by INSERT, UPDATE, or DELETE), they can be read through Merge-on-Read. In addition, Paimon introduced the Deletion Vector feature in version 0.8, which further enhances the query engine's efficiency in reading incremental data. Apache Doris supports reading Deletion Vector through native Reader and performing Merge on Read. We demonstrate the query methods for baseline data and incremental data in a query using Doris' EXPLAIN statement.
mysql> explain verbose select * from customer where c_nationkey < 3;
+------------------------------------------------------------------------------------------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------------------------------------------------------------------------------------------+
| ............... |
| |
| 0:VPAIMON_SCAN_NODE(68) |
| table: customer |
| predicates: (c_nationkey[#3] < 3) |
| inputSplitNum=4, totalFileSize=238324, scanRanges=4 |
| partition=3/0 |
| backends: |
| 10002 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=1/bucket-0/data-15cee5b7-1bd7-42ca-9314-56d92c62c03b-0.orc start: 0 length: 66600 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=1/bucket-0/data-5d50255a-2215-4010-b976-d5dc656f3444-0.orc start: 0 length: 44501 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=2/bucket-0/data-e98fb7ef-ec2b-4ad5-a496-713cb9481d56-0.orc start: 0 length: 64059 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=0/bucket-0/data-431be05d-50fa-401f-9680-d646757d0f95-0.orc start: 0 length: 63164 |
| cardinality=18751, numNodes=1 |
| pushdown agg=NONE |
| paimonNativeReadSplits=4/4 |
| PaimonSplitStats: |
| SplitStat [type=NATIVE, rowCount=1542, rawFileConvertable=true, hasDeletionVector=true] |
| SplitStat [type=NATIVE, rowCount=750, rawFileConvertable=true, hasDeletionVector=false] |
| SplitStat [type=NATIVE, rowCount=750, rawFileConvertable=true, hasDeletionVector=false] |
| tuple ids: 0
| ............... | |
+------------------------------------------------------------------------------------------------------------------------------------------------+
67 rows in set (0.23 sec)
It can be seen that the table just updated by Flink SQL contains 4 shards, and all shards can be accessed through Native Reader (paimonNativeReadSplits=4/4). In addition, the hasDeletionVector property of the first shard is true, indicating that the shard has a corresponding Deletion Vector, and data will be filtered according to the Deletion Vector when reading.
